






目录
引言
在使用机器学习算法时,一个很重要的任务是对模型评估和选择一个合适的模型。因为机器学习是从数据中学习并得出模型,我们需要一些方法来检查我们的模型是否正确,是否过拟合或欠拟合。通过对模型评估与选择的深入学习,让我们能够更好的理解模型的比较与选择。
评估方法
在模型评估与选择中,评估方法是评估模型性能的基础,通过对模型的性能进行评估,可以知道模型是否达到了预期效果。对于一个包含m个样例的数据集 D = {(x1,y1) , (x2,y2) , ... },既要训练,又要测试,需要对D进行适当的处理,从中产生训练集 S 和训练集 T ,用训练集的数据训练模型,用测试集的数据测试模型,这样可以避免模型过拟合的问题,并提高模型对未知数据的预测的准确率。下面介绍几种常见的数据划分方法。
留出法
"留出法"直接将数据集 D 划分成两个互斥的集合,其中一个集合作为训练集 S ,另一个作为测试集 T 。当然如果我们从"采样"的角度来看待数据集的划分的过程的话,则保留类别比例的采样方式通常称为"分层采样"。
注意:
1.训练/测试集的划分要保持数据分布的一致性。
2.使用留出法时,采用多次划分、重复实验最后取平均值作为评估结果。
3.测试集在尽量保持在 1/5~1/3 。
下面为分别采用留出法和分层采样划分数据集的代码。
#留出法划分数据集
from sklearn.datasets import load_iris #导入鸢尾花数据集。
from sklearn.model_selection import train_test_split
#sklearn中的函数,可以将数据集随机分为训练集和测试集。
iris = load_iris()
x,y = iris.data,iris.target
x_train,x_test,y_train,y_test = train_test_split(
x,y, #参数为 X和y。
train_size=0.33, #测试集所占的比例。
random_state=40 #随机种子,如果指定了这个值,那么每次分割都会生成相同的结果。
)
#分层采样法划分数据集
from sklearn.datasets import load_digits #导入digits数据集
import numpy as np
digits = load_digits()
x,y = digits.data,digits.target
x_train,x_test,y_train,y_test = train_test_split(
x,y,
train_size=0.33,
random_state=40,
stratify=y #分层采样,根据样本的某一特征分层抽样。
)
交叉验证法
"交叉验证法"先将数据集 D 划分为 k 个大小相似的互斥子集,每个子集尽可能保持数据的一致性。然后每次用 k-1 个子集的并集作为训练集,剩下的子集就是测试集,然后进行 k 次训练和测试,最后返回 k 次测试结果的子集。最常采用的 k 值为10,下图为10折交叉验证的示意图。
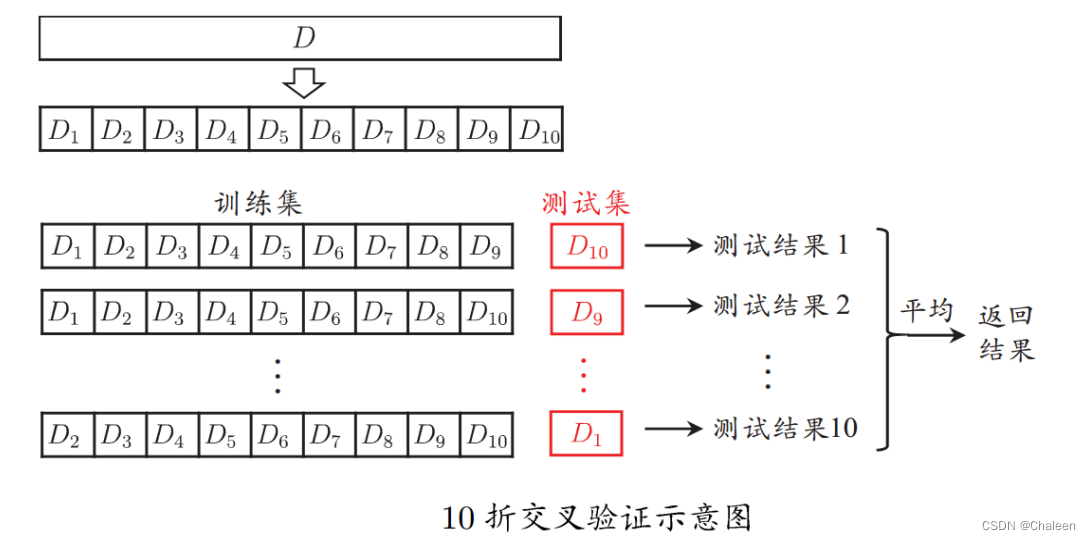
将数据集 D 划分为 k 个子集同样存在多种划分方式,所以为了减少因样本划分不同而产生的误差,我们也会随即多次划分 p 次,最终的结果就是这 p 次 k 折交叉验证的平均值。在交叉验证法中,有 k 折交叉验证数据划分法、 k 折交叉验证分层数据划分法、重复 k 折交叉验证数据划分法和留一法。k 折交叉验证数据划分法和 k 折交叉验证分层数据划分法这两种方法都是要将数据分成 k 个子集,而 k 折交叉验证分层数据划分法需要对数据进行分层抽样的操作,这是为了防止数据不均衡时,会影响对模型的性能评估,例如,一个数据集10%为正90%为负,那每个折中正例反例的比都为1:9。因此,k 折交叉验证分层数据划分法更适用于样例类别分布不均衡的情况。而重复 k 折交叉验证数据划分法是在k折交叉验证的基础上,进行多次重复实验,对模型进行多次评估,从而得到一个稳定的模型评估结果。
