






1.需求分析
使用Ultralytics工具下的YOLO检测算法,并部署到国产RK3588开发板测试下效果。
本文使用的是yolov8-p2训练完的模型作为参考。
2.项目梳理
训练的过程可以参考Ultralytics官网给出的教程,这里直接跳过。
yolo训练完的pt模型转换为ONNX模型,使用rknn修改后的ultralytics_yolov8项目到本地:ultralytics_yolov8,这里是借鉴了ultralytics_yolov8项目修改的代码,在本地ultralytics项目直接进行修改。
环境部署代码使用到官方rknn-toolkit2工具,ONNX转换为RKNN模型需要使用官方rknn_model_zoo-2.3.0,板端运行代码使用的rknn3588-yolov8。这里的rknn-toolkit2是v2.2.0,rknn_model_zoo使用的2.3.0版本。
3.pt->onnx
pt转onnx的过程Ultralytics提供了对应的代码,但是使用官方提供的代码无法转换出适配瑞芯微官方部署文件的rknn模型,所以先进行代码的修改,也可以下载上面提到ultralytics_yolov8项目直接进行pt转onnx。
3.1 ultralytics_yolov8项目直接转换
配置好环境后运行
from ultralytics import YOLO
model = YOLO('path/to/your/xx.pt')
results = model.export(format='rknn')注意这里的format=’rknn‘,不是onnx。但是后续导出的还是onnx模型。
3.2 修改最新的ultralytics代码进行转换
3.2.1 找到ultralytics/engine/exporter.py文件
修改export_formats函数
def export_formats():
"""Ultralytics YOLO export formats."""
x = [
["PyTorch", "-", ".pt", True, True],
["TorchScript", "torchscript", ".torchscript", True, True],
["ONNX", "onnx", ".onnx", True, True],
["OpenVINO", "openvino", "_openvino_model", True, False],
["TensorRT", "engine", ".engine", False, True],
["CoreML", "coreml", ".mlpackage", True, False],
["TensorFlow SavedModel", "saved_model", "_saved_model", True, True],
["TensorFlow GraphDef", "pb", ".pb", True, True],
["TensorFlow Lite", "tflite", ".tflite", True, False],
["TensorFlow Edge TPU", "edgetpu", "_edgetpu.tflite", True, False],
["TensorFlow.js", "tfjs", "_web_model", True, False],
["PaddlePaddle", "paddle", "_paddle_model", True, True],
["NCNN", "ncnn", "_ncnn_model", True, True],
['RKNN', 'rknn', '_rknnopt.torchscript', True, False],
]
return dict(zip(["Format", "Argument", "Suffix", "CPU", "GPU"], zip(*x)))在190到200行左右,修改

300行左右,添加

if rknn:
f[12], _ = self.export_rknn()400行左右,添加export_rknn函数
@try_export
def export_rknn(self, prefix=colorstr('RKNN:')):
"""YOLOv8 RKNN model export."""
LOGGER.info(f'\n{prefix} starting export with torch {torch.__version__}...')
# ts = torch.jit.trace(self.model, self.im, strict=False)
# f = str(self.file).replace(self.file.suffix, f'_rknnopt.torchscript')
# torch.jit.save(ts, str(f))
f = str(self.file).replace(self.file.suffix, f'.onnx')
opset_version = self.args.opset or get_latest_opset()
torch.onnx.export(
self.model,
self.im[0:1,:,:,:],
f,
verbose=False,
opset_version=12,
