







Spark的持久化级别
| 持久化级别 | 含义解释 |
| MEMORY_ONLY | 使用未序列化的Java对象格式,将数据保存在内存中。如果内存不够存放所有的数据,则数据可能就不会进行持久化。那么下次对这个RDD执行算子操作时,那些没有被持久化的数据,需要从源头处重新计算一遍。这是默认的持久化策略,使用cache()方法时,实际就是使用的这种持久化策略。 |
| MEMORY_AND_DISK | 使用未序列化的Java对象格式,优先尝试将数据保存在内存中。如果内存不够存放所有的数据,会将数据写入磁盘文件中,下次对这个RDD执行算子时,持久化在磁盘文件中的数据会被读取出来使用。 |
| MEMORY_ONLY_SER | 基本含义同MEMORY_ONLY。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。 |
| MEMORY_AND_DISK_SER | 基本含义同MEMORY_AND_DISK。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。 |
| DISK_ONLY | 使用未序列化的Java对象格式,将数据全部写入磁盘文件中。 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, 等等. | 对于上述任意一种持久化策略,如果加上后缀_2,代表的是将每个持久化的数据,都复制一份副本,并将副本保存到其他节点上。这种基于副本的持久化机制主要用于进行容错。假如某个节点挂掉,节点的内存或磁盘中的持久化数据丢失了,那么后续对RDD计算时还可以使用该数据在其他节点上的副本。如果没有副本的话,就只能将这些数据从源头处重新计算一遍了。 |
如何选择一种最合适的持久化策略
(1)默认情况下,性能最高的当然是MEMORY_ONLY,但前提是你的内存必须足够足够大,可以绰绰有余地存放下整个RDD的所有数据。因为不进行序列化与反序列化操作,就避免了这部分的性能开销;对这个RDD的后续算子操作,都是基于纯内存中的数据的操作,不需要从磁盘文件中读取数据,性能也很高;而且不需要复制一份数据副本,并远程传送到其他节点上。但是这里必须要注意的是,在实际的生产环境中,恐怕能够直接用这种策略的场景还是有限的,如果RDD中数据比较多时(比如几十亿),直接用这种持久化级别,会导致JVM的OOM内存溢出异常。
(2)如果使用MEMORY_ONLY级别时发生了内存溢出,那么建议尝试使用MEMORY_ONLY_SER级别。该级别会将RDD数据序列化后再保存在内存中,此时每个partition仅仅是一个字节数组而已,大大减少了对象数量,并降低了内存占用。这种级别比MEMORY_ONLY多出来的性能开销,主要就是序列化与反序列化的开销。但是后续算子可以基于纯内存进行操作,因此性能总体还是比较高的。此外,可能发生的问题同上,如果RDD中的数据量过多的话,还是可能会导致OOM内存溢出的异常。
(3)如果纯内存的级别都无法使用,那么建议使用MEMORY_AND_DISK_SER策略,而不是MEMORY_AND_DISK策略。因为既然到了这一步,就说明RDD的数据量很大,内存无法完全放下。序列化后的数据比较少,可以节省内存和磁盘的空间开销。同时该策略会优先尽量尝试将数据缓存在内存中,内存缓存不下才会写入磁盘。
