







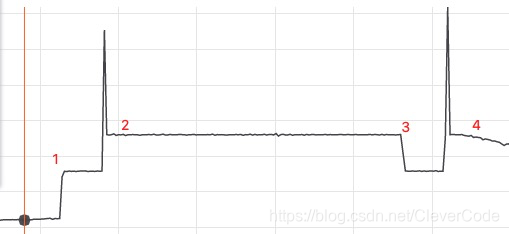
1 ,20:35 收到报警,流出带宽使用率95%。如图中的1标识。
2, 20:35 这个时候收到429限流报警。
3,20:35 开始排查,同时发现流入带宽没有发送明显波动。这时候给流出带宽立马增加了200M(先用钱解决问题)。如标识2,发现又被打满了。流入带宽没有发现变化。增长200M之后,限流问题得到缓解。
4,20:40 开始分析nginx日志,排查20:35左右,流量是不是有突增。根据请求分析,找到app_A,app_B两个服务的请求量比较大。但是做了app_A,app_B在20:35对比昨天的流量分析,发现并没有明显突增。
5,22:35,又报限流429。原来是上图中标识3,花钱流出带宽只,扩了2个小时。原本以为2个小时能够搞定。
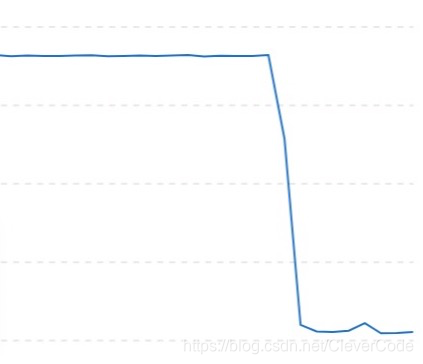
6,23:00,再次扩容200M。标识4。这次扩容之后,流出带宽开始缓慢下降。这个时候网站整体流量也缓慢下来了。因为是半夜了。
7,23:30开发排查机器流量,发现40台机器的worker节点的网卡流出流量很高。但不能说明就是走了外网。
8,23:40 通过iftop命令,分析网卡流量。没有发现明显特征。
# iftop -i eth0 -n -P
=> 出网
<= 入网
9,23:50 。总结分析。流入带宽没有发生变化,但是流出带宽突然陡增。但是http请求的流量没有突然陡增。说明并不是因为http请求引起的流量变化。那么剩下一种可能就是有内部的软件,在大量的向外网进行上报数据(像不像tuo ku,或者上报日志之类的)。想想很可怕,但是又找不到什么进程在大量的向外网发送数据。