do_constant_folding=True, # WARNING: DNN inference with torch>=1.12 may require do_constant_folding=False
input_names=['images'])
LOGGER.info(f'\n{prefix} feed {f} to RKNN-Toolkit or RKNN-Toolkit2 to generate RKNN model.\n'
'Refer https://github.com/airockchip/rknn_model_zoo/tree/main/models/CV/object_detection/yolo')
return f, None3.2.2 找到ultralytics/nn/autobackend.py文件
AutoBackend类下,添加
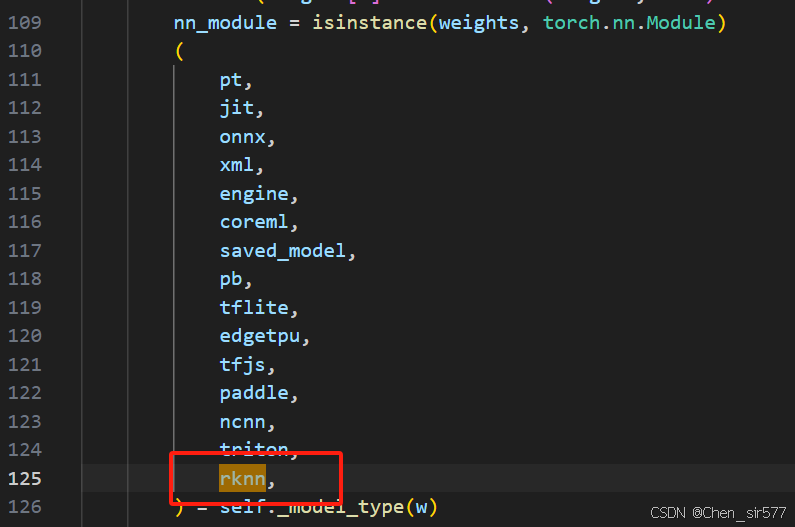
然后往下添加
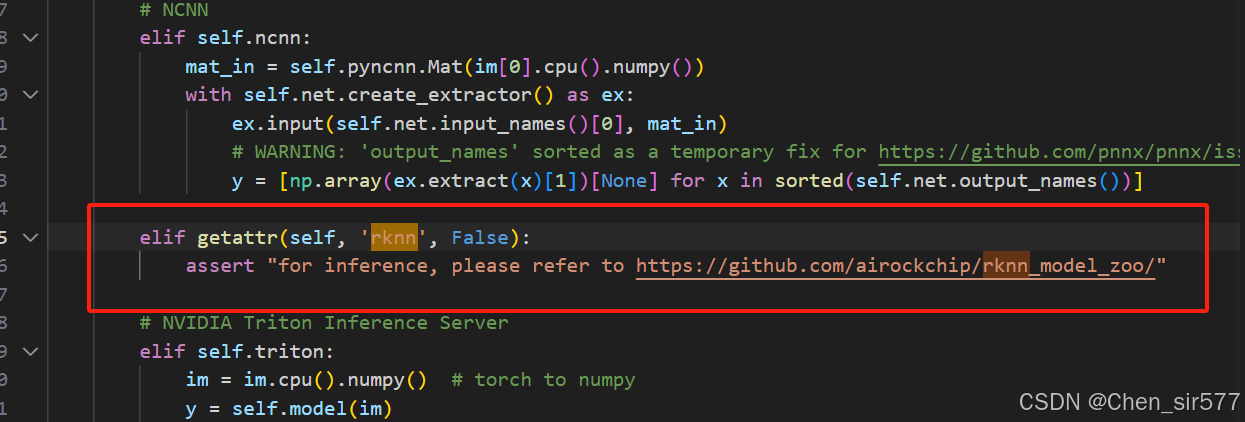
elif getattr(self, 'rknn', False):
assert "for inference, please refer to https://github.com/airockchip/rknn_model_zoo/"3.2.3 找到ultralytics/nn/modules/head.py文件
修改Detect类的forward函数
def forward(self, x):
"""Concatenates and returns predicted bounding boxes and class probabilities."""
#------------rknn--------------
if self.export and self.format == 'rknn':
y = []
for i in range(self.nl):
y.append(self.cv2[i](x[i]))
cls = torch.sigmoid(self.cv3[i](x[i]))
cls_sum = torch.clamp(cls.sum(1, keepdim=True), 0, 1)
y.append(cls)
y.append(cls_sum)
return y
if self.end2end:
return self.forward_end2end(x)
for i in range(self.nl):
x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)
if self.training: # Training path
return x
y = self._inference(x)
return y if self.export else (y, x)修改Segment类的forward函数
def forward(self, x):
"""Return model outputs and mask coefficients if training, otherwise return outputs and mask coefficients."""
p = self.proto(x[0]) # mask protos
bs = p.shape[0] # batch size
#-----------rknn--------------
if self.export and self.format == 'rknn':
mc = [self.cv4[i](x[i]) for i in range(self.nl)]
else:
mc = torch.cat([self.cv4[i](x[i]).view(bs, self.nm, -1) for i in range(self.nl)], 2) # mask coefficients
#mc = torch.cat([self.cv4[i](x[i]).view(bs, self.nm, -1) for i in range(self.nl)], 2) # mask coefficients
x = Detect.forward(self, x)
if self.training:
return x, mc, p
#-----------rknn--------------
if self.export and self.format == 'rknn':
bo = len(x)//3
relocated = []
for i in range(len(mc)):
relocated.extend(x[i*bo:(i+1)*bo])
relocated.extend([mc[i]])
relocated.extend([p])
return relocated
return (torch.cat([x, mc], 1), p) if self.export else (torch.cat([x[0], mc], 1), (x[1], mc, p))
修改OBB类的forward函数
def forward(self, x):
"""Concatenates and returns predicted bounding boxes and class probabilities."""
