在机器学习开发中由于某些特征值不稳定,波动较大,会对我们求参时产生不利影响,所以常常需要进行数据标准化,在此专门记录一下数据标准化的方法
1. 首先导入模块
from sklearn.preprocessing import StandardScaler
import numpy as np
2. 接着实例化一个标准化对象
std = StandardScaler()
3. 准备好待标准化的数据
这里必须数据必须是二维,即n行一列(None, 1) ,形如[[1],[2],[3],[4],[5],[6]],这里用numpy生成一个包含12个元素的数组再将reshape为(12,1),
a = np.arange(12).reshape(-1,1)
4. 直接调用fit_transform()传入待处理数据进行标准化,返回标准化后的数据,打印查看
b = std.fit_transform(a)
print(b)
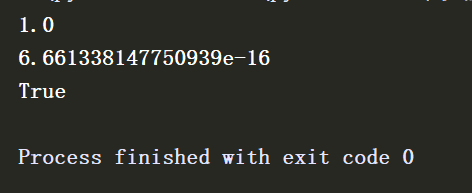
5. 验证是否为标准化序列数据,若返回标准化数据,则其均值为0,标准差为1,在此计算其和以及其标准差
sd = 0
for i in b.flat:
sd = sd + i * i
sd = np.sqrt((sd / 12))
print(sd)
print(b.sum())
print(0.000000001>b.sum())
b.flat返回numpy数组迭代器,我们遍历其求标准差,打印查看
b.sum()返回标准化数据的和 打印查看发现不为0,这是由于计算机对浮点数无法精确计算,打印0.000000001>b.sum() 为True 说明均值非常接近0,正确


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









