







参考:
1.稀疏表示:https://www.cnblogs.com/yifdu25/p/8128028.html
2.K-SVD : https://blog.csdn.net/chlele0105/article/details/16886795
3.OMP : https://www.cnblogs.com/yifdu25/p/8385204.html
4.https://www.cnblogs.com/yifdu25/p/8128028.html
5.MP的实例 https://korediantousman.staff.telkomuniversity.ac.id/files/2017/08/main.pdf
6.K-SVD https://www.cnblogs.com/salan668/p/3555871.html
7.OMP与MP算法: https://blog.csdn.net/scucj/article/details/7467955
1. 稀疏表示
稀疏表示(sparse representation)假设自然信号可以被一个字典的原子(基)稀疏的线性组合近似表示。即y≈Dα,这里 y ∈ R n y∈R^{n} y∈Rn表示信号, α ∈ R K α∈R^{K} α∈RK表示稀疏系数, D ∈ R n × K D∈R^{n×K} D∈Rn×K表示是过完备字典。向量α只具有很少的非0值,这便是稀疏的含义。之所以需要字典,是因为一般的自然信号x本身并不是稀疏的,往往需要在某种稀疏基上才可以进行稀疏表示。所以稀疏表示的关键是在某种基(字典)下的系数稀疏,而这些字典与图像本身密切相关,可以将字典看做是组成图像的基本信息。也就是说在稀疏表示中我们把字典当成一种变换域,在该变换中信号的表示是稀疏的。该问题用公式表述为:
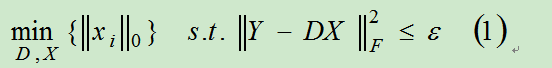
其中 Y ∈ R n × M Y∈R^{n×M} Y∈Rn×M表示样本矩阵,每一列代表一个patch,M个样本, D = { d 1 , d 2 , . . . d K } ∈ R n × K D=\{d_{1},d_{2},...d_{K}\}∈R^{n×K} D={
d1,d2,...dK}∈Rn×K表示字典,每一列代表一个原子,K个原子, X ∈ R K × M X∈R^{K×M} X∈RK×M表示系数矩阵,每一列 x i x_{i} xi对应一个样本在该字典上的系数,ε表示重构误差。对于表示一个信号使用字典稀疏表示的情况如下。
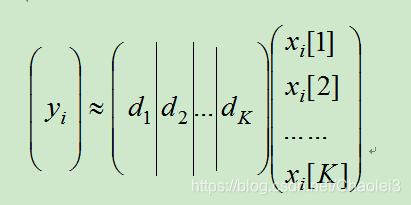
在这里,稀疏性表现在 x i x_{i} xi的系数大部分都是0,而只有很少的非0值。
由于求解0范数是非凸的问题,而在一定条件下,0范数问题可以转化为1范数求解,所以(1)式也可以转化为:
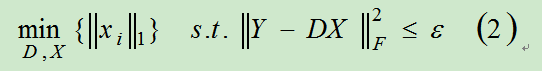
1.1 字典的生成方式
通常有2种生成字典的方式,一种基于分析模型(pre-constructed),比如利用傅立叶基,小波基(WT),离散余弦变换(DCT)基,Gabor基,Contourlet基,等等。依靠这种方法生成的字典结构良好,数值计算快速。但是这种字典具有局限性,只能表示某种类型的信号,过度依赖于图像的几何特征,并且只有少数图像块可以用稀疏的原子组合来表示。另一种基于学习模型,将图像分成一个个小patch,通过训练样本得到字典。由这种方法得到的字典具有很好的适应性,能够捕捉图像的几何特征。相较于第一种往往表现更好。
1.2 字典的种类
