







 这篇博客介绍了一个Python脚本,用于从纳米漫画网下载漫画。文章详细阐述了脚本的四个步骤:解析漫画章节列表、解析获取漫画图片、下载漫画图片到本地以及查找漫画。脚本依赖于Python的os、sys、string、getopt、lxml和requests等库,适用于熟悉Python、XPath和HTML的读者。
这篇博客介绍了一个Python脚本,用于从纳米漫画网下载漫画。文章详细阐述了脚本的四个步骤:解析漫画章节列表、解析获取漫画图片、下载漫画图片到本地以及查找漫画。脚本依赖于Python的os、sys、string、getopt、lxml和requests等库,适用于熟悉Python、XPath和HTML的读者。
下载漫画的脚本
身为漫画迷,一直想直接将漫画下载到电脑上看,于是就有这个python脚本。
系统:Ubuntu 14.04
python版本:2.7.6
用到的python库有:
- os (操作系统接口的标准库,用于创建文件)
- sys (标准库,获取命令行参数)
- string (字符串操作的标准库,用于将字符串中的数值转换为整型)
- getopt (对命令行参数进行处理)
- lxml (当中的html,相当于Jsoup,这里用于快速查找网页的元素)
- requests (通过URL获取网页)
- urllib2 (作用和requests差不多)
其中非标准库getopt、lxml、requests、urlslibs可以通过pip安装。
思路:
- 选择漫画网站进行解析,显示漫画章节
- 选择漫画章节,找到本章漫画图片的路径
- 按漫画图片的路径下载到本地保存
要求:了解Python、XPath、URL、html即可。
步骤
1.解析漫画章节列表
以纳米漫画网下的盘龙为例(以前叫国漫吧,很多国漫都能看,我挺喜欢的,不过chromium却显示这网站有毒*=*,注意)
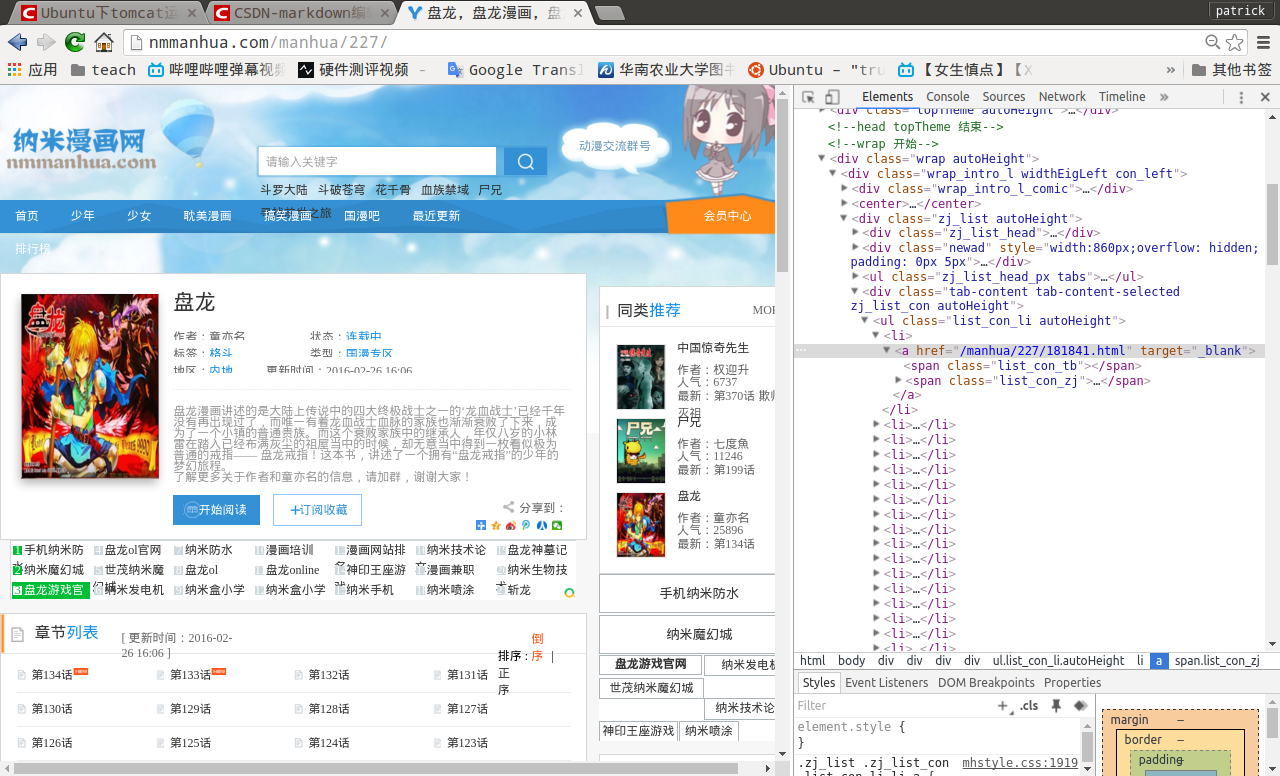
为了方便下载,需要将漫画的每个章节标题和相应的链接记录下来。
查看章节列表的源码,发现章节是用无序列表关联的,查看其中一个章节的XPath,/html/body/div[2]/div[1]/div[2]/div[3]/ul/li[1]/a。但是每个章节的xpath都是不一样的,我们不可能一个一个地计算,这时就要找到它们的共同点。
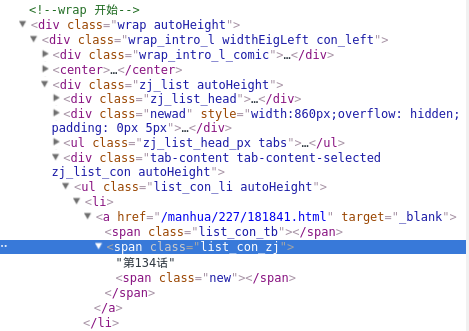
很明显,可以用含class的xpath代替,xpath可以理解为网页元素的标识、位置。
这里用//div[@class=”tab-content tab-content-selected zj_list_con autoHeight”]/ul[@class=”list_con_li autoHeight”]/li代替每个章节,
那么章节标题就是
**//div[@class="tab-content tab-content-selected zj_list_con autoHeight"]/ul[@class="list_con_li autoHeight"]/li/a/span[@class="list_con_zj"]/text()**,
章节的链接就是**//div[@class="tab-content tab-content-selected zj_list_con autoHeight"]/ul[@class="list_con_li autoHeight"]/li/a[@href]/@href**
代码如下
#获取漫画的目录
def getIndexLinkFromDirectory(comic_directory_url):
page = requests.get(comic_directory_url)
tree = html.fromstring(page.con 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3322
3322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