当数据集中样本数量只有 m 个,并且令 k 折交叉检验的 k = m时,这时样本的划分方式只有一种,这种方法是交叉检验的一种特例:留一法(Leave-One-Out,简称为LOO)。留一法使用的训练集只比数据集少了一个样本(每次用 m - 1 个样本训练,用 1 个样本测试),所以评估的结果与期望评估相近,但是留一法不适用于样本数量太多的情况。下面是几种交叉验证的代码。
#k折交叉检验数据划分法
from sklearn.model_selection import KFold
from sklearn.datasets import load_iris
from sklearn import metrics
iris = load_iris()
x = iris.data #样本数据
y = iris.target #样本标签
k = 5
kf = KFold(n_splits=k)
for train_index,test_index in kf.split(x,y):
x_train,x_test = x[train_index],x[test_index]
y_train,y_test = y[train_index],y[test_index]
# print(f"Train labels:\n{y_train}")
#print(f"Test labels:\n{y_test}")
#k折交叉验证分层数据划分法
from sklearn.model_selection import StratifiedKFold
iris = load_iris()
x = iris.data
y = iris.target
skf = StratifiedKFold(n_splits=k, shuffle=True)
for train_index, test_index in skf.split(x, y):
print("Train:", train_index, "Validation", test_index)
x_train, x_test = x[train_index], x[test_index]
y_train, y_test = y[train_index], y[test_index]
#重复k折交叉验证数据划分法
from sklearn.model_selection import RepeatedKFold
iris = load_iris()
x = iris.data
y = iris.target
kf = RepeatedKFold(n_splits=5,n_repeats=2)
for train_index, test_index in kf.split(x, y):
print("Train:", train_index, "Validation", test_index)
x_train, x_test = x[train_index], x[test_index]
y_train, y_test = y[train_index], y[test_index]
#留一法
from sklearn.model_selection import LeaveOneOut
iris = load_iris()
x = iris.data
y = iris.target
loo = LeaveOneOut()
for train_index, test_index in loo.split(X):
x_train, x_test = x[train_index], x[test_index]
y_train, y_test = y[train_index], y[test_index]自助法