(3)通常不建议使用DISK_ONLY和后缀为_2的级别:因为完全基于磁盘文件进行数据的读写,会导致性能急剧降低,有时还不如重新计算一次所有RDD。后缀为_2的级别,必须将所有数据都复制一份副本,并发送到其他节点上,数据复制以及网络传输会导致较大的性能开销,除非是要求作业的高可用性,否则不建议使用。
持久化的操作
Spark-shell
进入spark的操作界面是在本地运行
Spark-shell --maser +master的地址
进入spark的操作界面是在spark的集群上运行
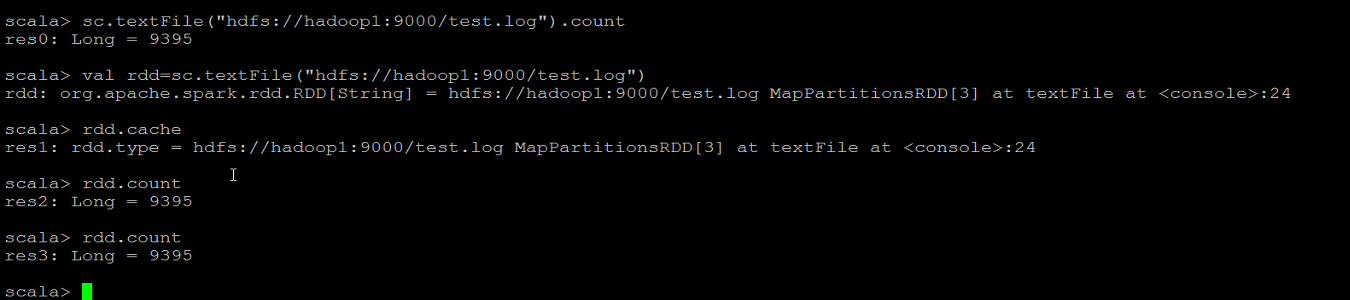
(1)rdd.cache 将rdd放入缓存,但是cache是transformation的操作,这句代码并没有真正的执行,并没有将rdd放入到缓存
(2)Rdd.count 触发上句代码的执行,count是action的操作,会将代码真正执行,也触发了上句代码的执行,将rdd放入到缓存中
(3)Rdd.count 运行放入内存中的rdd,这样代码运行的效率会比上次代码运行的效率快
persist(StorageLevel.MEMORY_ONLY) = cache
CheckPoint
sc.setCheckpointDir(“hdfs://hadoop01:9000/checkPointTest”)
设置检查点的目录:
将当前的数据和目录存入当某个磁盘中去,下次使用的时候到这个目录中去取数据就可以了
Val rdd = sc.textFile(“hdfs://hadoop01:9000/test.log”).filter(.contains(hadoop”))
这个rdd非常的来着不易,可以将这个rdd去checkpoint起来:
rdd.checkpoint
当上述的rdd发生action的操作的时候就会将rdd存入到检查点的目录里面。(将rdd文件存储在磁盘上面)
checkPoint(disk)和persist(disk_only)的区别
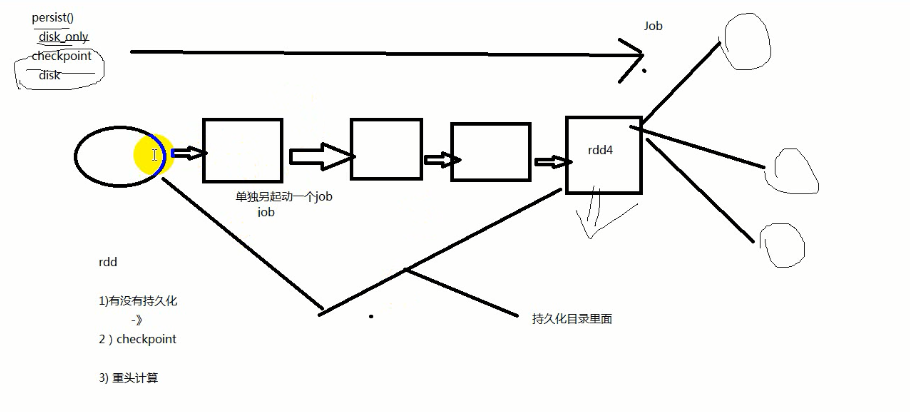
当rdd设置了checkpoint了,rdd的获取会开启两个线程(job),一个是用于获得rdd的数据去计算,一个是用于获得rdd的数据存入到checkpoint的检查目录里面。
从这里看,persist更有效,checkpoint更适合在sparkstreaming中去使用
checkPoint(disk):数据存储在hdfs上面的,有备份,当项目停止了的之后,数据不会清空,还保存在hdfs上面
persist(disk_only):是存储在本台服务器上面的,他没有副本。这个任务运行完了,数据就会清空了
Rdd数据查找
(1)有没有数据持久化 persist
(2)有没有checkpoint
(3)从头计算















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









