






前言
过去学习AI的路径通常是:数学基础 → 机器学习理论 → 框架使用 → 项目实战。但在大模型时代,这个路径面临三大挑战:
知识爆炸:Transformer、RLHF、MoE等新技术层出不穷
硬件门槛:动辄需要A100级别的算力才能实操
应用分化:不同场景(文本/多模态/Agent)需要差异化技能栈
本文提供一套经过验证的**"3阶9步"学习框架**,帮助开发者用最小成本掌握大模型核心技术。
编辑
第一阶段:认知构建
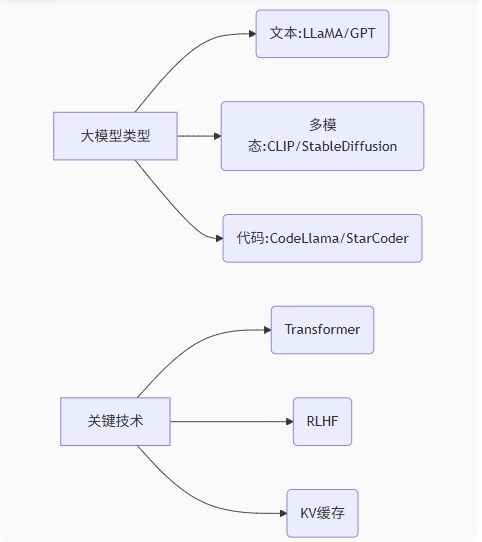
1. 建立技术坐标系
graph LR A[大模型类型] --> B(文本:LLaMA/GPT) A --> C(多模态:CLIP/StableDiffusion) A --> D(代码:CodeLlama/StarCoder) E[关键技术] --> F(Transformer) E --> G(RLHF) E --> H(KV缓存)
**
**
必读材料:
论文:《Attention Is All You Need》(精读架构图)
博客:Andrej Karpathy的《State of GPT》(理解训练流程)
2. 搭建实验沙盒
低成本方案:
Google Colab Pro(A100实例)
本地部署量化模型(用llama.cpp跑7B模型)
首个实验:
# 使用HuggingFace快速体验 from transformers import pipeline generator = pipeline('text-generation', model='gpt2') print(generator("AI大模型学习应该", max_length=50))
3. 掌握核心概念
关键术语表:
| 术语 | 通俗解释 | 类比理解 |
|---|---|---|
| Tokenization | 把文本变成数字密码 | 像汉语分词+编码 |
| LoRA | 模型微调的"补丁"技术 | 给模型打mod |
| RAG | 给模型接外部知识库 | 开卷考试 |
第二阶段:技术纵深
4. 逆向学习法
典型工作流拆解:
1. 数据准备 → 2. 预训练 → 3. SFT → 4. RLHF → 5. 部署
重点突破:
数据处理:学习使用datasets库清洗指令数据
微调实战:
bash
# 使用QLoRA微调 python -m bitsandbytes transformers finetune.py \ --model_name=meta-llama/Llama-2-7b \ --use_qlora=True
5. 工具链精通
现代MLOps工具栈:
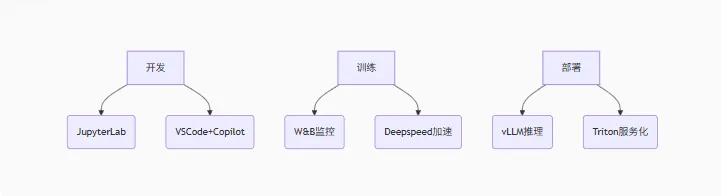
graph TB A[开发] --> B(JupyterLab) A --> C(VSCode+Copilot) D[训练] --> E(W&B监控) D --> F(Deepspeed加速) G[部署] --> H(vLLM推理) G --> I(Triton服务化)
