







Flink即刻出发
flink中文官网: https://flink.apache.org/zh/
1.1.Flink 数据流
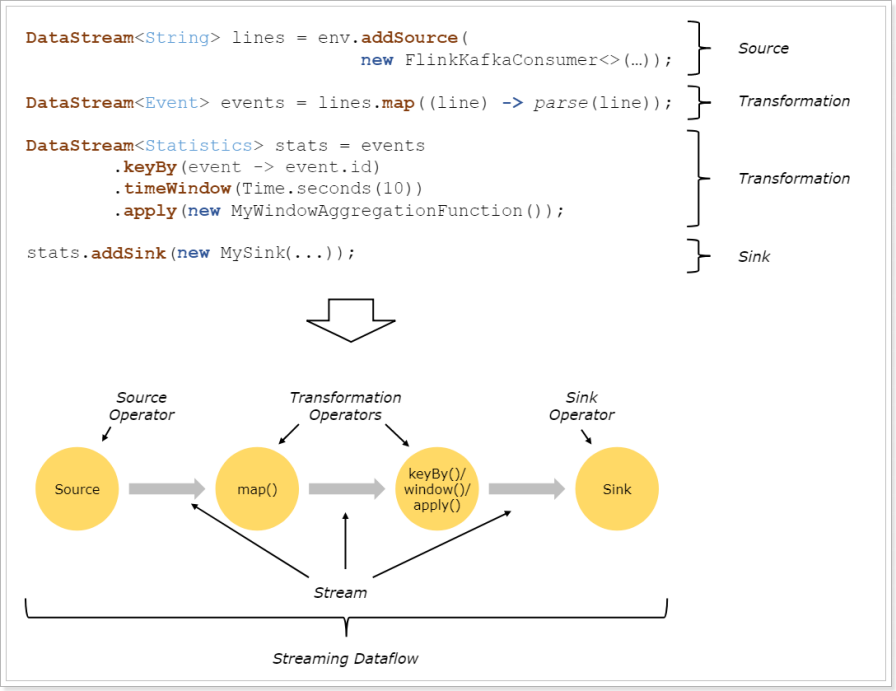
在 Flink 中,应用程序由数据流组成,这些数据流可以由用户定义的运算符(注:有时我们称这些运算符为“算子”)进行转换。这些数据流形成有向图,从一个或多个源开始,以一个或多个输出结束。

Flink 支持流处理和批处理,它是一个分布式的流批结合的大数据处理引擎。在 Flink 中,认为所有的数据本质上都是随时间产生的流数据,把批数据看作是流数据的特例,只不过流数据是一个无界的数据流,而批数据是一个有界的数据流(例如固定大小的数据集)。如下图所示:


因此,Flink 是一个用于在无界和有界数据流上进行有状态计算的通用的处理框架,它既具有处理无界流的复杂功能,也具有专门的运算符来高效地处理有界流。通常我们称无界数据为实时数据,来自消息队列或分布式日志等流源(如 Apache Kafka 或 Kinesis)。而有界数据,通常指的是历史数据,来自各种数据源(如文件、关系型数据库等)。由 Flink 应用程序产生的结果流可以发送到各种各样的系统,并且可以通过 REST API 访问 Flink 中包含的状态。
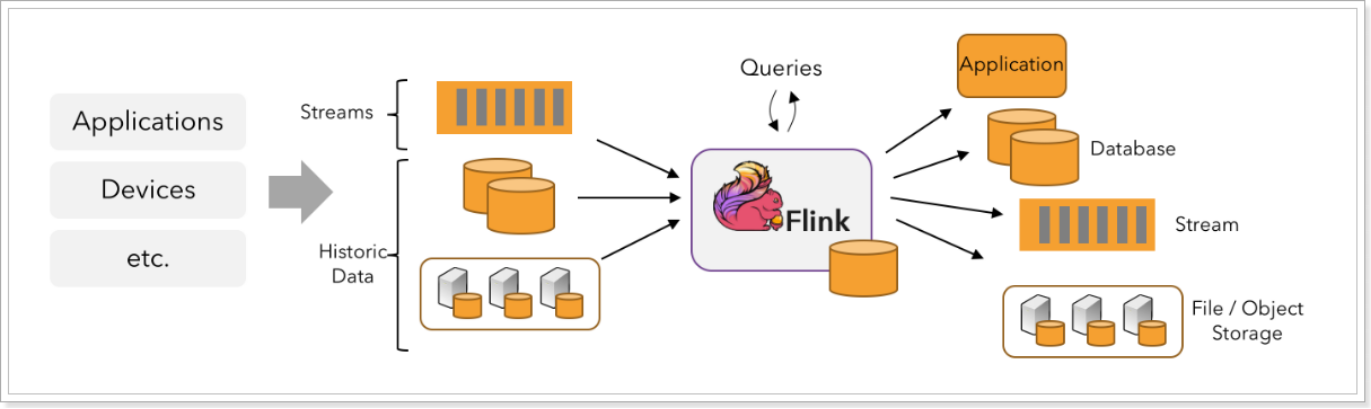
当 Flink 处理一个有界的数据流时,就是采用的批处理工作模式。在这种操作模式中,我们可以选择先读取整个数据集,然后对数据进行排序、计算全局统计数据或生成总结所有输入的最终报告。当 Flink 处理一个无界的数据流时,就是采用的流处理工作模式。对于流数据处理,输入可能永远不会结束,因此我们必须在数据到达时持续不断地对这些数据进行处理。
1.2.Flink 分层 API
Flink 提供了开发流/批处理应用程序的API供开发者使用,越往上抽象程度越高,使用起来越方便;越往下越底层,使用起来难度越大,如下图所示:
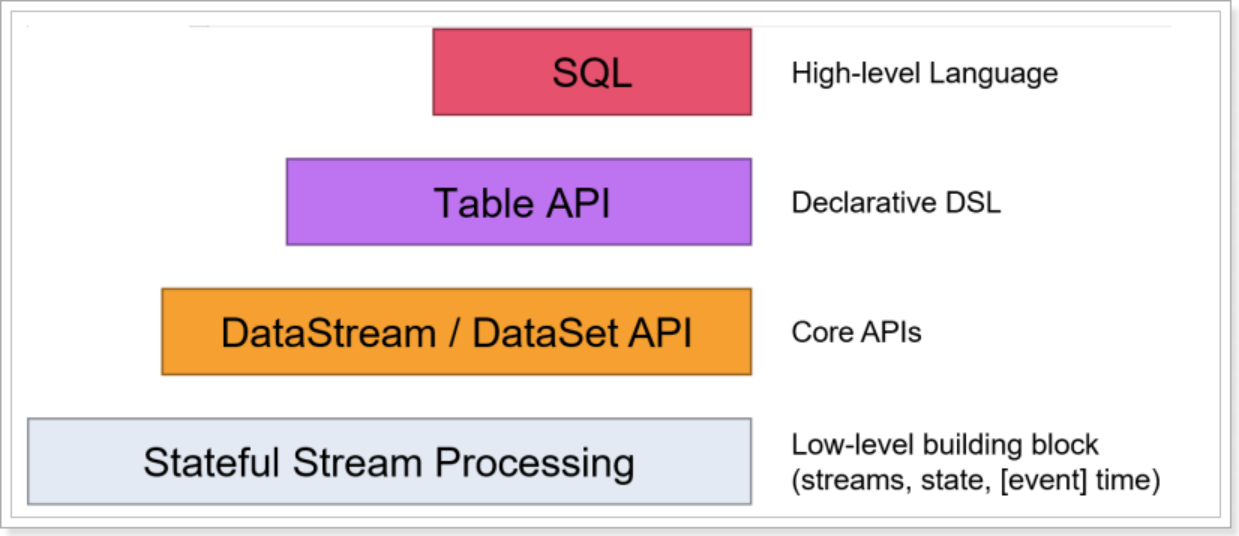
Flink 提供了三个分层的 API。每个 API 在简洁性和表达性之间提供了不同的权衡,并针对不同的应用场景。
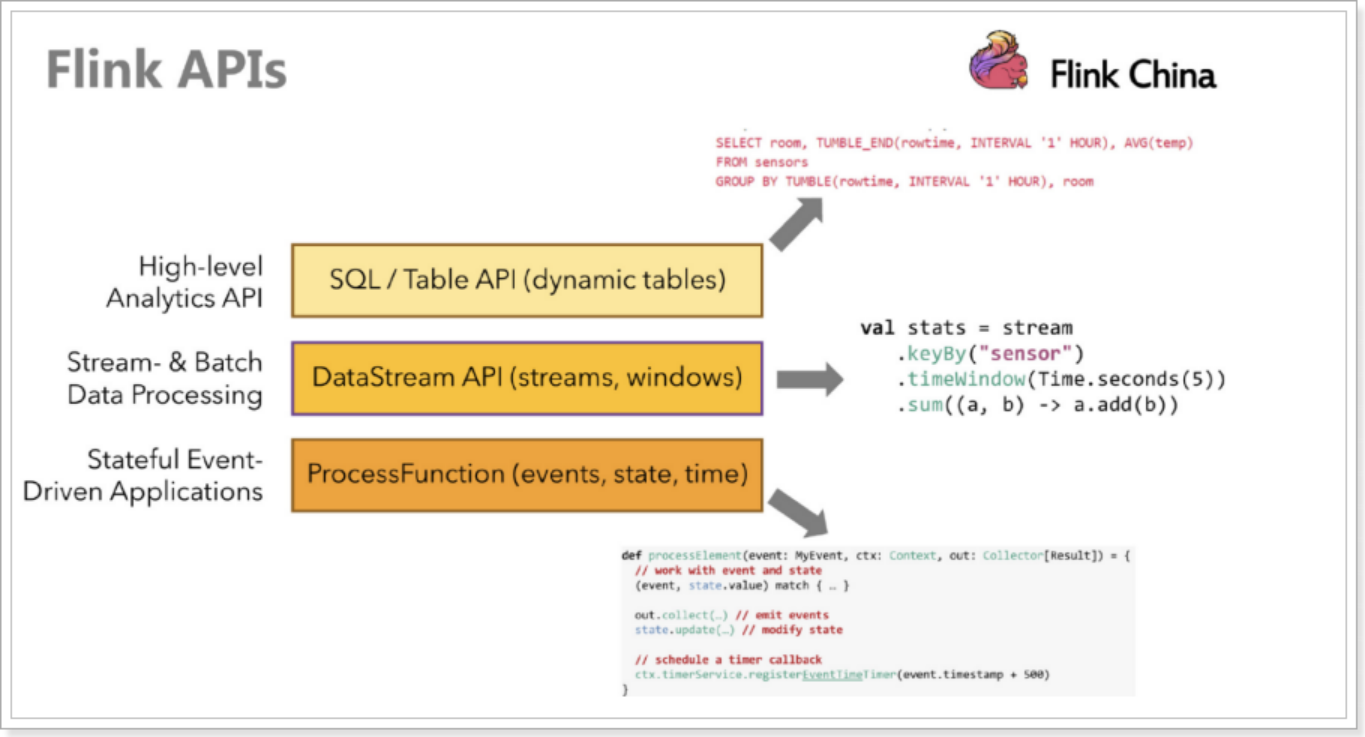

注意:在Flink1.12时支持流批一体,DataSetAPI已经不推荐使用了,所以博主在文章中除了个别案例使用DataSet外,后续其他案例都会优先使用DataStream流式API,既支持无界数据处理/流处理,也支持有界数据处理/批处理!当然Table&SQL-API会单独学习
https://ci.apache.org/projects/flink/flink-docs-release-1.14/zh/docs/dev/dataset/overview/
1.3.Flink流处理程序的一般流程
- 获取Flink流处理执行环境
- 构建source
- 数据处理
- 构建sink
1.4.搭建Flink工程
1.4.1.创建Maven项目
创建maven项目,项目名称:flinkbase


1.4.2.导入pom依赖

<!-- 指定仓库位置,依次为aliyun、apache和cloudera仓库 -->
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>apache</id>
<url>https://repository.apache.org/content/repositories/snapshots/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.14.0</flink.version>
<hive.version>3.1.2</hive.version>
<mysql.version>5.1.48</mysql.version>
<vertx.version>3.9.0</vertx.version>
<commons.collections4>4.4</commons.collections4>
<fastjson.version>1.2.68</fastjson.version>
<log4j.version>1.7.7</log4j.version>
<lombok.version>1.18.22</lombok.version>
<kafka.version>3.0.0</kafka.version>
<flink-shaded-hadoop.version>3.1.1.7.2.9.0-173-9.0</flink-shaded-hadoop.version>
<collections4.version>4.4</collections4.version>
<avro.version>1.10.2</avro.version>
<flink-filesystem.version>1.11.4</flink-filesystem.version>
<!-- sdk -->
<java.version>1.8</java.version>
<scala.version>2.12</scala.version>
<scala.binary.version>2.12</scala.binary.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- web ui的依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Apache Flink 的依赖 -->
<!-- 这些依赖项,不应该打包到JAR文件中. -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 用于通过自定义功能,格式等扩展表生态系统的通用模块-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-queryable-state-runtime</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink连接器-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-pulsar_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-filesystem_${scala.binary.version}</artifactId>