bs = x[0].shape[0] # batch size
angle = torch.cat([self.cv4[i](x[i]).view(bs, self.ne, -1) for i in range(self.nl)], 2) # OBB theta logits
#-----------rknn--------------
if self.export and self.format == 'rknn':
x = Detect.forward(self, x, "Obb")
return [x, angle.sigmoid()]
# NOTE: set `angle` as an attribute so that `decode_bboxes` could use it.
angle = (angle.sigmoid() - 0.25) * math.pi # [-pi/4, 3pi/4]
# angle = angle.sigmoid() * math.pi / 2 # [0, pi/2]
if not self.training:
self.angle = angle
x = Detect.forward(self, x)
if self.training:
return x, angle
return torch.cat([x, angle], 1) if self.export else (torch.cat([x[0], angle], 1), (x[1], angle))
修改Pose类的forward函数
def forward(self, x):
"""Perform forward pass through YOLO model and return predictions."""
bs = x[0].shape[0] # batch size
kpt = torch.cat([self.cv4[i](x[i]).view(bs, self.nk, -1) for i in range(self.nl)], -1) # (bs, 17*3, h*w)
#-----------rknn--------------
if self.export and self.format == 'rknn':
output_x = Detect.forward(self, x, 'Pose')
y = []
y.append(output_x)
self.export = False
x = Detect.forward(self, x)
self.export = True
pred_kpt = self.kpts_decode(bs, kpt)
y.append(pred_kpt)
return y
else:
x = Detect.forward(self, x)
#x = Detect.forward(self, x)
if self.training:
return x, kpt
pred_kpt = self.kpts_decode(bs, kpt)
return torch.cat([x, pred_kpt], 1) if self.export else (torch.cat([x[0], pred_kpt], 1), (x[1], kpt))
至此代码修改完成。
然后新建一个py文件,运行代码
from ultralytics import YOLO
model = YOLO('path/to/your/xx.pt')
results = model.export(format='rknn')
可以在对应目录看到导出的onnx模型,这里注意查看下对应的模型结构,使用netron查看
yolo11s.onnx
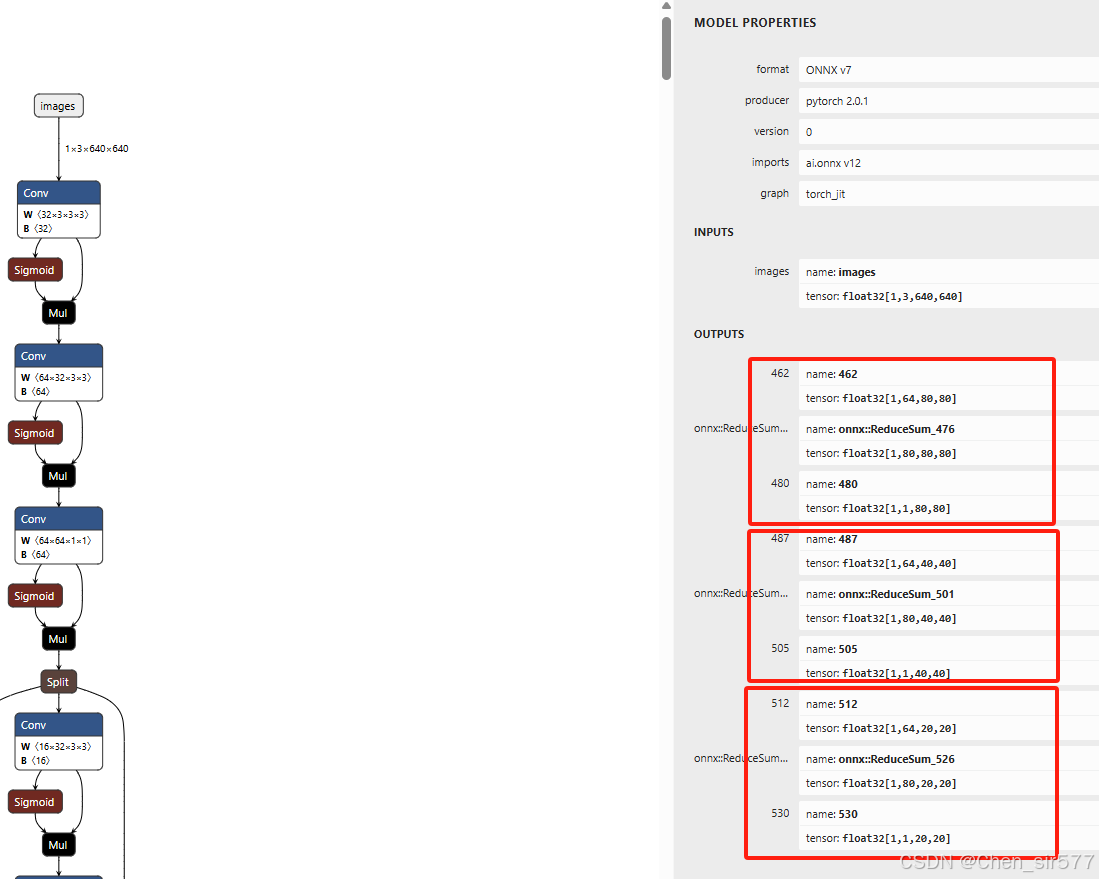
这里三个红框很重要,对应了几个大小的检测头,这里是80x80,40x40,20x20的,如果使用的yolov8-p2的模型就是4个检测头,多了一个160x160。
yolov8s-p2.onnx模型
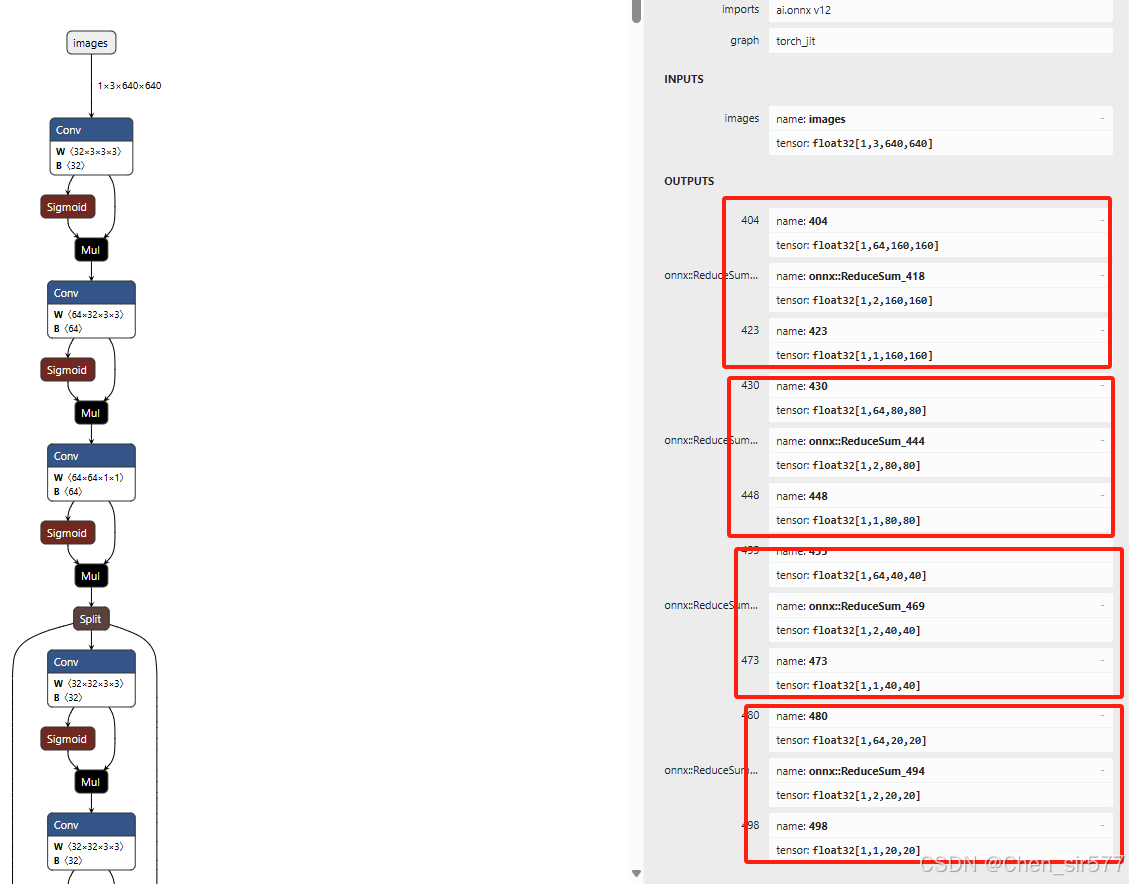
至此onnx转换完成。
4. onnx->rknn
4.1 环境准备
虚拟机Ubuntu20.04