效率技巧
用WandB监控训练过程
使用vLLM实现5倍推理加速
6. 领域专项突破
选择细分赛道:
| 领域 | 关键技术点 | 代表项目 |
|---|---|---|
| 对话系统 | 对话状态跟踪 | Microsoft DialoGPT |
| 代码生成 | 抽象语法树处理 | CodeT5 |
| 多模态 | 跨模态对齐 | LLaVA |
第三阶段:生产实践
7. 性能优化实战
工业级优化技巧:
FlashAttention优化
批处理(batching)技术
量化:GGUF格式8bit量化
python
from llama_cpp import Llama llm = Llama(model_path="llama-2-7b.Q8_0.gguf")
推理加速:
8. 架构设计能力
大模型系统设计模式:
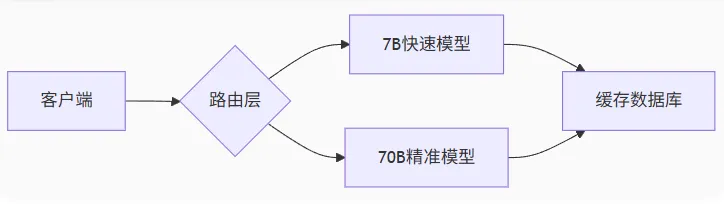
graph LR A[客户端] --> B{路由层} B --> C[7B快速模型] B --> D[70B精准模型] C --> E[缓存数据库] D --> E
设计原则:
-
- 小模型处理80%简单请求
- 动态负载均衡
9. 业务融合策略
-
落地方法论:
-
- 识别高价值场景(如客服、文档处理)
- 构建评估体系(准确率+成本+延迟)
- 渐进式替换原有流程
指南
-
不要过早陷入数学推导:先掌握工程实现,再补理论
-
警惕"玩具级"项目:尽早接触生产级代码(参考LangChain架构)
-
保持技术敏感度:

学习资源矩阵
| 类型 | 推荐内容 | 特点 |
|---|---|---|
| 视频 | CS324 @Stanford | 系统性强 |
| 代码 | llama-recipes | Meta官方实践 |
| 实验 | OpenLLM Leaderboard | 比较模型性能 |
| 社区 | HuggingFace Discord | 实时问题解答 |
结语:掌握"学-用-创"循环
高效学习大模型的关键在于:
学:用最小知识单元快速验证(如跑通一个微调demo)
用:在真实业务中测试技术边界(哪怕只是优化内部工具)
创:贡献社区或构建垂直领域解决方案
明日就能开始的行动:
- 在Colab上克隆LLaMA-2-7b模型
- 用Gradio构建一个本地聊天界面
- 尝试修改temperature参数观察生成效果
大模型时代不存在"学完"的概念,但持续3个月的刻意练习,就足以让你超越80%的观望者w
大模型目前在人工智能领域可以说正处于一种“炙手可热”的状态,吸引了很多人的关注和兴趣,也有很多新人小白想要学习入门大模型,那么,如何入门大模型呢?
下面给大家分享一份2025最新版的大模型学习路线,帮助新人小白更系统、更快速的学习大模型!
*有需要完整版学习路线*,可以微信扫描下方二维码,立即免费领取!

