







1、数据初始化,以及删除含缺失值行
import pandas as pd
#不读取首列为列名;将?替换为NaN
masses=pd.read_csv('mammographic_masses.data.txt',header=None,na_values='?')
masses.head()
masses.columns=["BI_RADS","age","shape","margin","density","severity"]
masses.head()
#做描述性统计
masses.describe()
#通过展示含缺失值行,判断缺失值在变量分布是否均匀,决定是否删除含缺失值行,避免因某一特征缺失值较多造成该特征的信息损失
masses.loc[(masses['age'].isnull())|
(masses['shape'].isnull())|
(masses['margin'].isnull())|
(masses['density'].isnull())]
#发现缺失值分布较均匀,删除含缺失值行
#masses=masses.dropna(axis=0)
#善用inplace选项,axis=1表示删除含缺失值列
masses.dropna(axis=0, inplace=True)
masses.describe()
#使用values直接将dataframe转化为numpy
#我的做法:dataframe.to_numpy
N_masses=masses.to_numpy()
Feature=N_masses[:,0:4]
Severity=N_masses[:,5]
#values做法
all_features = masses.iloc[:,0:4].values
all_classes = masses.iloc[:,5].values
feature_names = list(masses.columns.values)
#Z_score标准化:将数据标准化为标准正态分布
from sklearn import preprocessing
scaler=preprocessing.StandardScaler()
all_features_scaled = scaler.fit_transform(all_features)
all_features_scaled
2、Decision Trees
(1) Train_test_split分割样本
#train_test_split分割样本
#我的方法手动分割样本
#train=N_masses[:620,:]
#test=N_masses[620:,:]
#教程方法:自动分割样本, train_test_split
from sklearn.model_selection import cross_val_score, train_test_split
import numpy
numpy.random.seed(1234)
(training_inputs,
testing_inputs,
training_classes,
testing_classes) = train_test_split(all_features, all_classes, train_size=0.75, random_state=1)
#random_state=1, 表示多次split的train和test一致(2) Train the decision tree
#训练模型
from sklearn import tree
clf = tree.DecisionTreeClassifier(random_state=1)
clf = clf.fit(training_inputs,training_classes)
#显示Decision Tree
from IPython.display import Image
from sklearn.externals.six import StringIO
import pydotplus
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data,
feature_names=feature_names)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())(3) Measuring the result
clf.score(testing_inputs, testing_classes)3、K-Fold cross validation + Decision Tree
(1) 简介:
模型参数选择往往取决于test的结果,即造成了前视偏差和overfitting。因此,我们使用validation选择最佳参数,并将该参数用于最终的test。
但是,因为将dataset分为三部分:train、validation以及test,造成可用样本量减少,并且train和validation样本量的随机选择也会影响到test的结果。
因此,K-fold cross validation应运而生。通过将trainK等分,并从中仍迭代选择一等分作为validation,根据其平均值选择模型参数,既避免了前视偏差,也解决了样本量不足。