将下载好的rknn-toolkit2和rknn_model_zoo-2.3.0拷贝到Ubuntu下解压。
配置conda环境,下载Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh一路点空格,然后yes,回车完成安装。
打开终端,输入以下命令安装Python版本为3.8的环境。
conda create -n rknn python=3.8进入到rknn-toolkit2-master/rknn-toolkit2/packages文件夹下。
首先先安装所用到的依赖包,在终端输入
pip install -r requirements_cp38-2.2.0.txt这里如果创建环境和pip安装缓慢可以参考文章conda和pip换源。
接着安装rknn-toolkit2
pip install rknn_toolkit2-2.2.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl至此rknn转换环境配置完成。
4.2 RKNN转换
进入rknn环境
conda activate rknn 打开准备好的rknn_model_zoo-2.2.0文件夹,进入到examples/yolov8/python文件夹下。
修改yolov8.py和convert.py中的内容.(这里根据自己选择的模型进行转换,rknn_model_zoo提供了绝大部分的yolo案例)
yolov8.py
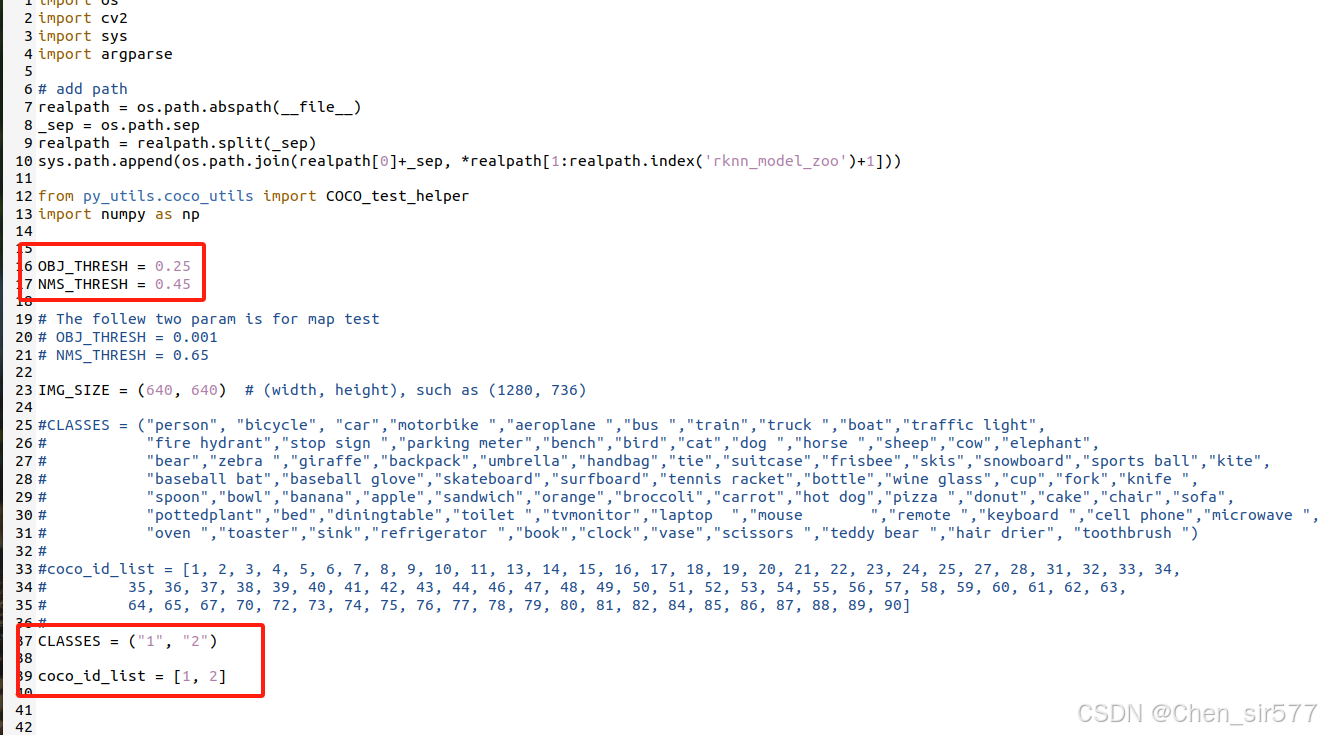
OBJ_THRESH,置信度阈值。提高OBJ_THRESH会减少检测到的框的数量,会增加检测的准确性;降低OBJ_THRESH会增加检测到的框的数量,可能会包含更多的误检。
NMS_THRESH,非极大值抑制。较高的NMS_THRESH值允许更多重叠的框存在,而较低的值则会导致更多重叠框被抑制。
还需要修改 platform_target,根据所使用的设备进行填写。我这里使用的是rk3588的板子。现支持[rk3562,rk3566,rk3568,rk3576,rk3588,rk1808,rk1109,rk1126]
