







- 特征工程
特征工程是将原始数据转换为更好地代表预测模型
的潜在问题的特征的过程,从而提高了对未知数据
的预测准确性。 - 特征工程的意义
直接影响预测结果。
sklearn特征抽取API
特征抽取对文本等数据进行特征值化。
sklearn特征抽取API:sklearn.feature_ extraction
字典特征抽取
作用:对字典数据进行特征值化
类: sklearn.feature_ extraction.DictVectorizer
DictVectorizer语法:
DictVectorizer(sparse=True...)DictVectorizer.fit_ _transform(X)
①X:字典或者包含字典的迭代器
②返回值:返回sparse矩阵DictVectorizer.inverse_ _transform(X)
①X:array数组或者sparse矩阵
②返回值:转换之前数据格式DictVectorizer.get_ feature_ names()
返回类别名称DictVectorizer.transform(X)
按照原先的标准转换
示例:
from sklearn.feature_extraction import DictVectorizer
def dictvec():
"""
字典数据抽取
:return: None
"""
# 实例化
dict = DictVectorizer()
# 调用fit_transform
data = dict.fit_transform([{'city':'北京','temperature':100},{'city':'上海','temperature':60},{'city':'深圳','temperature':30}])
print(dict.get_feature_names())
print(data)
return None
if __name__ == "__main__":
dictvec()
结果为:

DictVectorizer中默认sparse=True,若sparse=False,则:
from sklearn.feature_extraction import DictVectorizer
def dictvec():
"""
字典数据抽取
:return: None
"""
# 实例化
dict = DictVectorizer(sparse=False)
# 调用fit_transform
data = dict.fit_transform([{'city':'北京','temperature':100},{'city':'上海','temperature':60},{'city':'深圳','temperature':30}])
print(dict.get_feature_names())
print(data)
return None
if __name__ == "__main__":
dictvec()
效果为:

注意:
①字典数据抽取:把字典中一些类别数据,分别进行转换成特征值
②数组形式,有类别的这些特征先要转换字典数据
文本特征抽取
作用:对文本数据进行特征值化
类:sklearn.feature extraction.text.CountVectorizer
CountVectorizer语法:
CountVectorizer()
返回词频矩阵CountVectorier.fit_ _transform(X)
①X:文本或者包含文本字符串的可迭代对象
②返回值:返回sparse矩阵CountVectorizer.inverse_ transform(X)
①X:array数组或者sparse矩阵
②返回值:转换之前数据格式CountVectorizer.get feature_ names()
返回值:单词列表
示例:
from sklearn.feature_extraction.text import CountVectorizer
def countvec():
"""
对文本进行特征值化
:return: None
"""
cv = CountVectorizer()
# 1. 统计所有文章当中所有的词,重复的只看作一次(词的列表)cv.get_feature_names()
# 2. 对每篇文章,在词的列表里面进行统计每个词出现的次数
# 3. 单个字母不统计
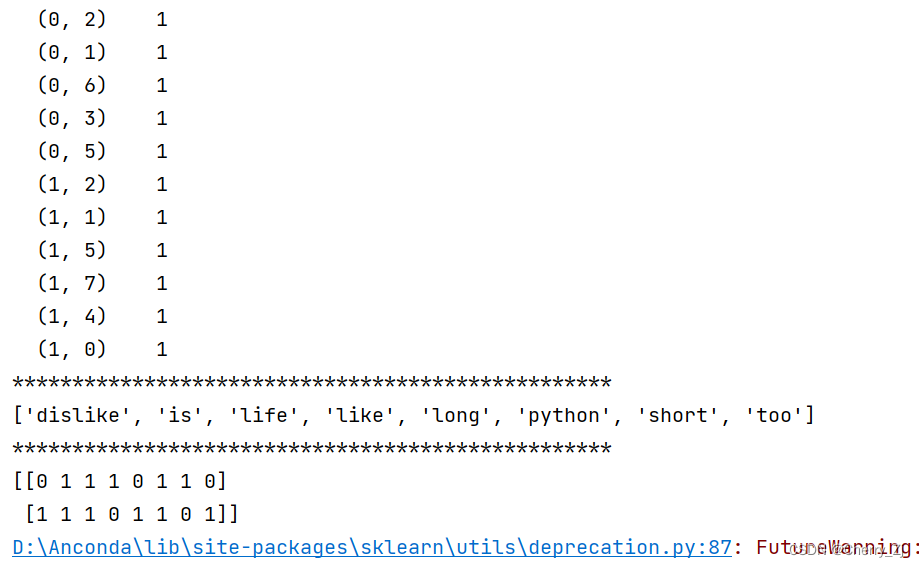
data = cv.fit_transform(["life is short,i like python","life is too long,i dislike python"])
print(data)
print("*" * 50)
print(cv.get_feature_names())
print("*"*50)
print(data.toarray())
return None
if __name__ == "__main__":
countvec()
结果为:
但注意:
这种方法不支持单个中文字,需要对中文进行分词才能详细的进行特征值化。
示例:
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def cutword():
con1 = jieba.cut("我与父亲不相见已有二年余了,我最不能忘记的是他的背影。")
con2 = jieba.cut("那年冬天,祖母死了,父亲的差使也交卸了,正是祸不单行的日子,我从北京到徐州,打算跟着父亲奔丧回家。")
con3 = jieba.cut("这些日子,家中光景很是惨淡,一半为了丧事,一半为了父亲赋闲。")
# 转换成列表
content1 = list(con1)
content2 = list(con2)
content3 = list(con2)
# 把列表转换成字符串
c1 = ' '.join(content1)
c2 = ' '.join(content2)
c3 = ' '.join(content3)
return c1,c2,c3
def hanzivec():
"""
对文本进行特征值化
:return: None
"""
c1,c2,c3 = cutword()
print(c1,c2,c3)
cv = CountVectorizer()
data = cv.fit_transform([c1,c2,c3])
print(data)
print("*" * 50)
print(cv.get_feature_names())
print("*"*50)
print(data.toarray())
return None
if __name__ == "__main__":
hanzivec()
结果为:

