






2021SC@SDUSC
TextRank是一种用以关键词提取的算法,因为是基于PageRank的,所以先介绍PageRank。
PageRank通过互联网中的超链接关系确定一个网页的排名,其公式是通过一种投票的思想来设计的:如果我们计算网页A的PageRank值,那么我们需要知道哪些网页链接到A,即首先得到A的入链,然后通过入链给网页A进行投票来计算A的PR值。这样设计可以保证达到这样一个效果:当某些高质量的网页指向网页A的时候,那么网页A的PR值会因为这些高质量的投票而变大,而网页A被较少网页指向或被一些PR值较低的网页指向的时候,A的PR值也不会很大,这样可以合理地反映一个网页的质量水平。
TextRank是由PageRank改进而来,其公式有颇多相似之处,这里给出TextRank的公式:
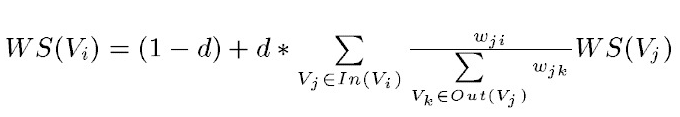
可以看出,该公式仅仅比PageRank多了一个权重项Wji,用来表示两个节点之间的边连接有不同的重要程度。TextRank用于关键词提取的算法如下:
1)把给定的文本T按照完整句子进行分割
2)对于每个句子,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,即,其中 ti,j 是保留后的候选关键词。
3)构建候选关键词图G = (V,E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口大小,即最多共现K个单词。
4)根据上面公式,迭代传播各节点的权重,直至收敛。
5)对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词。
6)由5得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。
2.2 TextRank算法提取关键词短语
提取关键词短语的方法基于关键词提取,可以简单认为:如果提取出的若干关键词在文本中相邻,那么构成一个被提取的关键短语。
2.3TextRank生成摘要
将文本中的每个句子分别看做一个节点,如果两个句子有相似性,那么认为这两个句子对应的节点之间存在一条无向有权边。
class TextRank(KeywordExtractor):
def __init__(self):
self.tokenizer = self.postokenizer = jieba.posseg.dt
self.stop_words = self.STOP_WORDS.copy()
self.pos_filt = frozenset(('ns', 'n', 'vn', 'v'))
self.span = 5
def pairfilter(self, wp):
return (wp.flag in self.pos_filt and len(wp.word.strip()) >= 2
and wp.word.lower() not in self.stop_words)
def textrank(self, sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'), withFlag=False):
"""
Extract keywords from sentence using TextRank algorithm.
Parameter:
- topK: return how many top keywords. `None` for all possible words.
- withWeight: if True, return a list of (word, weight);
if False, return a list of words.
- allowPOS: the allowed POS list eg. ['ns', 'n', 'vn', 'v'].
if the POS of w is not in this list, it will be filtered.
- withFlag: if True, return a list of pair(word, weight) like posseg.cut
if False, return a list of words
"""
self.pos_filt = frozenset(allowPOS)
g = UndirectWeightedGraph()
cm = defaultdict(int)
words = tuple(self.tokenizer.cut(sentence))
for i, wp in enumerate(words):
if self.pairfilter(wp):
for j in xrange(i + 1, i + self.span):
if j >= len(words):
break
if not self.pairfilter(words[j]):
continue
if allowPOS and withFlag:
cm[(wp, words[j])] += 1
else:
cm[(wp.word, words[j].word)] += 1
for terms, w in cm.items():
g.addEdge(terms[0], terms[1], w)
nodes_rank = g.rank()
if withWeight:
tags = sorted(nodes_rank.items(), key=itemgetter(1), reverse=True)
else:
tags = sorted(nodes_rank, key=nodes_rank.__getitem__, reverse=True)
if topK:
return tags[:topK]
else:
return tags
extract_tags = textrank















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