<version>${flink-filesystem.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
<exclusions>
<exclusion>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<groupId>org.apache.flink</groupId>
</exclusion>
<exclusion>
<artifactId>flink-runtime_${scala.binary.version}</artifactId>
<groupId>org.apache.flink</groupId>
</exclusion>
<exclusion>
<artifactId>flink-core</artifactId>
<groupId>org.apache.flink</groupId>
</exclusion>
<exclusion>
<artifactId>flink-java</artifactId>
<groupId>org.apache.flink</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-metastore</artifactId>
<version>${hive.version}</version>
<exclusions>
<exclusion>
<artifactId>hadoop-hdfs</artifactId>
<groupId>org.apache.hadoop</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop-3-uber</artifactId>
<version>${flink-shaded-hadoop.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<!-- 高性能异步组件:Vertx-->
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-core</artifactId>
<version>${vertx.version}</version>
</dependency>
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-jdbc-client</artifactId>
<version>${vertx.version}</version>
</dependency>
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-redis-client</artifactId>
<version>${vertx.version}</version>
</dependency>
<!-- 日志 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-collections4</artifactId>
<version>${collections4.version}</version>
</dependency>
<dependency>
<groupId>org.apache.thrift</groupId>
<artifactId>libfb303</artifactId>
<version>0.9.3</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>${avro.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-avro</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>${kafka.version}</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/java</sourceDirectory>
<plugins>
<!-- 编译插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<!--<encoding>${project.build.sourceEncoding}</encoding>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<!-- 打包插件(会包含所有依赖) -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<!--
zip -d learn_spark.jar META-INF/*.RSA META-INF/*.DSA META-INF/*.SF -->
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<!-- 设置jar包的入口类(可选) -->
<mainClass></mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
1.5.批处理的单词统计
1.5.1.示例
编写Flink程序,读取文件中的字符串,并以空格进行单词拆分打印。
1.5.2.开发步骤
- 获取批处理运行环境
- 指定读取文件路径,获取数据
- 对获取到的数据进行空格拆分
- 对拆分后的单词,每个单词记一次数
- 对拆分后的单词进行分组
- 根据单词的次数进行聚合
- 打印输出
- 启动执行
1.5.3.参考代码
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.*;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* 需求:批的方式统计单词出现的次数
