









信息论:
信息论的主要内容类比人类的语言
常用词汇比不常用词汇短
知道一句话的重点单词,即可知道这句话的大致含义。
鲁棒性:
信息论的基本研究课题,信源编码(发出信息)、信道编码(传输信息)
信息论不会考虑信息的重要性或者内在意义。
决策树背后的思想:
利用一种度量方法来衡量一种“数据划分”的优劣,从而生成一个“判定序列”,不断的寻求数据划分的方法,使得在该划分下能够获得的信息量最大。
不确定性:
获得信息量的度量方法是从反方向来定义的
若一种划分能使数据的不确定性最少得越多,这就意味着该划分能够获得更多信息。
度量标准:信息熵、基尼系数
信息熵:
公式:
公式思想:频率估计概率
公式对数的底取值为2,则信息熵的单位为bit。底取值为e,则单位为nat
基尼系数:
基尼系数介于0-1之间,基尼系数越大,表示不平等程度越高。
熵:
熵的本质是香农信息量 log(1/p) 的期望
最短平均编码长度
- 交叉熵: 交叉熵是用于度量两个分部距离
用来衡量在给定的真实分布下,使用非真实分布所指定的策略消除系统的不确定性所需要付出的努力的大小。
交叉熵越低,这个策略就越好
最小化交叉熵,因为交叉熵越低,就证明由算法所产生的策略最接近最优策略,也间接证明我们算法所算出的非真实分布越 接近真实分布。
- 信息熵:信息熵代表的是随机变量或整个系统的不确定性,熵越大,随机变量或系统的不确定性就越大。
- 相对熵:其用来衡量两个取值为正的函数或概率分布之间的差异
相对熵 = 交叉熵 - 信息熵
KL散度(Kullback–Leibler divergence),用于衡量两个概率分布之间的差异。
信息的增益:
信息增益 = 获得信息
设A为特征,有数据集D={(A1,y1),…,(AN,yN)}
条件熵定义信息熵:
条件熵:根据特征的不同取值对y进行限制后,先对这些被限制的y分别计算信息熵,再把信息熵根据特征取值本身的概率加权求和,得到总的条件熵。
条件熵是由特征不同的取值限制的各个部分的y的不确定性以取值本身的概率作为权重加总得到。
从条件熵的直观含义,信息的增益自然地定义为:
g(y,A)=H(y) – H(y|A),g(y,A)为互信息
我们希望得到决策树应该是比较深的,但是不能过深,从而它可以基于多个方面而不是片面的根据某些特征来判断
决策树的生成:
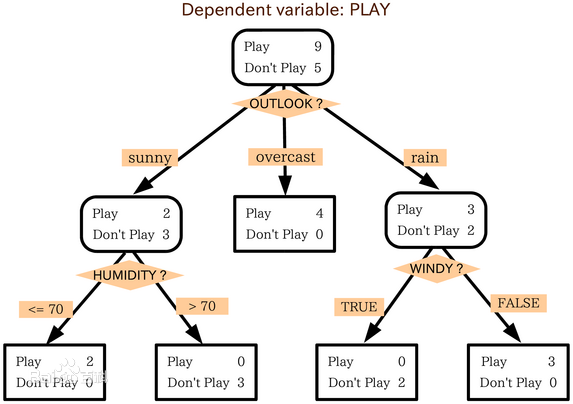
解图:
菱形方框作为划分标准的特征
长方形方框为对应特征的各个取值
节点:根节点(root)、叶子结点(角为圆弧)、非叶子节点(下属的节点)
箭头:箭头起点是终点的父节点,终点是起点的子节点、还有左右节点
每个叶节点都对应着原样本空间的一个子空间,这些叶节点不会相交,且并起来构成完整的样本空间。
决策树行为:
将样本空间划分为若干个互不相交的子空间
给每个子空间贴一个类别标签
基本算法:
ID3:最朴素的决策树算法,对离散型数据分类的解决方案
C4.5:对混合型数据分类的解决方案
CART:对数据的回归的解决方案
核心思想:
算法通过不断的划分数据集来生成决策树,其中每一步的划分能够使当前的信息增益达到最大
模型的损失就是数据集的不确定性,模型的算法就最小化该不确定性。
决策树的生成过程:
向根节点输入数据
根据信息增益的度量,选择数据的某个特征来数据划分成好几份并分别喂给新的node
如果分完数据后发现:
某份数据的不确定性较小,即其中某一类别的样本已经占了大多数,此时不再对这份数据继续划分,将其转化为叶子结点
某份数据不确定性较大,继续划分
ID3(Interactive Dichotomizer-3,交互式二分法):
该方法适用于“多分”不止二分,选择互信息作为信息增益的度量,针对离散型数据划分
C4.5:
可以处理ID3比较难处理的混合型数据
先选出互信息比平均互信息要高的特征,从这些特征中选出信息增益比最高的
有可能产生过拟合现象
CART(Classification and Regression Tree,分类与回归树):
即可分类又可回归
使用基尼增益作为信息增益的度量
假设最终生成的决策树为二叉树,处理离散型特征时会通过决出二分标准老划分数据
回归问题:特征连续,类别连续,把类别向量改为输出向量,将损失定义为平方损失
过拟合和剪枝:
模型越复杂越容易出现过拟合现象,决策树利用剪枝解决过拟合问题
剪枝:
预剪枝:根据停止条件进行提前剪枝
后剪枝:决策树生成完毕后再进行修剪,从全局出发,通过某种标准,剪掉多余部分
局部剪枝的标准,两种做法:
应用交叉验证的思想,若局部剪枝能使模型在测试集上的错误率降低,则进行局部剪枝
应用正则化的思想,综合考虑不确定性和模型的复杂度定义一个新的损失,用该损失作为一个node是否进行局部剪枝的标准
正则化剪枝的数学描述:
定义新损失
直接比较一个node局部剪枝钱的损失和局部剪枝后的损失达到大小,若局部剪枝前的损失小于局部剪枝后的损失,就对该node进行局部剪枝
获取一系列的剪枝阈值,在每个剪枝阈值上对相应的node进行局部剪枝并将局部剪枝后得到的决策树存储在一个列表中。
通过交叉验证选出最好的决策树作为最终生成的决策树
ID3,C4.5的剪枝算法:
稍后补上
CART剪枝:
稍后补上















 6412
6412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









