






引言:
在Noise2Noise方法中,使用的数据是同一场景下的不同噪声图片。然而,在许多领域中,这样的数据依然难以获取。尽管如此,Noise2Noise的这种思想是值得借鉴的。Neighbor2Neighbor正是基于这一思想进行改进的,它将一张含噪图片下采样至原图片的一半,从而构造出一个含噪图像对,并取得了不错的去噪效果。
理论方法:
回顾Noise2Noise:
给定相同的真地图像x的两个独立的噪声观测值y和z,n2n的最大似然估计:。这种数据要求还是难以满足,所以可以扩展思考一下:
1.同一场景独立含噪图像-->相似场景独立含噪图像
2.每个场景多张含噪图像-->每个场景单张含噪图像
在图像处理中有上采样以及下采样的操作,通俗点就是将图片进行比例的进行放大或者缩小,而将一张含噪图像进行下采样,刚好能够获得两张相似场景的独立含噪图像,这就和刚刚的扩展思考进行结合就有了ne2ne的大致思想。
Neighbor2Neighbor:
设y和z是两个独立的噪声图像,考虑以x为条件,,
,
,z的方差为
,有以下推导:
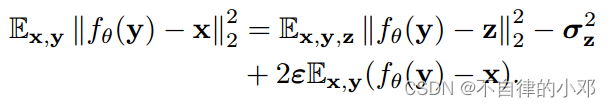
当噪声图片之间的偏差的时候,优化n2n网络的
不会得到和监督学习
相同的结果。
当的时候,
,说明n2n网络训练的结果和监督学习训练的结果是很相似的。
对于单张含噪图像而言,构造两张"相似但不相同"的图像的一种可行方法是采样。在原图的相邻但不相同的位置采样出来的子图很显然满足了相互之间的差异很小,但是其对应的干净图像并不相同的条件()。给定含噪图像y,我们从中采样两次得到噪声对
,用n2n的方式可以得到:
直接用Noise2Noise的方法训练得到的结果不是理想结果,且容易导致过度平滑。因此Neighbor2Neighbor考虑在其上加正则项进行约束。经过推导得到:
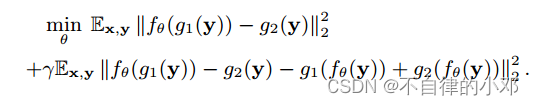
网络流程图:
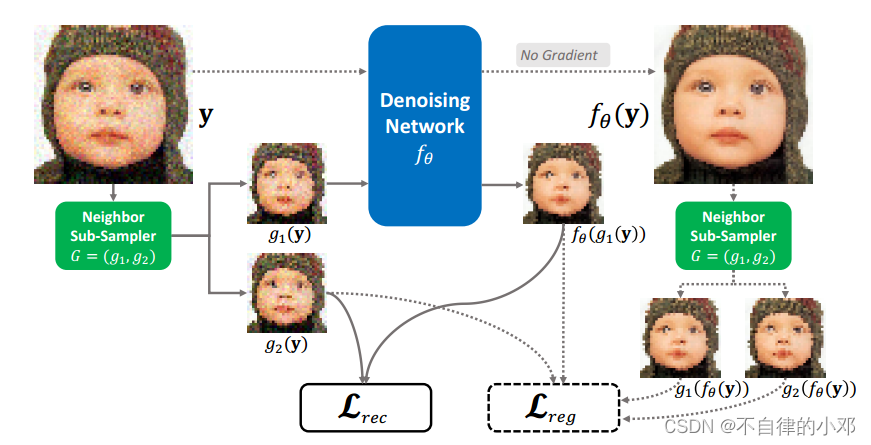
具体流程:将图像进行下采样,
,将原图y输入网络
去噪后也进行下采样得到
,
,而
输入网络
得到
,最后根据公式计算损失。
其中值得介绍的是下采样器,文中的下采样器是邻近像素下采样器:

采样规则是对一个小块(patch)中的不同像素进行选择,不断移动patch块,直到采样结束。这种方法在原图的相邻但不相同的位置采样出子图,很显然满足了相互之间差异很小的条件,从而满足Neighbor2Neighbor的前提。
思考:
优点:单张照片即可去噪。在noise2noise的loss基础上加入正则项,也就是利用了去噪过后的图片信息。
缺点:子采样后的图片会丢失信息,使得一些细节无法还原。
下采样会使得原始图像的信息丢失,那么是否有能够解决的方法呢?我个人的想法是使用超分辨率重建的方法对原始噪声图片进行超分辨率重建,生成2x的图片,然后在进行下采样,这样就能够尽可能的减少信息的丢失。但是这样也会有新的问题产生:超分方法选择哪一个,如果这种方法要保证超分给出的图像是尽可能的好,才会有好的效果,不然可能效果还不如ne2ne。
本人已经在实施方法过程中,但效果不是特别好,并且会有预测结果波动的现象,得想想怎么解决。等后续......















 1796
1796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