* todo 使用flink1.12版本之前流批一体架构不太成熟,因此批流开发需要使用两套api实现,但是从该版本以后,可以使用一套既可以跑批作业,也可以跑流作业
* 批作业的数据抽象是:DataSet
* 流作业的数据抽象是:DataStream
*
* 在flink1.12以后,批流作业的数据抽象是:DataStream
*/
public class BatchWordCount {
public static void main(String[] args) throws Exception {
/**
* 实现步骤
* 1)获取批处理的运行环境
* 2)指定文件路径,获取数据
* 3)对获取到的数据进行空格拆分
* 4)对拆后的数据进行单词计数,每个单词记一次数
* 5)对第四步的结果进行按照单词进行分组
* 6)根据单词出现的计数进行聚合操作
* 7)打印输出
* 8)启动运行
*/
//todo 1)获取批处理的运行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//todo 2)指定文件路径,获取数据(ctrl+p:查看方法参数说明)
DataSource<String> textFile = env.readTextFile("./data/input/wordcount.txt");
//todo 3)对获取到的数据进行空格拆分(ctrl+n:搜索类)
FlatMapOperator<String, String> words = textFile.flatMap(new FlatMapFunction<String, String>() {
//(ctrl+i:重写父类的方法)
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
//根据空格拆分字符串
String[] words = value.split(" ");
//循环单词数组,将每个单词返回
for (String word : words) {
//返回数据
out.collect(word);
}
}
});
//todo 4)对拆后的数据进行单词计数,每个单词记一次数
MapOperator<String, Tuple2<String, Integer>> wordAndOne = words.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
return Tuple2.of(value, 1);
}
});
//todo 5)对第四步的结果进行按照单词进行分组
UnsortedGrouping<Tuple2<String, Integer>> grouped = wordAndOne.groupBy(0);
//todo 6)根据单词出现的计数进行聚合操作
AggregateOperator<Tuple2<String, Integer>> sumed = grouped.sum(1);
//todo 7)打印输出
sumed.print();
//todo 8)启动运行(批处理里面可以忽略,print方法会触发作业执行)
}
}
1.6.流处理的单词统计
1.6.1.示例
编写Flink程序,接收socket的单词数据,并以空格进行单词拆分打印。
1.6.2.开发步骤
- 获取流处理运行环境
-构建socket流数据源,并指定IP地址和端口号 - 对接收到的数据进行空格拆分
- 对拆分后的单词,每个单词记一次数
- 对拆分后的单词进行分组
- 根据单词的次数进行聚合
- 打印输出
- 启动执行
- 在Linux中,使用nc -lk 端口号监听端口,并发送单词
- 安装nc: yum install -y nc
- nc -lk 9999 监听9999端口的信息
1.6.3. 参考代码:java语言实现
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* 需求:编写Flink程序,接收socket的单词数据,并以空格进行单词拆分打印。
*/
public class StreamingWordCount {
public static void main(String[] args) {
/**
* 实现步骤:
* 1)获取流处理的运行环境
* 2)构建socket数据源接受数据,指定ip和端口号
* 3)对接收到的数据进行空格拆分
* 4)对拆后的数据进行单词计数,每个单词记一次数
* 5)对第四步的结果进行按照单词进行分组
* 6)根据单词出现的计数进行聚合操作
* 7)打印输出
* 8)启动运行
*/
//todo 1)获取流处理的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置全局并行度
env.setParallelism(1);
//todo 2)构建socket数据源接受数据,指定ip和端口号
DataStreamSource<String> socketTextStream = env.socketTextStream("node1", 9999);
//todo 3)对接收到的数据进行空格拆分
SingleOutputStreamOperator<String> streamOperator = socketTextStream.flatMap(new FlatMapFunction<String, String>() {
//(ctrl+i:重写父类的方法)
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
//根据空格拆分字符串
String[] words = value.split(" ");
//循环单词数组,将每个单词返回
for (String word : words) {
//返回数据
out.collect(word);
}
}
});
//todo 4)对拆后的数据进行单词计数,每个单词记一次数
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = streamOperator.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
return Tuple2.of(value, 1);