convert.py
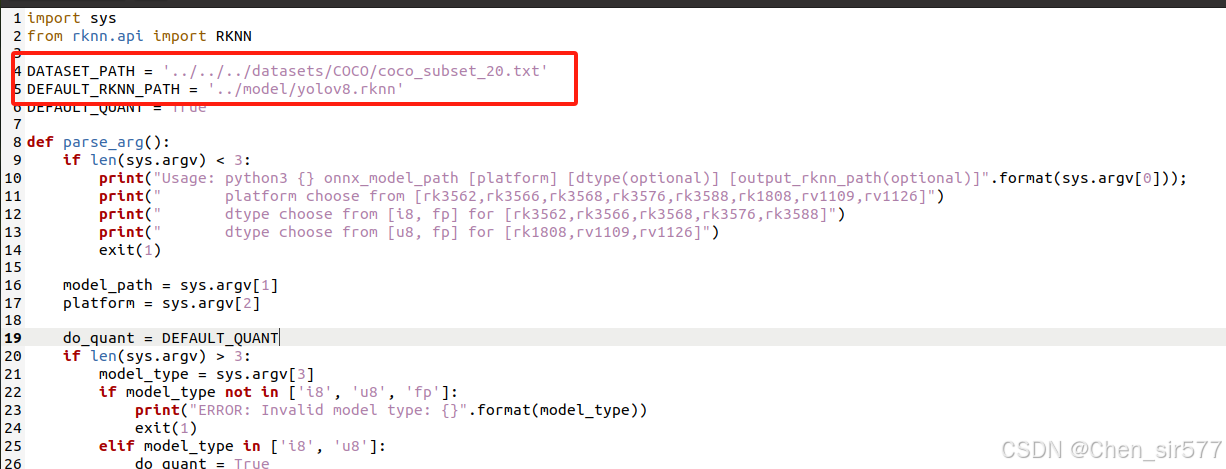
这里就是俩个路径的修改。
然后终端输入
python convert.py your.onnx rk3588 
在上一级目录下的model文件夹下得到对应rknn模型。
此时也可以使用netron查看模型的结构。这里是yolov8s-p2的rknn模型,对应之前图片的四个红框。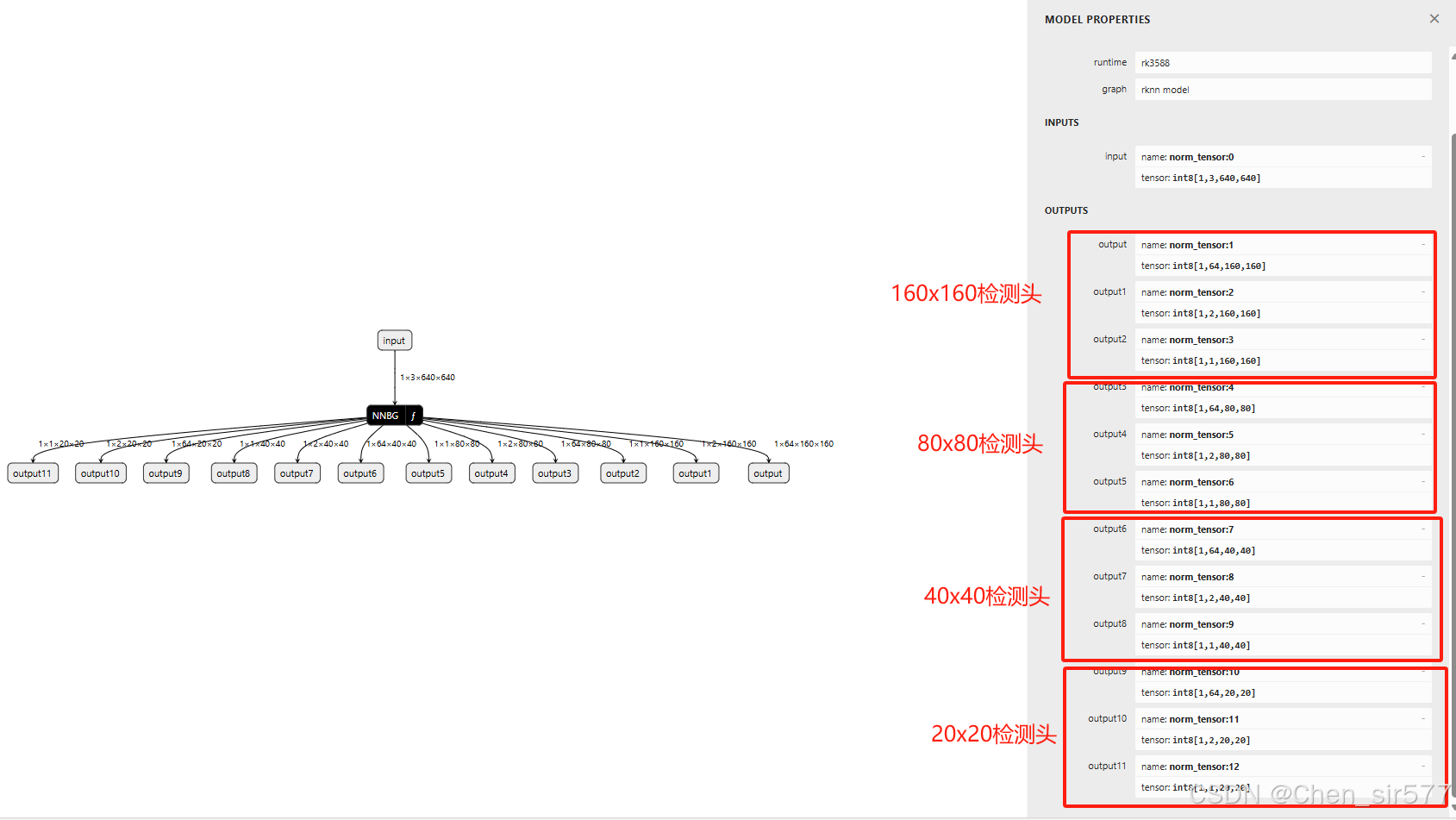
至此rknn模型也准备好了。
5.RK3588上rknn模型部署和识别
5.1环境配置
事先准备:将下载好的rknn-toolkit2-master文件下的rknpu2和rknn-toolkit-lite2拖到设备中的目录下。
5.1.1 NPU驱动升级
使用以下命令来升级 RKNPU2 Runtime 库
cp ~/rknpu2/runtime/Linux/librknn_api/aarch64/librknnrt.so /usr/lib/librknnrt.so因为rknn-toolkit2-2.0版本没有librknn_api.so,所以需要使用以下命令创建一个软连接到librknnrt.so。首先要在 /usr/lib下删除旧版本的librknn_api.so(如果有这个的话)。
sudo ln -s /usr/lib/librknnrt.so /usr/lib/librknn_api.so5.1.2 配置python运行环境
创建一个python=3.10的环境。见4.1 环境准备,下载对应的linux下的包,配置conda环境
conda create -n rknn python=3.10在rknn-toolkit-lite2/packages文件下安装rknn_toolkit_lite2-2.2.0包。
pip install rknn_toolkit_lite2-2.2.0-cp310-cp310-linux_aarch64.whl接着安装opencv