给定一个包含 m 个样本的数据集 D ,每次从 D 中随机取出一个样本,并将其拷贝到数据集 D'中,再将这个样本放回 D ,重复 m 次后,D' 中就有了 m 个样本,这就是自主采样的结果。我们的训练集采用的是 D' ,而测试集则是用 D - D' 。当数据集比较大时,一般不会采用自助法划分,这样会占用大量的空间,并有大量的计算,所以自助法适用于数据集较小,难以有效划分训练集和测试集的情况。接下来简单估计一下,数据集中样本在m次始终不被采样到的概率是,取极限得:
所以数据集D中有36.8%的样本未出现在训练集中,这个值落在我们通常划分测试集的比例周围,故可以用自助法划分数据集。下面是自助法的代码。
import numpy as np
x = np.random.randint(-10,10,10)
# 将x中大于0的元素设置为1,小于等于0的元素设置为0,得到另一个数组y
y = (x>0).astype(int)
bootstrapping = []
#随机生成x中的下标
for i in range(len(x)):
bootstrapping.append(np.floor(np.random.random()*len(x)))
x_1 = []
y_1 = []
for i in range(len(x)):
x_1.append(x[int(bootstrapping[i])])
y_1.append(y[int(bootstrapping[i])])
print(x_1)
print(y_1)性能度量
评估方法是指划分数据集以后评估模型的方法,训练好模型以后,我们需要一些指标去评价模型在各方面的性能,这就需要用到性能度量。什么是性能度量呢?简单的来说就是衡量模型性能的指标或者标准。使用不同的性能度量去评价一个机器学习的模型,得出的评判结果是不同的。性能度量可以分为分类问题和回归问题,根据数据类别的数量,分类问题又可以分为二分类问题和多分类问题。接下来,我会介绍一些关于机器学习的性能度量。
回归问题指标
MSE (Mean Squared Error):均方误差,是指样本预测值与真实值差值的平方的均值。MSE越小,模型预测误差越小。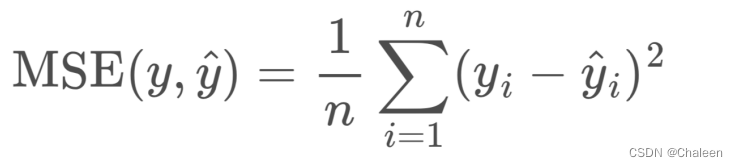
RMSE (Root Mean Squared Error):均方根误差,是均方误差开根号。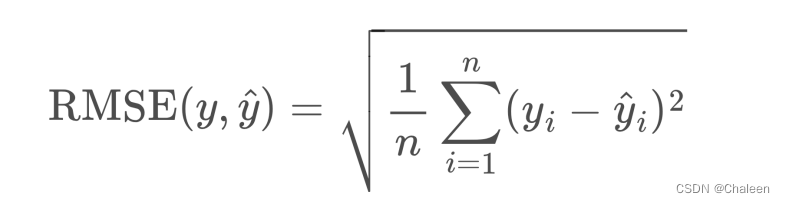
MAE (Mean Absolute Error):平均绝对误差,是预测值与真实值之差的绝对值的均值。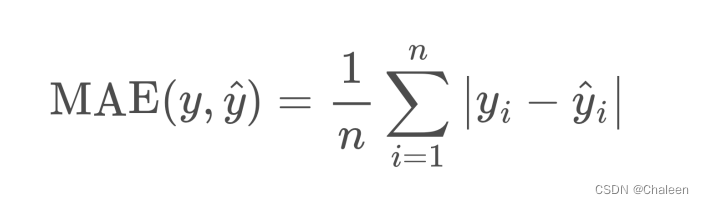
二分类问题指标
错误率: 分类错误的样本占总样本的比例。
精度:分类正确的样本占总样本的比例。
在二分类问题中,可以根据样本的真实类型与学习器所预测的类型组合为:真正例(TP)、假正例(FP)、真反例(TN)、假反例(FN)。这些组合可能有点混,还不知道如何分清哪些是TP哪些是FP,我认为可以这样看这些组合。P和N是代表学习器预测的值,而T和F是用来形容P和N的。TP的P就代表着学习器预测样本为正,T就代表这个预测是是真的,也就是真的正例;TN代表预测样本为假,而这个预测是真的;FP代表预测样本为正,但这个预测是假的,也就是这个样本实际上是负;FN代表预测样本为负,但这个预测是假的,这个样本实际上是真的。而由TP,TN,FP,FN可以组成混淆矩阵。

由此可以引出查准率P与查全率R。查准率P是指学习器所预测对的正例占整个学习器所预测为正例的比例,。查全率R指的是学习器所预测对的正例占整个实际正例的比例,
。一般来说,查准率高,查全率就偏低;查准率低,查全率就偏高。由P和R我们可以引出F1-Score,F1值也是评价指标之一,F1值综合考虑了查全率与查准率两个指标,是P和R的调和平均数
。