}
});
//todo 5)对第四步的结果进行按照单词进行分组
KeyedStream<Tuple2<String, Integer>, String> keyedStream = wordAndOne.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
});
//todo 6)根据单词出现的计数进行聚合操作
SingleOutputStreamOperator<Tuple2<String, Integer>> sumed = keyedStream.sum(1);
//todo 7)打印输出
sumed.printToErr();
//try。。。(ctrl+alt+t)
try {
//todo 8)启动运行
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
}
1.6.4.参考代码:Lambda实现
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
/**
* 需求:编写Flink程序,接收socket的单词数据,并以空格进行单词拆分打印。
*/
public class LambdaStreamingWordCount {
public static void main(String[] args) {
/**
* 实现步骤:
* 1)获取流处理的运行环境
* 2)构建socket数据源接受数据,指定ip和端口号
* 3)对接收到的数据进行空格拆分
* 4)对拆后的数据进行单词计数,每个单词记一次数
* 5)对第四步的结果进行按照单词进行分组
* 6)根据单词出现的计数进行聚合操作
* 7)打印输出
* 8)启动运行
*/
//todo 1)获取流处理的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//todo 2)构建socket数据源接受数据,指定ip和端口号
DataStreamSource<String> socketTextStream = env.socketTextStream("node1", 9999);
//todo 3)对接收到的数据进行空格拆分
SingleOutputStreamOperator<String> streamOperator = socketTextStream.flatMap((String line, Collector<String> out) ->
Arrays.stream(line.split(" ")).forEach(out::collect)).returns(Types.STRING);
//todo 4)对拆后的数据进行单词计数,每个单词记一次数
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = streamOperator
.map(word -> (Tuple2.of(word, 1))).returns(Types.TUPLE(Types.STRING, Types.INT));
//todo 5)对第四步的结果进行按照单词进行分组
KeyedStream<Tuple2<String, Integer>, Tuple> keyedStream = wordAndOne.keyBy(0);
//todo 6)根据单词出现的计数进行聚合操作
SingleOutputStreamOperator<Tuple2<String, Integer>> sumed = keyedStream.sum(1);
//todo 7)打印输出
sumed.printToErr();
//try。。。(ctrl+alt+t)
try {
//todo 8)启动运行
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
}
1.6.5.参考代码:使用批流一体API编程模型实现
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* 使用流批一体的方式实现wordCount的单词统计
* 既可以跑批作业也可以跑流,根据数据源的类型决定
*/
public class UnifyWordCount {
public static void main(String[] args) {
/**
* 实现步骤:
* 1)获取流处理的运行环境
* 2)构建socket数据源接受数据,指定ip和端口号
* 3)对接收到的数据进行空格拆分
* 4)对拆后的数据进行单词计数,每个单词记一次数
* 5)对第四步的结果进行按照单词进行分组
* 6)根据单词出现的计数进行聚合操作
* 7)打印输出
* 8)启动运行
*/
//todo 1)获取流处理的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//env.setRuntimeMode(RuntimeExecutionMode.BATCH); //将当前作业强制按照批的方式运行,报错,因为数据源本身决定了无法以批的方式来运行
//env.setRuntimeMode(RuntimeExecutionMode.STREAMING);//将当前作业强制按照流的方式运行
//env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//默认的运行模式,根据数据源自动判断
//todo 2)构建socket数据源接受数据,指定ip和端口号
//DataStreamSource<String> socketTextStream = env.socketTextStream("node1", 9999);
DataStreamSource<String> socketTextStream = env.readTextFile("./data/input/wordcount.txt");
//todo 3)对接收到的数据进行空格拆分
SingleOutputStreamOperator<String> streamOperator = socketTextStream.flatMap(new FlatMapFunction<String, String>() {