pip install opencv_contrib_python至此运行环境配置完毕。
5.2 rknn3588-yolov8代码运行
将下载的rknn3588-yolov8代码部署到板端,修改对应的main.py和func.py文件的模型和文件路径即可。这里注意,默认的代码是是对应三个检测头的输出,如果要使用四个检测头输出需要修改func.py中的代码。
修改适应四个检测头(20x20、40x40、80x80、160x160)的输出的func.py
import cv2
import numpy as np
OBJ_THRESH, NMS_THRESH, IMG_SIZE = 0.25, 0.45, 640
CLASS = ("1", "2")
def filter_boxes(boxes, box_confidences, box_class_probs):
"""Filter boxes with object threshold.
"""
box_confidences = box_confidences.reshape(-1)
candidate, class_num = box_class_probs.shape
class_max_score = np.max(box_class_probs, axis=-1)
classes = np.argmax(box_class_probs, axis=-1)
_class_pos = np.where(class_max_score* box_confidences >= OBJ_THRESH)
scores = (class_max_score* box_confidences)[_class_pos]
boxes = boxes[_class_pos]
classes = classes[_class_pos]
return boxes, classes, scores
def nms_boxes(boxes, scores):
"""Suppress non-maximal boxes.
# Returns
keep: ndarray, index of effective boxes.