以查准率为纵轴,查全率为横轴作图时,就可以得到查准率-查全率曲线,简称"P-R曲线",显示该曲线的图称为"P-R图"。那么应该怎么去画一个P-R曲线图呢?首先需要先将模型的预测值从大到小进行排列,这是因为在不同的阈值下,P和R的值都是不同的,那我们就需要每次都去计算不同阈值下的P和R,然后在将这些点对连接起来就是我们的P-R曲线图。下面是P-R图的Python代码。
#P-R曲线图
pp = [['T', 0.9], ['T', 0.8], ['N', 0.7], ['T', 0.6], ['T', 0.55], ['T', 0.54], ['N', 0.53], ['N', 0.52],
['T', 0.51], ['N', 0.505], ['T', 0.4], ['N ', 0.39], ['T', 0.38], ['N', 0.37], ['N', 0.36], ['N ', 0.35],
['T', 0.34], ['N', 0.33], ['T', 0.30], ['N', 0.1]]
aa = [0.9, 0.8, 0.7, 0.6, 0.55, 0.54, 0.53, 0.52, 0.51, 0.505, 0.4, 0.39, 0.38, 0.37, 0.36, 0.35, 0.34, 0.33, 0.3, 0.1]
recall = []
precision = []
for a in aa:
tp = 0
fp = 0
fn = 0
for p in pp:
if(p[0]=='T' and p[1]>=a):
tp=tp+1
if(p[0]=='N' and p[1]>=a):
fp=fp+1
if(p[0]=='T' and p[1]<a):
fn=fn+1
x = float(tp)/(tp+fn)
y = float(tp)/(tp+fp)
recall.append(x)
precision.append(y)
plt.figure(figsize=(5,5)) #绘制一张5*5大小的新图表
plt.title('precision-recall curve',fontsize=16) #设置标题
plt.plot(recall,precision) #绘制线条
plt.plot(recall,precision,'ro') #在线条上标记数据点
plt.xlabel('Recall',fontsize=16) #设置x轴
plt.ylabel('Precision',fontsize=16,rotation=90) #设置y轴,rotation表示旋转多少度
plt.show()还有一种曲线叫做假正例率-真正例率曲线,简称“ROC曲线”。这种曲线是以“假正例率”(简称FPR)为横轴,“真正例率”(简称TPR)为纵轴。FPR指的是被预测为正,其实实际上是负例的样本占所有负样本的比例,TPR指的是被预测为正,实际上也是正例的样本占所有正样本的比例。
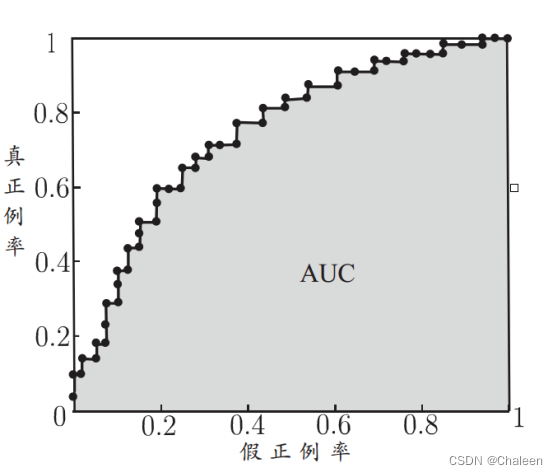
这是ROC的曲线图,可以知道,ROC曲线所围成的面积就是AUC。那么应该如何计算呢?其实很简单,可以把每两个邻接点所连直线看成X也就是矩形的高,而它们的Y相加除二也就是小矩形的底,矩形的面积是上底加下底除二,将每个矩形面积相加就是AUC。AUC公式:
AUC的值越大表示模型的性能越好,AUC的值越大,就相当于模型能够分类正确的比例就越大,例如AUC = 1时,也就相当于这个模型能够将所有的正例和所有的负例辨别出来。而我们在写ROC的代码时有两种方法,一种是根据ROC的定义来写代码,和刚刚的P-R曲线图的代码差不多;另外一种方法是用sklearn库中的函数帮我们画,我们也可以用sklearn中的函数帮我们算AUC的值,不用去列公式。下面是用sklearn库画的ROC曲线的代码。
from sklearn.metrics import roc_auc_score,roc_curve
import matplotlib.pyplot as plt
import numpy as np