//(ctrl+i:重写父类的方法)
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
//根据空格拆分字符串
String[] words = value.split(" ");
//循环单词数组,将每个单词返回
for (String word : words) {
//返回数据
out.collect(word);
}
}
});
//todo 4)对拆后的数据进行单词计数,每个单词记一次数
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = streamOperator.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
return Tuple2.of(value, 1);
}
});
//todo 5)对第四步的结果进行按照单词进行分组
KeyedStream<Tuple2<String, Integer>, String> keyedStream = wordAndOne.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
});
//todo 6)根据单词出现的计数进行聚合操作
SingleOutputStreamOperator<Tuple2<String, Integer>> sumed = keyedStream.sum(1);
//todo 7)打印输出
sumed.printToErr();
//try。。。(ctrl+alt+t)
try {
//todo 8)启动运行
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
}
1.7.Flink程序提交部署
Flink程序递交方式有两种:
- 以UI的方式递交
- 以命令的方式递交
1.7.1.编写程序
写入HDFS如果存在权限问题:
进行如下设置:
hadoop fs -chmod -R 777 /
并在代码中添加:
System.setProperty("HADOOP_USER_NAME", "root")
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
/**
* 编写Flink程序,读取文件中的字符串,并以空格进行单词拆分打印
*
*/
public class BatchWordCountToYarn {
public static void main(String[] args) throws Exception {
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String output = "";
if (parameterTool.has("output")) {
output = parameterTool.get("output");
System.out.println("指定了输出路径使用:" + output);
} else {
output = "hdfs://node1:8020/wordcount/output47_";
System.out.println("可以指定输出路径使用 --output ,没有指定使用默认的:" + output);
}
//TODO 0.env
//ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//env.setRuntimeMode(RuntimeExecutionMode.BATCH);//注意:使用DataStream实现批处理
//env.setRuntimeMode(RuntimeExecutionMode.STREAMING);//注意:使用DataStream实现流处理
//env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//注意:使用DataStream根据数据源自动选择使用流还是批
//TODO 1.source
//DataSet<String> lines = env.fromElements("itcast hadoop spark", "itcast hadoop spark", "itcast hadoop", "itcast");
DataStream<String> lines = env.fromElements("itcast hadoop spark", "itcast hadoop spark", "itcast hadoop", "itcast");
//TODO 2.transformation
//切割
/*
@FunctionalInterface
public interface FlatMapFunction<T, O> extends Function, Serializable {
void flatMap(T value, Collector<O> out) throws Exception;
}
*/
/*DataStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
//value就是每一行数据
String[] arr = value.split(" ");
for (String word : arr) {
out.collect(word);
}
}
});*/
SingleOutputStreamOperator<String> words = lines.flatMap(
(String value, Collector<String> out) -> Arrays.stream(value.split(" ")).forEach(out::collect)
).returns(Types.STRING);
//记为1
/*
@FunctionalInterface
public interface MapFunction<T, O> extends Function, Serializable {
O map(T value) throws Exception;
}
*/