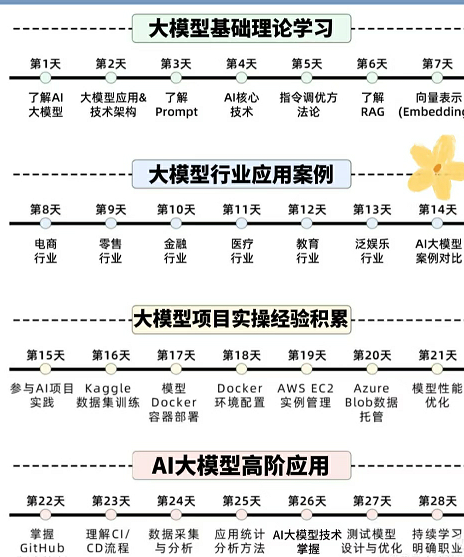
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

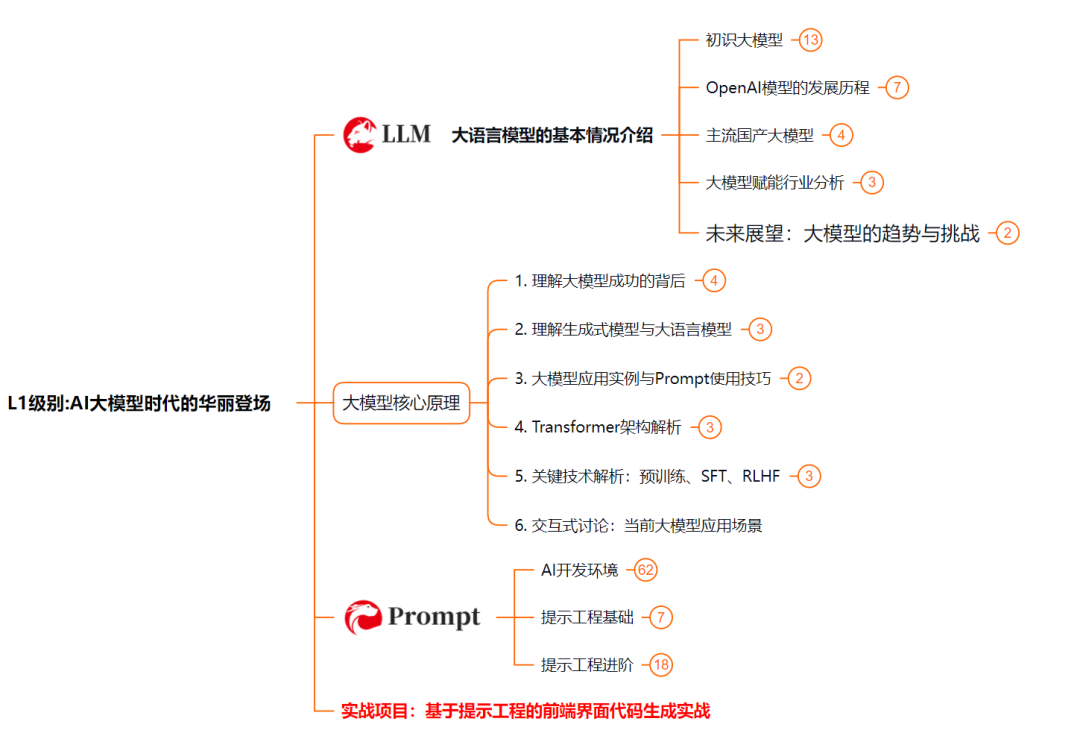
L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。
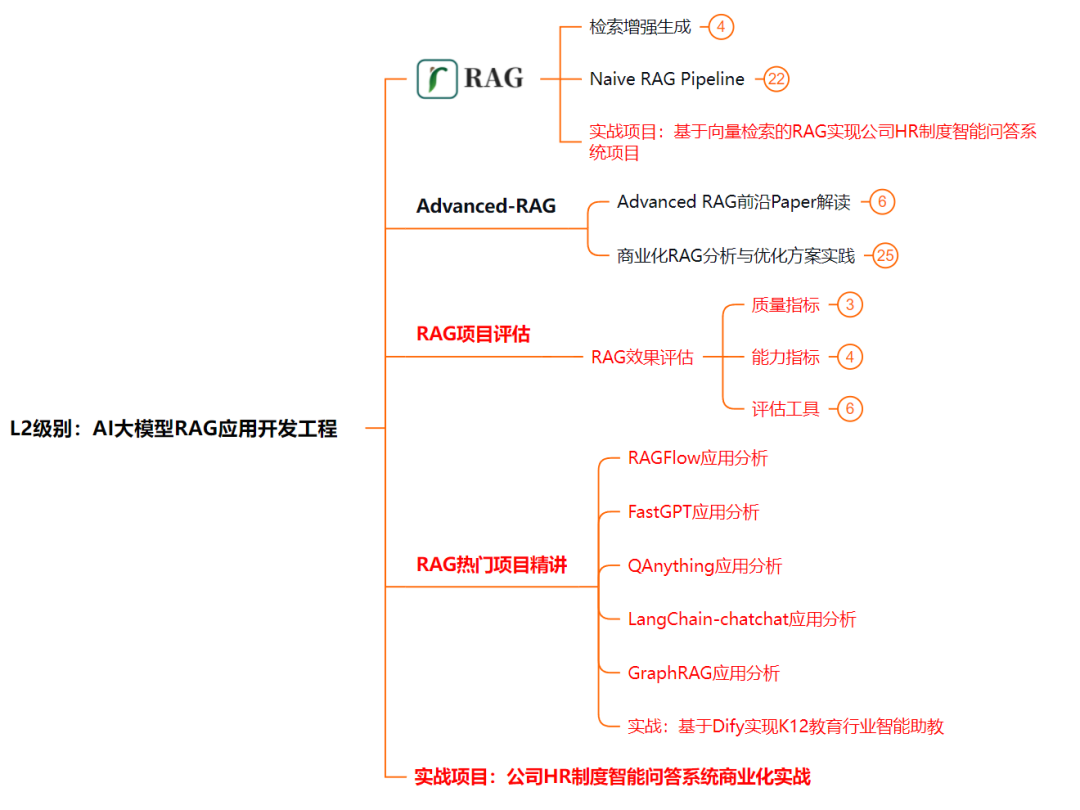
L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。