pp = [['T', 0.9], ['T', 0.8], ['N', 0.7], ['T', 0.6], ['T', 0.55], ['T', 0.54], ['N', 0.53], ['N', 0.52],
['T', 0.51], ['N', 0.505], ['T', 0.4], ['N ', 0.39], ['T', 0.38], ['N', 0.37], ['N', 0.36], ['N ', 0.35],
['T', 0.34], ['N', 0.33], ['T', 0.30], ['N', 0.1]]
y_true = []
y_score = []
for p in pp:
if p[0]=='T':
y=1
else:
y=0
y_true.append(y)
y_score.append(p[1])
auc = roc_auc_score(y_true,y_score,sample_weight=None)
#调用roc_curve函数就不需要去对数据进行排序了,它会自动帮我们排
#参数 roc_curve(y_true,y_score,sample_weight=None)
#y_true是范围在(0,1)或(-1,1)的二进制标签
#y_score是模型预测的概率值
fpr,tpr,th= roc_curve(y_true,y_score)
plt.figure(figsize=(5,5))
plt.title('ROC Curve')
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.plot(fpr,tpr)
plt.show()
print(auc)相比于P-R曲线,ROC曲线的X轴采用FPR,Y轴采用TPR,这两个指标对于样本的类别不敏感,这是因为真正率和假正率是对于全部正例与全部假例而言,并不是占整个样本的比例。因此相对于P-R曲线,ROC曲线对样本的类别比例不敏感,更能够反映模型的预测性能。
多分类问题指标
在二分类问题中,我们将样本类别分成两类,在实际生活中,需要将数据划分为多个类别,此时我们就需要用到我们的多分类问题。计算在多分类问题中,一般会将其看成多个二分类的问题的组合。这里介绍一种二元分类方法One Vs Rest(简称OVR),这种方法在有m个特征的多分类问题中,将一个问题看成正类时,其余的m-1个类别看成负类,每次只需要去区分一个类别与其他类别之间的区别。
刚刚我们所介绍的都是二分类的评价指标,现在简单介绍多分类问题中的评价指标。
微查准率:
微查全率:
微F1:
在微观的评价指标中,不考虑样本之间的差异,每一个样本的占比比重都是一样的,也就是每一个样本对于最终的评价指标的贡献是一样的。我们在处理数据时,只需要将真实标签和预测标签给展平为一维数组,然后计算一系列的评价指标。所以,micro适用于样本类别不平衡的情况去计算多分类问题中的评价指标。
宏查准率:
宏查全率:
宏F1:
与微观评价对于样本比例考虑不同的是,在宏观的评价指标中会考虑样本之间的差异,也就是会对每一个特征的二分类指标进行计算,然后对于每一个指标进行平均计算。macro适用于每个类别的比重差不多的情况。
加权查准率:
加权查全率:
加权F1:
在权重的评价指标中,也是会对每一个类别的指标进行平均,但每一个类别的比重取决于样本占有所有样本的比例。Weighted需要考虑每一个类别出现的频率,频率越高比重越大,反之就越小。
下面就是这三种评价指标的代码。
from sklearn.metrics import roc_curve,roc_auc_score,auc
import matplotlib.pyplot as plt
import numpy as np
#准备数据
y_true = np.asarray([[0,0,1],[0,1,0],[1,0,0],[0,0,1],[1,0,0],
[0,1,0],[0,1,0],[0,1,0],[0,0,1],[0,1,0]])