/*DataStream<Tuple2<String, Integer>> wordAndOne = words.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
//value就是一个个单词
return Tuple2.of(value, 1);
}
});*/
DataStream<Tuple2<String, Integer>> wordAndOne = words.map(
(String value) -> Tuple2.of(value, 1)
).returns(Types.TUPLE(Types.STRING, Types.INT));
//分组:注意DataSet中分组是groupBy,DataStream分组是keyBy
//wordAndOne.keyBy(0);
/*
@FunctionalInterface
public interface KeySelector<IN, KEY> extends Function, Serializable {
KEY getKey(IN value) throws Exception;
}
*/
KeyedStream<Tuple2<String, Integer>, String> grouped = wordAndOne.keyBy(t -> t.f0);
//聚合
SingleOutputStreamOperator<Tuple2<String, Integer>> result = grouped.sum(1);
//TODO 3.sink
//如果执行报hdfs权限相关错误,可以执行 hadoop fs -chmod -R 777 /
System.setProperty("HADOOP_USER_NAME", "root");//设置用户名
//result.print();
//result.writeAsText("hdfs://node1:8020/wordcount/output47_"+System.currentTimeMillis()).setParallelism(1);
result.writeAsText(output + System.currentTimeMillis()).setParallelism(1);
//TODO 4.execute/启动并等待程序结束
env.execute();
}
}
package cn.itcast.day01.b;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.*;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* 需求:批的方式统计单词出现的次数
* todo 使用flink1.12版本之前流批一体架构不太成熟,因此批流开发需要使用两套api实现,但是从该版本以后,可以使用一套既可以跑批作业,也可以跑流作业
* 批作业的数据抽象是:DataSet
* 流作业的数据抽象是:DataStream
*
* 在flink1.12以后,批流作业的数据抽象是:DataStream
*/
public class BatchWordCount {
public static void main(String[] args) throws Exception {
// 获取参数
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String output = "";
if(parameterTool.has("output")) {
output = parameterTool.get("output");
System.out.println("制定了输入路径使用: " + output);
} else {
output = "hdfs://node1:8020/wordcount/output66_";
System.out.println("可以指定输出路径使用 --output ,没有指定使用默认的:" + output);
}
// 环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 数据源
DataStreamSource<String> source = env.fromElements("hello flink spark hadoop", "hello flink spark", "hello flink");
// 数据转换
// 切割
SingleOutputStreamOperator<String> words = source.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> out) throws Exception {
String[] arr = line.split(" ");
for (String word : arr) {
out.collect(word);
}
}
});
// word, 1
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = words.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String word) throws Exception {
return Tuple2.of(word, 1);
}
});
// 分组 求和
KeyedStream<Tuple2<String, Integer>, Tuple> tuple2TupleKeyedStream = wordAndOne.keyBy(0);
SingleOutputStreamOperator<Tuple2<String, Integer>> result = tuple2TupleKeyedStream.sum(1);
// sink 写
System.setProperty("HADOOP_USER_NAME", "root");
result.writeAsText(output + System.currentTimeMillis()).setParallelism(1);
// 执行
env.execute();
}
}
使用 maven视图的 package 打包.