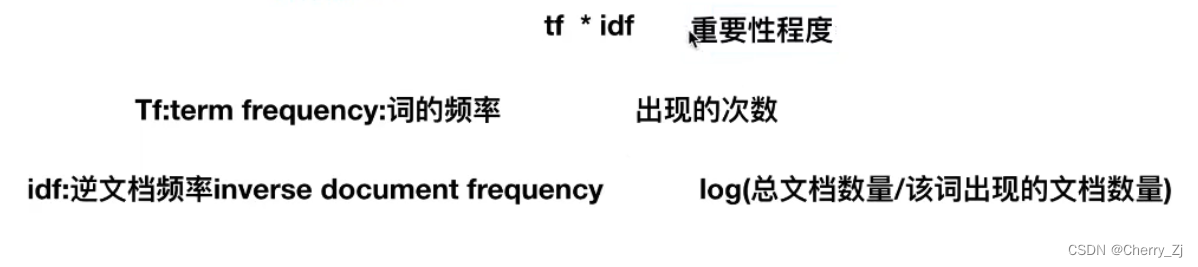
TF-IDF
- TF-IDF的主要思想是:如果某个词或短语在一篇文 章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
- TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
- 类:
sklearn.feature_ extractionJtext.TfidfVectorizer
5. TfidfVectorizer语法:
① TfidfVectorizer(stop_ _words=None...)
返回词的权重矩阵
②TfidfVectorizer.fit_ _transform(X)
X:文本或者包含文本字符串的可迭代对象
返回值:返回sparse矩阵
③TfidfVectorizer.inverse_ _transform(X)
●X:array数组或者sparse矩阵
返回值:转换之前数据格式
④TfidfVectorizer.get_ _feature_ names()
返回值:单词列表
- 为什么需要TfidfVectorizer?
它是分类机器学习算法的的重要依据。
示例:
from sklearn.feature_extraction.text import TfidfVectorizer
import jieba
def cutword():
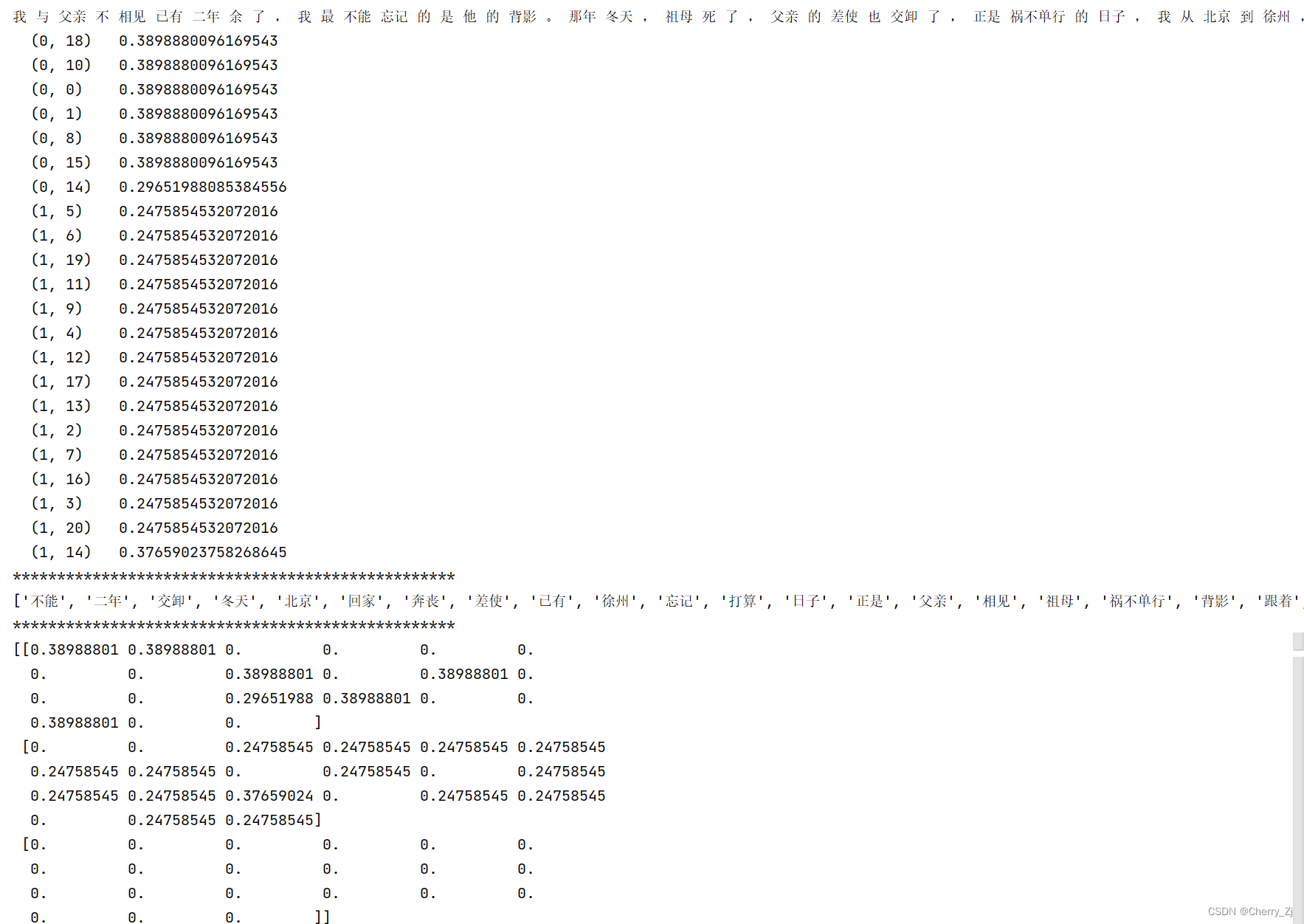
con1 = jieba.cut("我与父亲不相见已有二年余了,我最不能忘记的是他的背影。")
con2 = jieba.cut("那年冬天,祖母死了,父亲的差使也交卸了,正是祸不单行的日子,我从北京到徐州,打算跟着父亲奔丧回家。")
con3 = jieba.cut("这些日子,家中光景很是惨淡,一半为了丧事,一半为了父亲赋闲。")
# 转换成列表
content1 = list(con1)
content2 = list(con2)
content3 = list(con2)
# 把列表转换成字符串
c1 = ' '.join(content1)
c2 = ' '.join(content2)
c3 = ' '.join(content3)
return c1,c2,c3
def tfidfvec():
"""
对文本进行特征值化
:return: None
"""
c1,c2,c3 = cutword()
print(c1,c2,c3)
tf = TfidfVectorizer()
data = tf.fit_transform([c1,c2,c3])
print(data)
print("*" * 50)
print(tf.get_feature_names())
print("*"*50)
print(data.toarray())
return None
if __name__ == "__main__":
tfidfvec()
结果为:
归一化