y_pred = np.asarray([[0.1,0.2,0.7],[0.1,0.6,0.3],[0.5,0.2,0.3],[0.1,0.1,0.8],[0.4,0.2,0.4],
[0.6,0.3,0.1],[0.4,0.2,0.4],[0.4,0.1,0.5],[0.1,0.1,0.8],[0.1,0.8,0.1]])
tpr = dict()
fpr = dict()
roc_auc = dict()
trlen = y_true.shape[1]
#计算每个类别的fpr,tpr
for i in range(trlen):
fpr[i],tpr[i],th= roc_curve(y_true[:,i],y_pred[:,i])
#用micro计算roc曲线及auc
fpr["micro"],tpr["micro"],th = roc_curve(y_true.ravel(),y_pred.ravel())
roc_auc["micro"] = auc(fpr["micro"],tpr["micro"])
#用macro计算roc曲线及auc
fpr_grid = np.linspace(0.0,1.0,100)
mean_tpr = np.zeros_like(fpr_grid)
for i in range(trlen):
mean_tpr += np.interp(fpr_grid,fpr[i],tpr[i])
# np.interp(插入的范围,插入点的X,插入点的Y)
mean_tpr /= trlen
fpr["macro"] = fpr_grid
tpr["macro"] = mean_tpr
roc_auc["macro"] = auc(fpr["macro"], tpr["macro"])
对于macro平均计算roc曲线时,是对样本的每一个类别进行平均,而每一个类别所使用的阈值都是不同的,那当对所有样本简单的进行平均是不适合的,因此我们选用插值法,将不同阈值下的fpr,tpr进行插值,最后将每个类别进行平均,这样就做到了平等对待每一个类别。所以,我们的fpr_grid就是我们FPR的值,而计算得到的mean_tpr就是对每个类别平均下来的TPR值。
num1 = 0
num2 = 0
num3 = 0
for i in range(trlen):
if y_true[i][0] == 1:
num1+=1
if y_true[i][1] == 1:
num2+=1
if y_true[i][2] == 1:
num3+=1
ratio = [num1/(num1+num2+num3),num2/(num1+num2+num3),num3/(num1+num2+num3)]
avg_tpr = np.zeros_like(fpr_grid)
for i in range(trlen):
avg_tpr += ratio[i]*np.interp(fpr_grid,fpr[i],tpr[i])
fpr["weighted"]=fpr_grid
tpr["weighted"]=avg_tpr
plt.figure(figsize=(5,5))
plt.xlabel("FPR")
plt.ylabel("TPR")
plt.title("ROC Curve")
plt.plot(fpr["micro"],tpr["micro"])
plt.plot(fpr["macro"],tpr["macro"])
plt.plot(fpr["weighted"],tpr["weighted"])
plt.show()以上就是在机器学习中比较常用的数据划分方法和模型的评价指标,在实际应用当中,根据不同的情况选择合适的方法划分数据集和评价指标,可以有效的提高模型的性能。















 3314
3314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