1.7.2.以UI的方式递交
1.7.2.1.启动 hadoop
/onekey/hd1_start.sh
1.7.2.2.启动 flink 集群
cd /export/server/flink
bin/start-cluster.sh
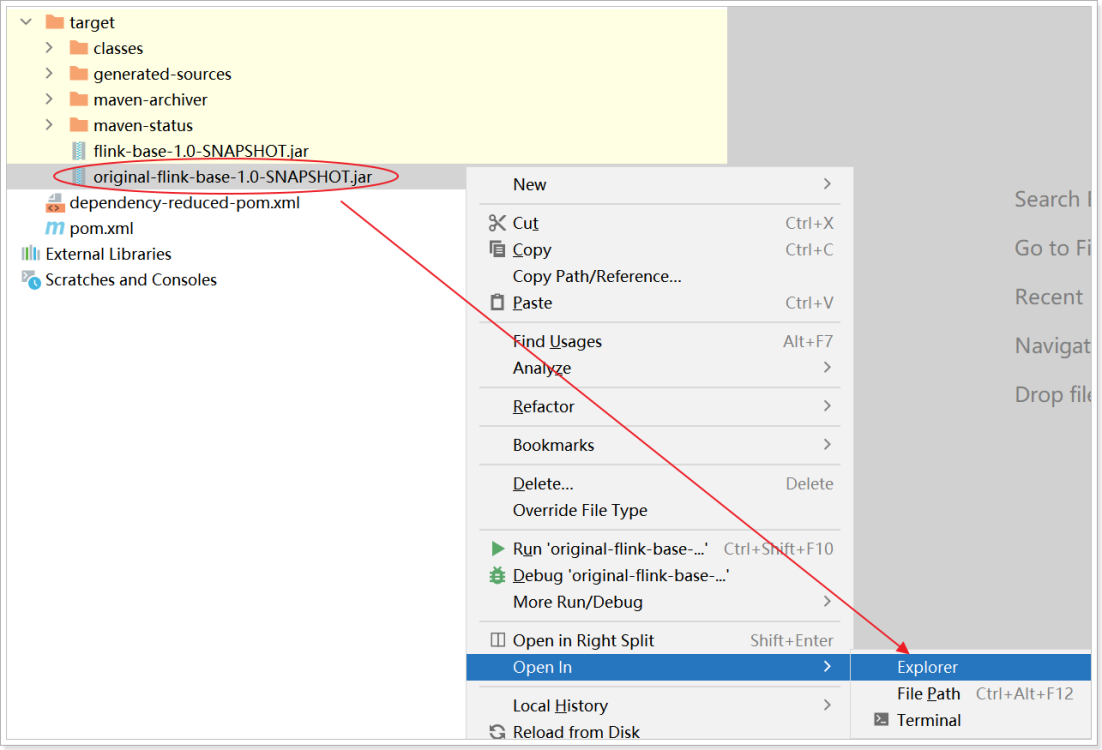
1.7.2.3.上传jar包
jar包位置
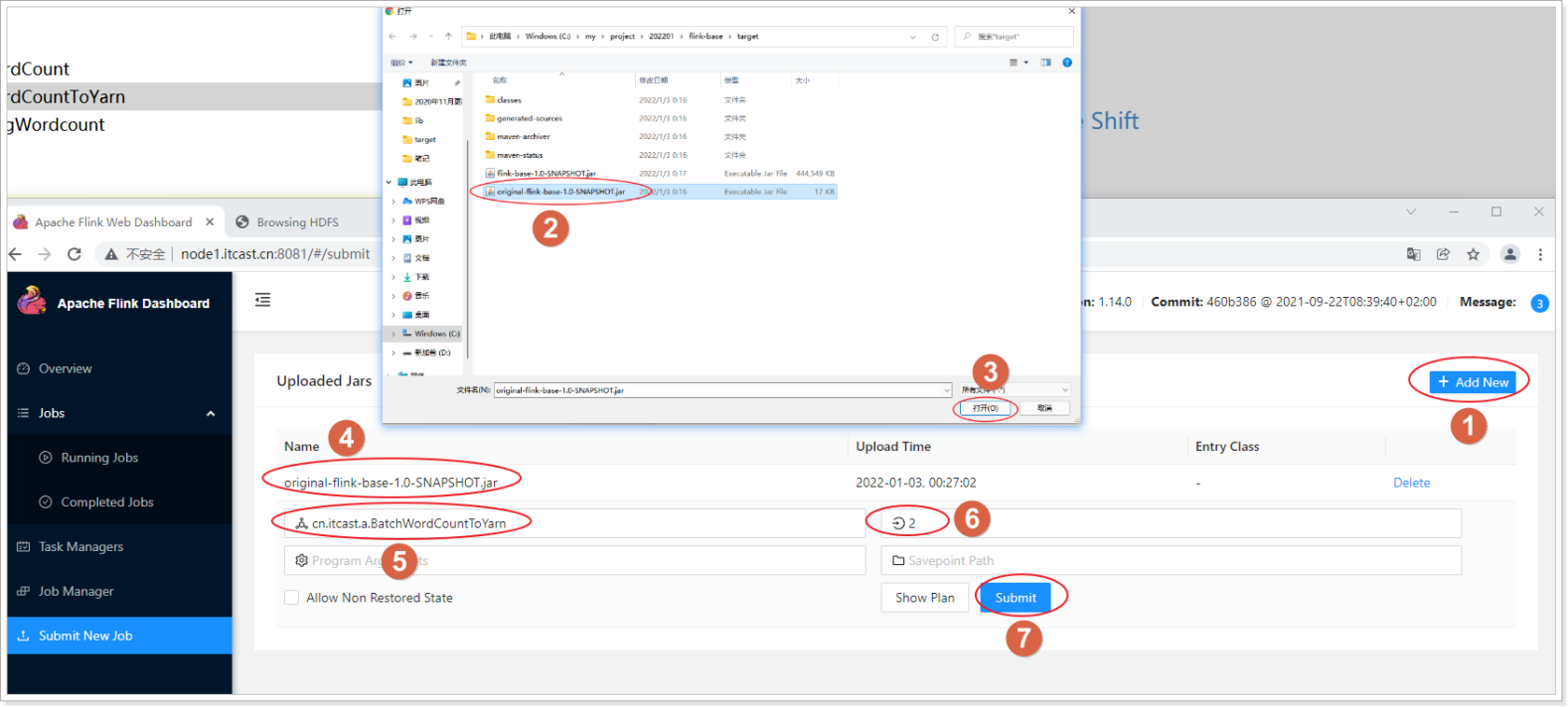
1.7.2.4.指定参数 开始执行

1.7.2.5.查看结果


1.7.3. 以命令的方式递交
参考官网:
https://ci.apache.org/projects/flink/flink-docs-release-1.14/zh/docs/dev/datastream/execution_mode/