"""
x = boxes[:, 0]
y = boxes[:, 1]
w = boxes[:, 2] - boxes[:, 0]
h = boxes[:, 3] - boxes[:, 1]
areas = w * h
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x[i], x[order[1:]])
yy1 = np.maximum(y[i], y[order[1:]])
xx2 = np.minimum(x[i] + w[i], x[order[1:]] + w[order[1:]])
yy2 = np.minimum(y[i] + h[i], y[order[1:]] + h[order[1:]])
w1 = np.maximum(0.0, xx2 - xx1 + 0.00001)
h1 = np.maximum(0.0, yy2 - yy1 + 0.00001)
inter = w1 * h1
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= NMS_THRESH)[0]
order = order[inds + 1]
keep = np.array(keep)
return keep
def dfl(position):
# Distribution Focal Loss (DFL)
n,c,h,w = position.shape
p_num = 4
mc = c//p_num
y = position.reshape(n,p_num,mc,h,w)
# Vectorized softmax
e_y = np.exp(y - np.max(y, axis=2, keepdims=True)) # subtract max for numerical stability
y = e_y / np.sum(e_y, axis=2, keepdims=True)
acc_metrix = np.arange(mc).reshape(1,1,mc,1,1)
y = (y*acc_metrix).sum(2)
return y
def box_process(position):
grid_h, grid_w = position.shape[2:4]
col, row = np.meshgrid(np.arange(0, grid_w), np.arange(0, grid_h))
col = col.reshape(1, 1, grid_h, grid_w)
row = row.reshape(1, 1, grid_h, grid_w)
grid = np.concatenate((col, row), axis=1)
stride = np.array([IMG_SIZE//grid_h, IMG_SIZE//grid_w]).reshape(1,2,1,1)
position = dfl(position)
box_xy = grid +0.5 -position[:,0:2,:,:]
box_xy2 = grid +0.5 +position[:,2:4,:,:]
xyxy = np.concatenate((box_xy*stride, box_xy2*stride), axis=1)
return xyxy
def yolov8_post_process(input_data):
boxes, scores, classes_conf = [], [], []
# 修改为4个检测头
num_branches = 4
pair_per_branch = len(input_data) // num_branches
# 处理每个检测头的输出
for i in range(num_branches):
boxes.append(box_process(input_data[pair_per_branch*i]))
classes_conf.append(input_data[pair_per_branch*i+1])
scores.append(np.ones_like(input_data[pair_per_branch*i+1][:,:1,:,:], dtype=np.float32))
def sp_flatten(_in):
ch = _in.shape[1]
_in = _in.transpose(0,2,3,1)
return _in.reshape(-1, ch)
boxes = [sp_flatten(_v) for _v in boxes]
classes_conf = [sp_flatten(_v) for _v in classes_conf]
scores = [sp_flatten(_v) for _v in scores]
boxes = np.concatenate(boxes)
classes_conf = np.concatenate(classes_conf)
scores = np.concatenate(scores)
# filter according to threshold
boxes, classes, scores = filter_boxes(boxes, scores, classes_conf)
# nms
nboxes, nclasses, nscores = [], [], []
for c in set(classes):
inds = np.where(classes == c)
b = boxes[inds]
c = classes[inds]
s = scores[inds]
keep = nms_boxes(b, s)
if len(keep) != 0:
nboxes.append(b[keep])
nclasses.append(c[keep])
nscores.append(s[keep])
if not nclasses and not nscores:
return None, None, None
boxes = np.concatenate(nboxes)
classes = np.concatenate(nclasses)
scores = np.concatenate(nscores)
return boxes, classes, scores
def draw(image, boxes, scores, classes, ratio, padding):
for box, score, cl in zip(boxes, scores, classes):
top, left, right, bottom = box
top = (top - padding[0])/ratio[0]
left = (left - padding[1])/ratio[1]
right = (right - padding[0])/ratio[0]
bottom = (bottom - padding[1])/ratio[1]
top = int(top)
left = int(left)
cv2.rectangle(image, (top, left), (int(right), int(bottom)), (255, 0, 0), 2)
cv2.putText(image, '{0} {1:.2f}'.format(CLASS[cl], score),
(top, left - 6),
cv2.FONT_HERSHEY_SIMPLEX,
0.6, (0, 0, 255), 2)
def letterbox(im, new_shape=(640, 640), color=(0, 0, 0)):
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - \
new_unpad[1] # wh padding
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im, top, bottom, left, right,
cv2.BORDER_CONSTANT, value=color) # add border
return im, ratio, (left, top)
def myFunc(rknn_lite, IMG):
IMG2 = cv2.cvtColor(IMG, cv2.COLOR_BGR2RGB)
# 等比例缩放
IMG2, ratio, padding = letterbox(IMG2)
IMG2 = np.expand_dims(IMG2, 0)
outputs = rknn_lite.inference(inputs=[IMG2],data_format=['nhwc'])
boxes, classes, scores = yolov8_post_process(outputs)
if boxes is not None:
draw(IMG, boxes, scores, classes, ratio, padding)
return IMG
5.3运行main.py
就可以看到对应的输出结果了。
参考原文章【保姆级教程】从Yolov8训练模型到转化Onnx再转换为Rknn以及板端部署全记录_yolov8 rknn-CSDN博客

















 5100
5100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









