







文章目录
pandas初步了解
①Series 一维,带标签数组
②DataFrame 二维,Series容器
Series(一维)
Series创建
①使用pd.Series()创建,以list为参数,index为可选参数
import pandas as pd
t1 = pd.Series([1,2,31,12,3,4])
print(t1)
print(type(t1))
结果为:

t2 = pd.Series([1,23,2,2,1],index = list("abcde"))
print(t2)
结果为:
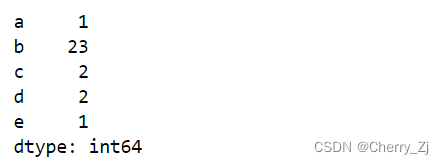
②使用pd.Series()创建,以字典为参数

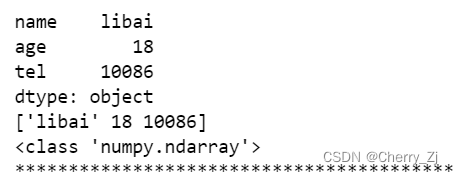
temp_dict = {"name":"libai","age":18,"tel":10086}
t3 = pd.Series(temp_dict)
print(t3)
结果为:
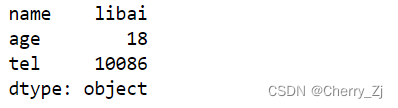
改变数据类型
print(t2)
print("*"*100)
print(t2.astype(float))

切片和索引

示例:
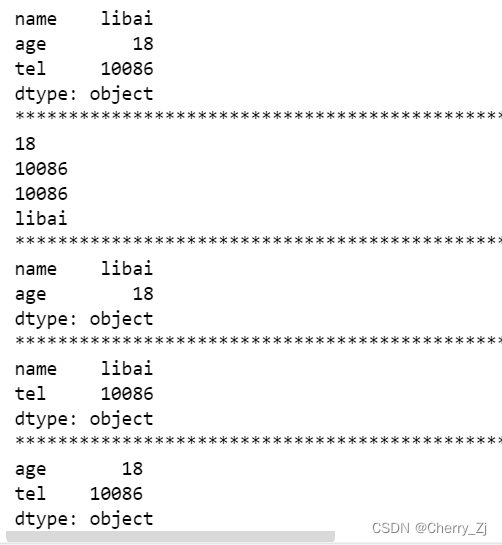
print(t3)
print("*"*100)
print(t3["age"])
print(t3["tel"])
print(t3[2])
print(t3[0])
print("*"*100)
#取连续的前两行
print(t3[:2])
print("*"*100)
#取不连续的两行
print(t3[[0,2]])
print("*"*100)
print(t3[["age","tel"]])
Series的index和value

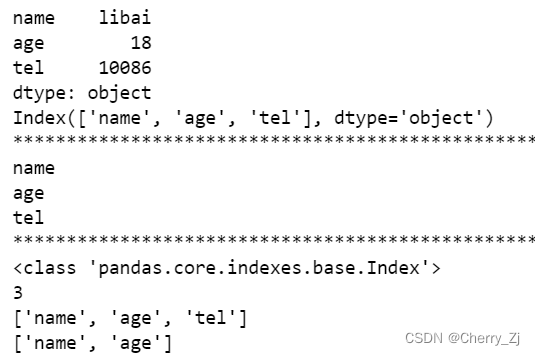
print(t3)
print(t3.index)
print("*"*100)
#可迭代,可遍历
for i in t3.index:
print(i)
print("*"*100)
print(type(t3.index))
print(len(t3.index))
print((list(t3.index)))
print(list(t3.index)[:2])
print(t3)
print(t3.values)
print(type(t3.values))
print("*"*100)
pandas读取csv中的文件
df = pd.read_csv("./dataCSV/data.csv")
DataFrame (二维)

DataFrame 创建
①pd.DataFrame()创建,list为参数,index为可选参数
t4= pd.DataFrame(np.arange(12).reshape(3,4))
print(t4)
结果为:

t5= pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list("wxyz"))
print(t5)
结果为:
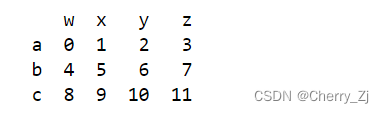
②pd.DataFrame()创建,字典为参数
d1 = {"name":["xiaohong","xiaoming"],"age":[20,23],"tel":[10086,11010]}
t6 = pd.DataFrame(d1)
print(t6)
print("*"*100)
print(type(t6))
结果为:

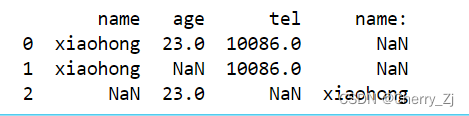
d2 = [{"name":"xiaohong","age":23,"tel":10086},{"name":"xiaohong","tel":10086},{"name:":"xiaohong","age":23}]
t7 = pd.DataFrame(d2)
print(t7)
结果为:
DataFrame的基本方法