- 上传作业jar包到linux服务器
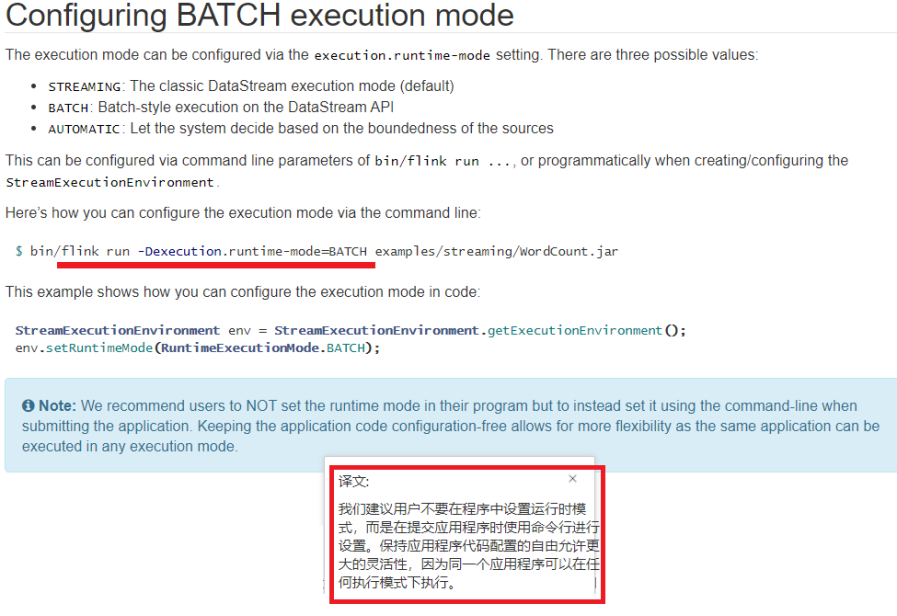
./bin/flink run \
-Dexecution.runtime-mode=BATCH -m yarn-cluster -yjm 1024 -ytm 1024 \
-c cn.itcast.day01.b.BatchWordCount /root/original-flink-base-01-1.0-SNAPSHOT.jar \
--output hdfs://node1:8020/wordcount/output_50
- 查看任务运行概述



















 1015
1015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