sklearn归一化API: sklearn.preprocessing.MinMaxScaler
作用:使某一 个特征对最终结果不会造成更大影响。
MinMaxScaler语法:
MinMaxScalar(feature_ range=(0,1)..)
每个特征缩放到给定范围(默认[0,1])MinMaxScalar.fit_ _transform(X)
①X:numpy array格式的数据[n_ samples,n_ features]
②返回值:转换后的形状相同的array
示例:
from sklearn.preprocessing import MinMaxScaler
def mm():
"""
归一化处理
:return:None
"""
mm = MinMaxScaler(feature_range=(2,3))
data = mm.fit_transform([[90,2,10,40],[60,4,15,45],[75,3,13,46]])
print(data)
if __name__ == "__main__":
mm()
结果为:
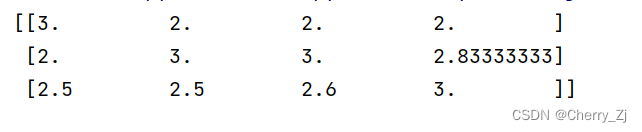
归一化总结

标准化

-
sklearn特征化API:
scikit-learn.preprocessing.StandardScaler -
StandardScaler语法:
①StandardScaler(..)
处理之后每列来说所有数据都聚集在均值0附近标准差差②
StandardScaler.fit_ _transform(X)
X:numpy array格式的数据[n_ _samples,n_ features]
返回值:转换后的形状相同的array③
StandardScaler.mean_
原始数据中每 列特征的平均值④
StandardScaler.std_
原始数据每列特征的方差
示例;
from sklearn.preprocessing import StandardScaler
def stand():
"""
标准化缩放
:return:None
"""
std = StandardScaler()
data = std.fit_transform([[1.,-1.,3.],[2.,4.,2.],[4.,6.,-1.]])
print(data)
if __name__ == "__main__":
stand()
结果为:

标准化总结:
在已有样本足够多的情况下比较稳定,适合
现代嘈杂大数据场景。
总结:

缺失值处理方法
- 有删除和插补两种方法:

2.插补需使用from sklearn.impute import SimpleImputer















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









