







NLP Tool 专栏:NLP Tool_北村南的博客-CSDN博客
目录
JieBa
介绍
Jieba工具主要应用于Python文本分析,其最强大的功能在于分词
在关键字提取方面,Jieba库提供了两个封装算法Tf-Idf和Text-Rank
安装
pip install jiebaTF-IDF
算法思想
如果一个候选词在本文段中出现多次,而在其他文段中出现的次数较少,则可认为其对于本文段较为重要,即关键词。



实现步骤
1 将待提取关键词的文本进行分词
2 载入自定义词典(可省略),虽然jieba有识别新词的能力,但是使用自定义词典可以提高分词准确率,如下
jieba.load_userdict('cidian.txt')
jieba中的词性分类标签如下

3 自定义逆向文件频率(IDF)文本语料库,从而实现动态更新自己的语料库
4 自定义停用词
5 对分词进行词性标注处理,过滤提用词,保留候选关键词
6 计算各个分词的tf*idf值,并进行倒序排序,得到最重要的N个词,即为关键词
代码实现
# -*- coding: utf-8 -*-
import jieba
import jieba.analyse
jieba.load_userdict('cidian.txt')
text=''
with open ('demo.txt', 'r', encoding='utf-8') as file:
for line in file:
line=line.strip()
text+=line#将需要的文本读取到text中
print(jieba.analyse.extract_tags(text,topK=5,
withWeight=False, allowPOS=('ns', 'n', 'vn', 'v','nt','nw',
'nz','v','vd','vn','a','an','LOC')))实现效果

TextRank
算法思想
将整篇文章看做一个超平面,每个词看做一个点,一个点周围有越多的点靠近它,那么这个点就是处于核心位置,也就是关键词。
实现步骤
1 将待提取关键词的文本进行分词
2 对分词进行词性标注处理,过滤提用词,保留候选关键词
3 使用滑窗实现词之间的共现关系,构建图,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现
4 根据上述公式,迭代传播各节点的权重,直至收敛
5 对节点权重进行倒序排序,得到最重要的N个词,即为关键词
代码实现
# -*- coding: utf-8 -*-
import jieba
import jieba.analyse
#分词和分字,并输出到文件中
vocab={}
cs={}
text=''
with open ('demo.txt', 'r', encoding='utf-8') as file:
for line in file:
line=line.strip()
text+=line#将需要的文本读取到text中
#分字
for c in line:
cs[c]=0
#分词
for word in jieba.cut(line):
vocab[word]=0
#将分词和分字的结果保留到文本文件中
with open ('cs.txt', 'w', encoding='utf-8') as csf:
for c in cs.keys():
csf.write(c+'\n')
with open ('vocab.txt', 'w', encoding='utf-8') as vf:
for w in vocab.keys():
vf.write(w+'\n')
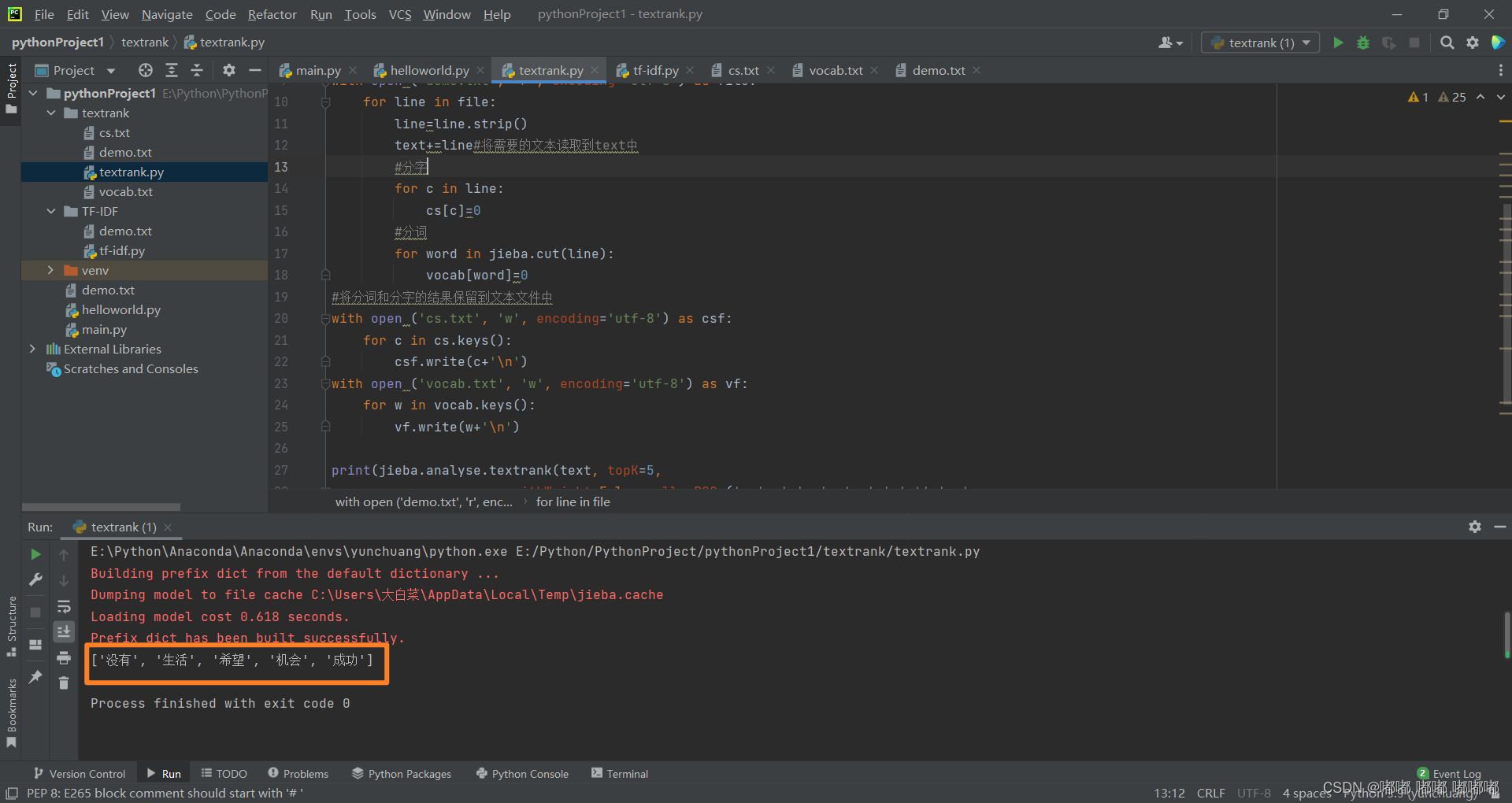
print(jieba.analyse.textrank(text, topK=5,
withWeight=False, allowPOS=('ns', 'n', 'vn', 'v','nt','nw',
'nz','v','vd','vn','a','an','LOC')))
实现效果
参考资料
Textrank原始论文:mihalcea.emnlp04.pdf (umich.edu)
TF-IDF官方代码:GitHub - fxsjy/jieba: 结巴中文分词
















 1712
1712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











