







这是系列博客的第一篇,首先说明以下,本人目前本科在读的学生而已,加之第一次写博客,这一系列博客只是为了总结自己所学,如果有幸被看到,如有不对的地方欢迎指出。下面进入正题
1-4以前都是关于Machine Learning的介绍,就不再这里赘述。
所以第一课讲的是监督学习(Supervised Learning),什么是监督学习,简单来说就是给你一组数据,这组数据有参数,而根据参数又有一个确定的你需要的结果,通过这组数据的学习,你可以预测一个确定的结果,当然这个结果的准确性取决于数据量的大小与准确性。
而监督学习又有两大类问题:分类(classification)与回归(regression)。
回归问题——预测一个连续值。这里举一个例子: 一个人要卖房子,他收集了他所在地区进来的房子交易记录,包括房子的大小以及对应的成交价格,两个数据分别在xy轴上显然可以画出一个XY散点图如图:
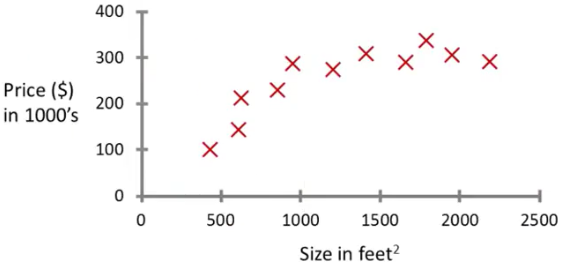
为了预测一个值,你就需要把这些已知的数据以一个函数拟合起来,但是显然,并不只有一个函数能够拟合这些散点。比如直线(红线)或者平方函数(蓝线):
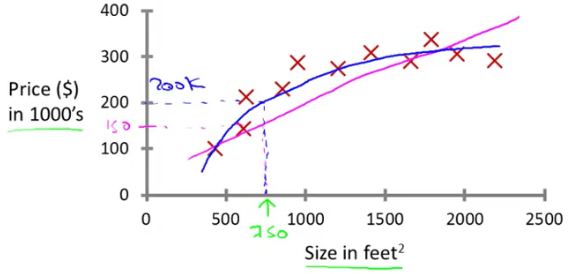
选择不同函数的预测结果就可能不同,这由你选择的算法所决定,而哪种算法更适合更准确,这在后面的学习中会讲到。
分类问题——预测一个离散值。当你需要预测的结果是像选择题一样只有有限个答案时便是分类问题了。这里也举一个例子:
在医学上,通常可以根据肿瘤的各种特征预测肿瘤是良性还是恶性,特征当然是越多越准确。这里将问题简单化,只以大小来预测。同样有一个数据集,肿瘤大小和其对应的是良性(0)还是恶性(1):

可见,肿瘤越小,良性的概率越大。进一步研究这个问题,再加上患者的年龄为参数(圈为良性,叉为恶性):
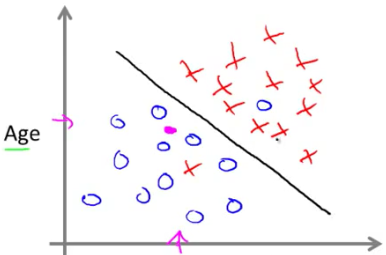
这时可以根据算法将结果分离,再判断需要预测的结果处于那个部分。而更多的时候,现实中的例子经常是有多个特征的,甚至无限个特征,这时你显然不可能写出所有的特征,计算机也是处理不了的,这时便要用到一个叫做支持向量机(Support Vector Machine)的算法,这个也会在以后讲到。
所以这便是第一课了,了解几个概念,相对简单。有点啰嗦,慢慢改进。















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