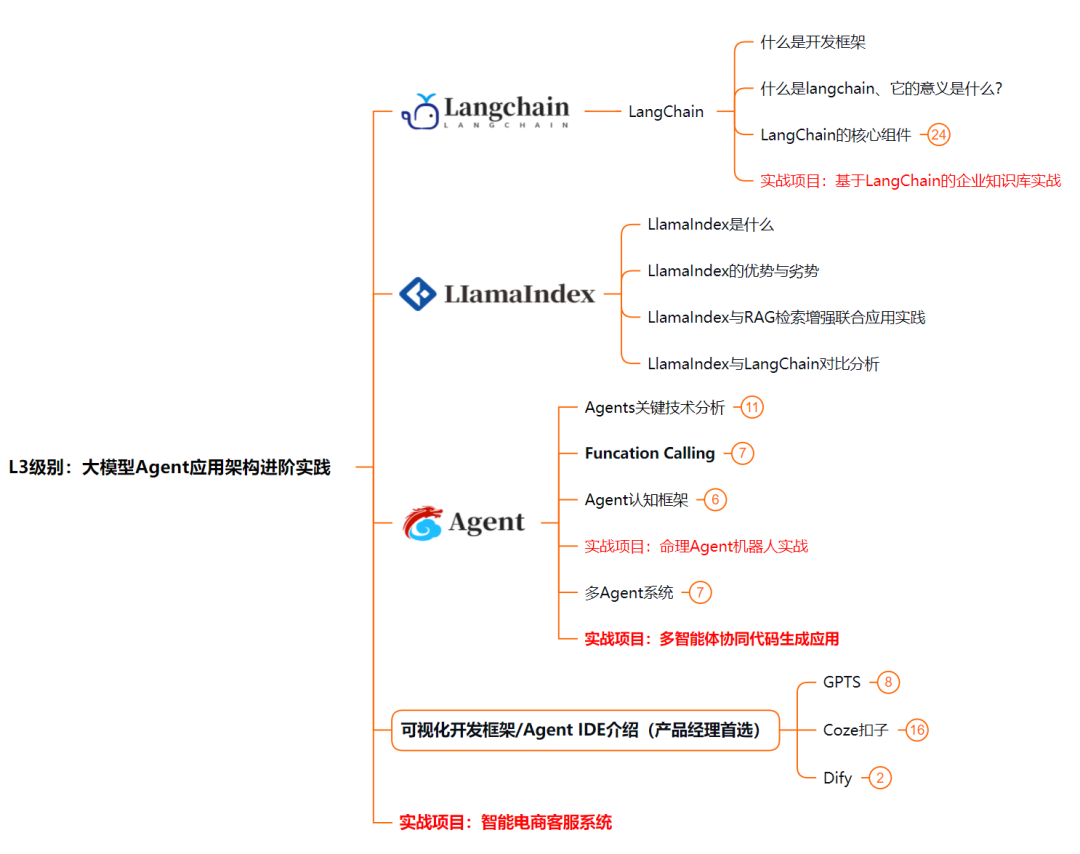
L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。
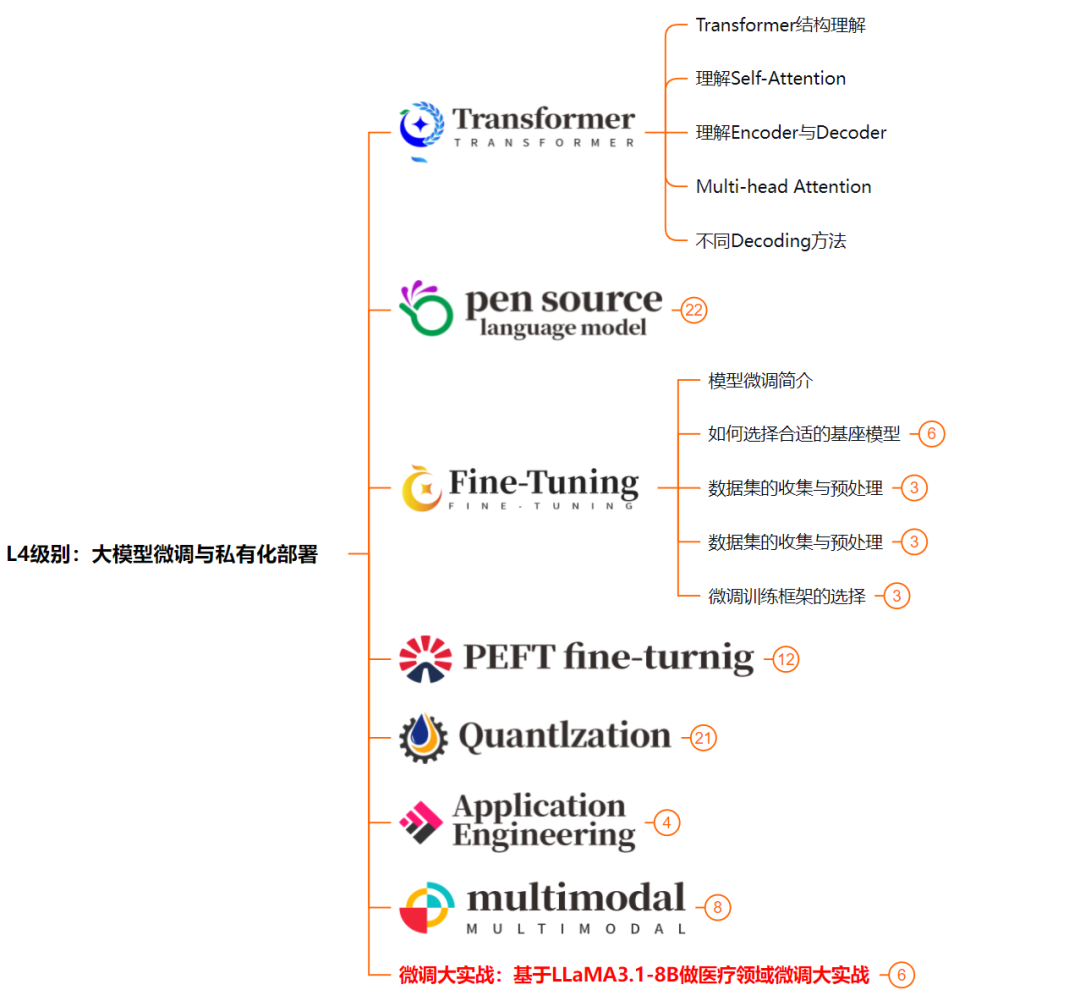
L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。
整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。
四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。
五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取
****如果这篇文章对你有所帮助,还请花费2秒的时间**点个赞+在看+分享,**让更多的人看到这篇文章,帮助他们走出误区。


















 916
916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