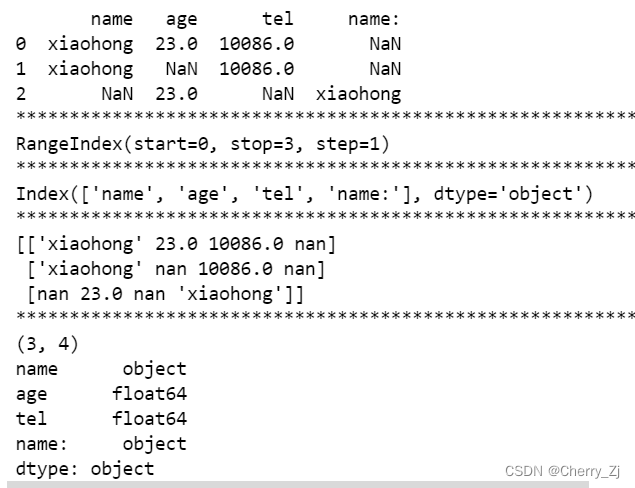
示例:
print(t7)
print("*"*100)
print(t7.index)
print("*"*100)
print(t7.columns)
print("*"*100)
print(t7.values)
print("*"*100)
print(t7.shape)
print(t7.dtypes)
选择获取的数据

pandas之loc

示例:
t8 = pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list("wxyz"))
print(t8)
print(t8.loc["a","z"])
print(type(t8.loc["a","z"]))
#只取行
print(t8.loc["a"])
print("*"*100)
print(t8.loc["a",:])
print("*"*100)
#只取列
print(t8.loc[:,"y"])
print("*"*100)
#取多行
print(t8.loc[["a","c"]])
print(("*"*100))
print(t8.loc[["a","c"],:])
print(("*"*100))
#取多列
print(t8.loc[:,["w","z"]])
#取多行多列
print(t8.loc[["a","b"],["w","z"]])
结果为:

pandas之iloc
iloc通过位置获取行数据

示例:
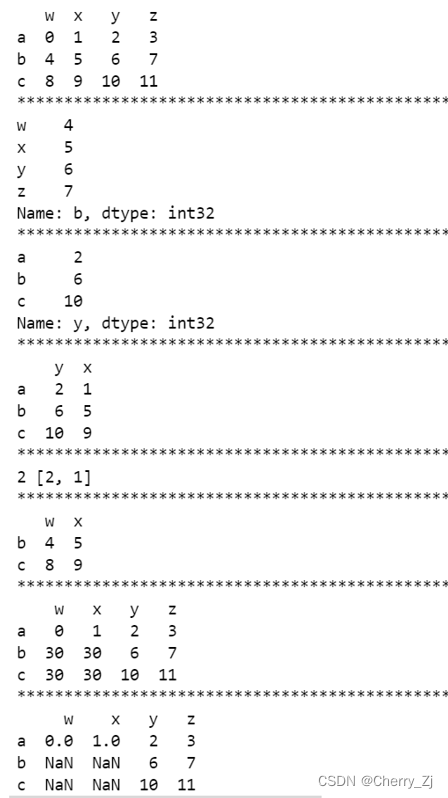
print(t8)
print(("*"*100))
print(t8.iloc[1,:])
print(("*"*100))
print(t8.iloc[:,2])
print(("*"*100))
print(t8.iloc[:,[2,1]])
print(("*"*100))
print(t8.iloc[0,2],[2,1])
print(("*"*100))
print(t8.iloc[1:,:2])
print(("*"*100))
t8.iloc[1:,:2] = 30
print(t8)
print(("*"*100))
t8.iloc[1:,:2] = np.nan
print(t8)
结果为:
布尔索引

pandas之字符串的方法

缺失数据的处理

①处理方式一:
#处理缺失数据
#法一
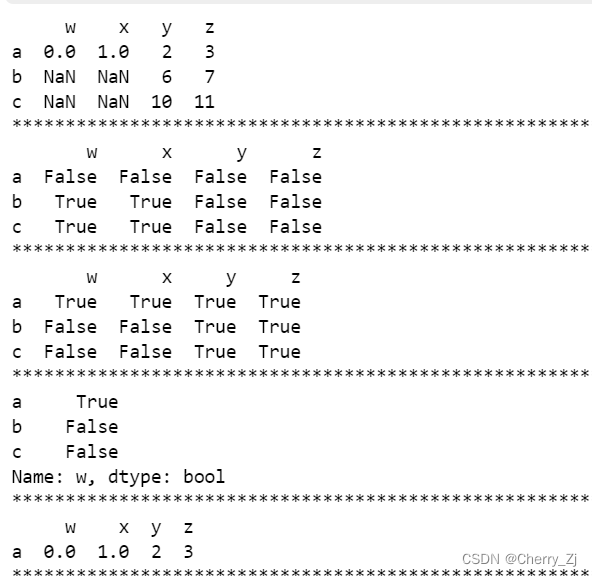
print(t8)
print("*"*100)
print(pd.isnull(t8))
print("*"*100)
print(pd.notnull(t8))
print("*"*100)
print(pd.notnull(t8["w"]))
print("*"*100)
print(t8[pd.notnull(t8["w"])])
print("*"*100)
print(t8.dropna(axis=0))
print("*"*100)
print(t8.dropna(axis=0,how="all"))
print("*"*100)
print(t8.dropna(axis=0,how="any"))
print("*"*100)
print(t8.dropna(axis=0,how="any",inplace=True))
print("*"*100)
print(t8)
②处理方式二:
#法二
print(t7)
print("*"*100)
print(t7.fillna(0))
print("*"*100)
print(t7.fillna(100))
print("*"*100)
print(t7.fillna(t2.mean()))
print("*"*100)
print(t7["age"].fillna(t7["age"].mean()))
print("*"*100)
t7["age"] = t7["age"].fillna(t7["age"].mean())
print(t7)















 4669
4669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