而从字典的形式上看,通俗的说就是从字典的长和宽的对比,字典又可以分成3种:过完备字典(n<K),即原子个数要远远大于信号的维度,这种情况在稀疏表示中最常见,完备字典(n=K)例如傅里叶变换和DCT变换都是这种情况和欠完备字典(n>K)[4]。通常我们使用的都是过完备字典。那么为什么通常都要求过完备字典呢?参考别人的说法,如果n<K,这个方程要么有无穷多个解(当增广矩阵[D,y]的秩=矩阵[D]的秩时),要么无解(当增广矩阵[D,y]的秩>矩阵[D]的秩时)。可能在方程有无穷多解的时候更容易找到更适合的稀疏系数。这大概就是过完备性字典的优点。
1.3 稀疏表示的相关算法
从上面的讲解来看稀疏表示其实就是在求解式(1),但由于其中只有Y是已知的,而D和X都是未知的,这里就涉及到2个问题,1)如何对信号进行稀疏表示,即如何求稀疏系数 x i x_{i} xi?2)如何根据样本生成字典,即如何求解D?概括地说,我们可以使用任何追踪算法来求解稀疏系数 x i x_{i} xi,例如MP,OMP(正交匹配追踪算法),BasisPursuit (BP),FocalUnderdetermined System Solver (FOCUSS)。而更新字典最常用的就是K-SVD算法。
2. 如何稀疏表示
2.1 MP算法
这里借用[3]的博客的内容来讲解MP算法。假设有这样一个问题:要使用OB,OC,OD来表示OA。这里OB,OC,OD就相当于字典,OA相当于要稀疏表示的信号。那么应该如何求解才能达到使用最少的向量近似表示OA呢?答案是每次将OA投影到各个向量上,选择OA投影最大的那个向量表示原信号会在当前情况下保存信号最多的信息。
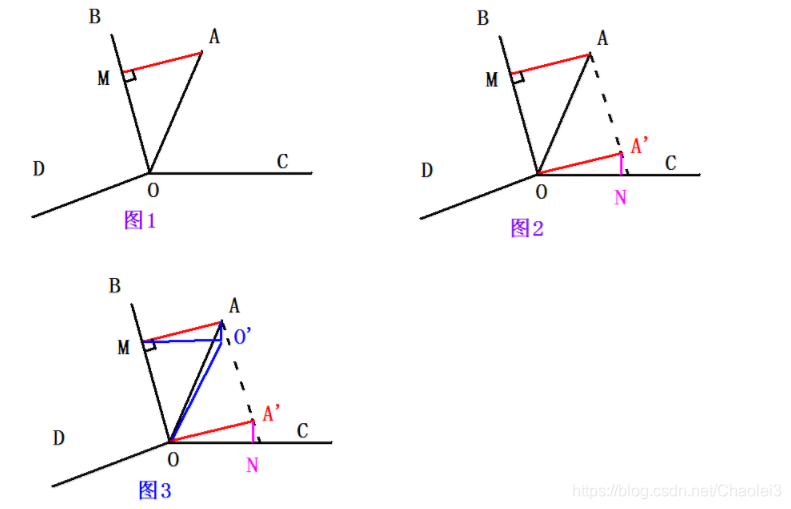 1)如图1,将OA向OB,OC,OD分别进行投影,发现OA在OB上的投影最大,这样OA就被分成投影向量OM和残差向量MA。假设 O M O B = a \frac{OM} {OB} =a OBOM=a,那么OA=a OB+MA;2)然后继续对残差MA进行分解,和第一步一样将MA向各个向量上投影,如图2,发现MA在OC向量上的投影最大,则选择OC来表示MA,并且假设 O N O C = b \frac{ON} {OC} =b OCON=b,此时 M A = b ∗ O C + N A ′ MA =b*OC+N A^{'} MA=b∗OC+NA′,3)假设此时会有2种情况, [1]发现残差仍然大于阈值ε,那么就按照第一步继续分解,直到残差小于阈值。[2]发现残差已经小于阈值了,那么此时 O A = a ∗ O B + b ∗ O C + N A ′ OA = a*OB +b*OC +NA^{'} OA=a∗
1)如图1,将OA向OB,OC,OD分别进行投影,发现OA在OB上的投影最大,这样OA就被分成投影向量OM和残差向量MA。假设 O M O B = a \frac{OM} {OB} =a OBOM=a,那么OA=a OB+MA;2)然后继续对残差MA进行分解,和第一步一样将MA向各个向量上投影,如图2,发现MA在OC向量上的投影最大,则选择OC来表示MA,并且假设 O N O C = b \frac{ON} {OC} =b OCON=b,此时 M A = b ∗ O C + N A ′ MA =b*OC+N A^{'} MA=b∗OC+NA′,3)假设此时会有2种情况, [1]发现残差仍然大于阈值ε,那么就按照第一步继续分解,直到残差小于阈值。[2]发现残差已经小于阈值了,那么此时 O A = a ∗ O B + b ∗ O C + N A ′ OA = a*OB +b*OC +NA^{'} OA=a∗
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 201
201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