(2) 代码
#K-Fold方法直接给定整个数据集,且使用了标准化的数据
from sklearn.model_selection import cross_val_score, train_test_split
clf = DecisionTreeClassifier(random_state=1)
cv_scores= cross_val_score(clf, all_features_scaled, all_classes, cv=10)
#计算十种validation抽样方法得分均值
cv_scores.mean()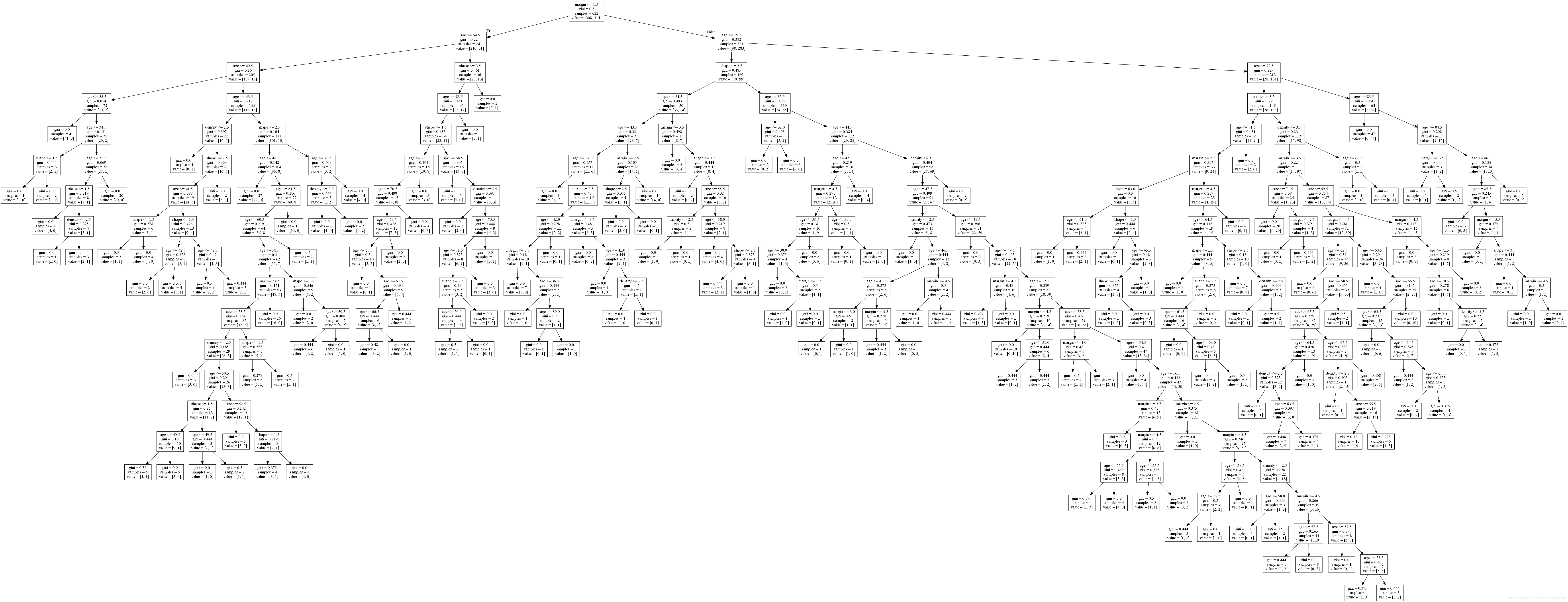
4、K-Fold cross validation + RandomForest
(1) 简介
随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支–集成学习(Ensemble Learning)方法。
从直观角度来解释,每棵树都是一个分类器(假设现在为分类问题),那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,这就是一种最简单的Bagging思想。
(2) 随机森林的生成过程
从原始训练集中使用Bootstraping方法随机有放回采用选出m个样本,共进行n_tree次采样,生成n_tree个训练集;
对于n_tree个训练集,分别训练n_tree个决策树模型;
对于单个决策树模型,假设训练样本特征的个数为n,那么每次分裂时根据信息增益/信息增益比/Gini指数选择最好的特征进行分裂;
每棵树都一直这样分裂下去,直到该节点的所有训练样例都属于同一类。在决策树的分裂过程中不需要剪枝;
将生成的多棵决策树组成随机森林。对于分类问题,按多棵树分类器投票决定最终分类结果;对于回归问题,由多棵树预测的均值决定最终预测结果。
(3) 代码
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=30, random_state=1)
cv_scores= cross_val_score(clf, all_features_scaled, all_classes, cv=10)
cv_scores.mean()5、SVM.SVC: Support Vector Classification
from sklearn import svm
svc = svm.SVC(kernel='linear', C=1)#分为两类,设置C=1
cv_scores= cross_val_score(svc, all_features_scaled, all_classes, cv=10)
cv_scores.mean()
svc = svm.SVC(kernel='rbf', C=1)
cv_scores= cross_val_score(svc, all_features_scaled, all_classes, cv=10)
cv_scores.mean()
svc = svm.SVC(kernel='sigmoid', C=1)
cv_scores= cross_val_score(svc, all_features_scaled, all_classes, cv=10)
cv_scores.mean()
svc = svm.SVC(kernel='poly', C=1)#分为两类,设置C=1
cv_scores= cross_val_score(svc, all_features_scaled, all_classes, cv=10)
cv_scores.mean()6、K-Nearest-Neighbors
from sklearn.neighbors import KNeighborsClassifier
neigh = KNeighborsClassifier(n_neighbors=10)
cv_scores= cross_val_score(neigh, all_features_scaled, all_classes, cv=10)
cv_scores.mean()
#select best K-value
for K in range (1,51):
neigh = KNeighborsClassifier(n_neighbors=K)
cv_scores= cross_val_score(neigh, all_features_scaled, all_classes, cv=10)
print (K, cv_scores.mean())7、Naive_Bayes.MultinomialNB: 先验为多项式分布的朴素贝叶斯
(1) 算法介绍
https://blog.csdn.net/TeFuirnever/article/details/100108341
(2) 代码
from sklearn.preprocessing import MinMaxScaler
from sklearn.naive_bayes import MultinomialNB
#Naive_Bayes需归一化处理
scaler = MinMaxScaler()
all_features_minmax = scaler.fit_transform(all_features)
cla = MultinomialNB()
cv_scores= cross_val_score(cla, all_features_minmax, all_classes, cv=10)
cv_scores.mean()8、Logistic Regression
(1) 算法
https://blog.csdn.net/guoziqing506/article/details/81328402
(2) 代码
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
cv_scores= cross_val_score(clf, all_features_scaled, all_classes, cv=10)
cv_scores.mean()9、Neural Network
from tensorflow.keras.wrappers.scikit_learn import KerasClassifier
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
def create_model():
model = Sequential()
model.add(Dense(10, input_dim=4, kernel_initializer='normal', activation='relu'))
model.add(Dense(1, kernel_initializer='normal',dropout=0.8, activation='softmax'))
model.compile(loss='binary_crossentropy',optimizer=RMSprop(),metrics=['accuracy'])
return model
estimator = KerasClassifier(build_fn=create_model, epochs=100, verbose=0)
cv_scores= cross_val_score(clf, all_features_scaled, all_classes, cv=10)
cv_scores.mean()

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









