









- 标准化
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。这样去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。其中最典型的就是0-1标准化和Z标准化
- 0-1标准化(0-1 normalization)
也叫离差标准化,是对原始数据的线性变换,使结果落到[0,1]区间,转换函数如下:
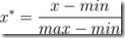
其中max为样本数据的最大值,min为样本数据的最小值。这种方法有一个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
- Z-score标准化(zero-mean normalization)
也叫标准差标准化,经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:
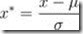
其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
- sklearn相关类
- 使用sklearn.preprocessing.scale()函数,可以直接将给定数据进行标准化(Z-score 标准化)
sklearn.preprocessing.scale(X, axis=0, with_mean=True, with_std=True, copy=True)
>>> fromsklearn import preprocessing
>>> importnumpy as np
>>> X =np.array([[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]])
>>>X_scaled = preprocessing.scale(X)
>>>X_scaled
array([[ 0. ..., -1.22..., 1.33...],
[ 1.22..., 0. ..., -0.26...],
[-1.22..., 1.22..., -1.06...]])
>>>#处理后数据的均值和方差
>>>X_scaled.mean(axis=0)
array([ 0., 0., 0.])
>>>X_scaled.std(axis=0)
array([ 1., 1., 1.])- 使用sklearn.preprocessing.StandardScaler类,使用该类的好处在于可以保存训练集中的参数(均值、方差)直接使用其对象转换测试集数据。
classsklearn.preprocessing.StandardScaler(copy=True,with_mean=True, with_std=True)
>>> scaler= preprocessing.StandardScaler().fit(X)
>>> scaler
StandardScaler(copy=True,with_mean=True, with_std=True)
>>>scaler.mean_
array([ 1. ..., 0. ..., 0.33...])
>>>scaler.std_
array([0.81..., 0.81..., 1.24...])
>>>scaler.transform(X)
array([[ 0. ..., -1.22..., 1.33...],
[ 1.22..., 0. ..., -0.26...],
[-1.22..., 1.22..., -1.06...]])
>>>#可以直接使用训练集对测试集数据进行转换
>>>scaler.transform([[-1., 1., 0.]])
array([[-2.44..., 1.22..., -0.26...]])- preprocessing.MinMaxScaler类将属性缩放到一个指定的最大和最小值(通常是1-0)之间
把特征的样本均值变成0,标准差变成1,这种标准化处理并不是唯一的方法。preprocessing还有MinMaxScaler类,将样本数据根据最大值和最小值调整到一个区间内;通过MinMaxScaler类可以很容易将默认的区间0到1修改为需要的区间。
使用这种方法的目的包括:
1、对于方差非常小的属性可以增强其稳定性。
2、维持稀疏矩阵中为0的条目。
classsklearn.preprocessing.MinMaxScaler(feature_range=(0,1), copy=True)
,在构造类对象的时候也可以直接指定最大最小值的范围:feature_range=(min, max),此时应用的公式变为:
X_std=(X-X.min(axis=0))/(X.max(axis=0)-X.min(axis=0))
X_scaled=X_std/(max-min)+min
>>> X_train= np.array([[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]])
...
>>>min_max_scaler = preprocessing.MinMaxScaler()
>>>X_train_minmax = min_max_scaler.fit_transform(X_train)
>>>X_train_minmax
array([[ 0.5 , 0. , 1. ],
[ 1. , 0.5 , 0.33333333],
[ 0. , 1. , 0. ]])
>>>#将相同的缩放应用到测试集数据中
>>> X_test= np.array([[ -3., -1., 4.]])
>>>X_test_minmax = min_max_scaler.transform(X_test)
>>>X_test_minmax
array([[-1.5 , 0. , 1.66666667]])
>>>#缩放因子等属性
>>>min_max_scaler.scale_
array([ 0.5 , 0.5 , 0.33...])
>>>min_max_scaler.min_
array([ 0. , 0.5 , 0.33...])















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