10,00:00。排出了http请求的可能行。这个时候结合promethus监控。发现有一个pod的中process A,process B,process C的网卡流量特别高。但是从经验来看这3个都是日志收集,或者流量统计分析的进程,应该不会像外网发送数据。
11,00:30 在一个workder节点上,外网发送数据比较多的机器上进行抓包
# tcpdump -i eth0 -w dump.pcap -v -c 100000
-i etho :抓包etho网卡.
-w dump.pcap:抓包数据存储文件。
-c 100000:抓指定要监听到的数据包数量
-v 当分析和打印的时候, 产生详细的输出. 比如, 包的生存时间, 标识, 总长度以及IP包的一些选项. 这也会打开一些附加的包完整性检测, 比如对IP或ICMP包头部的校验和.
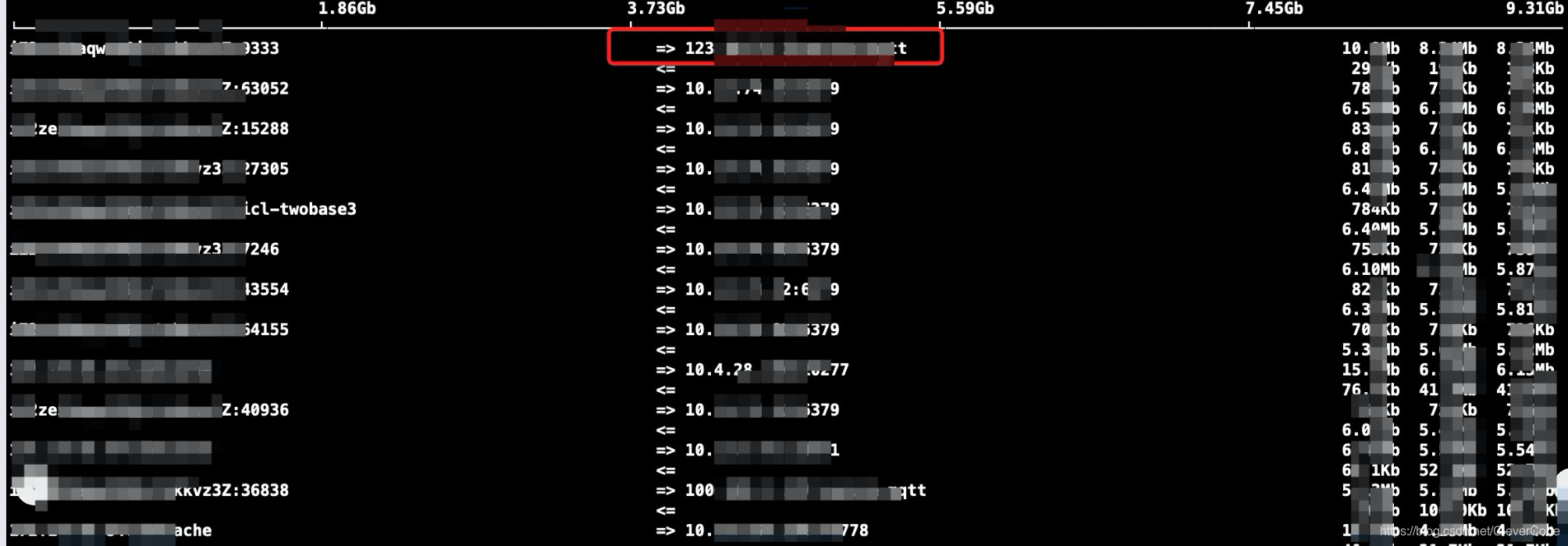
12,00:40 分析数据包,打开wireshark 。file => open => dump.pcap。分析数据包。wireshark 里面统计目标ip和端口。可以看到目标ip中,有一个外网ip:123.x.x.3。给这个外网的8xx3端口发送99.10%的数据。其它的172.x.x.x 和10.x.x.x都是内网ip。查阅配置 8xx3的进程是process B。
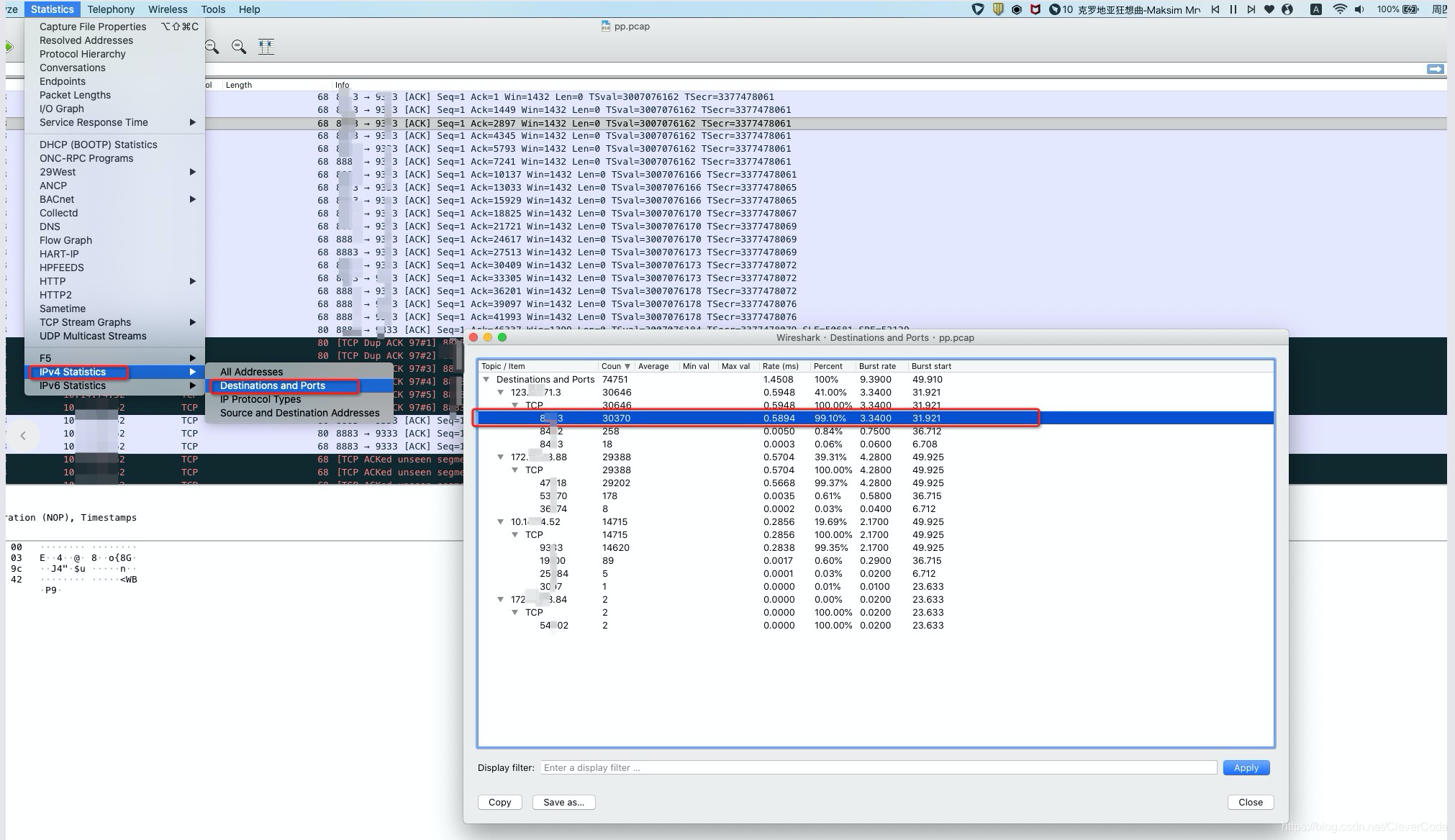
对话分析。地址A到地址B。中排序。发现打到了31M。即到123.x.x.3。
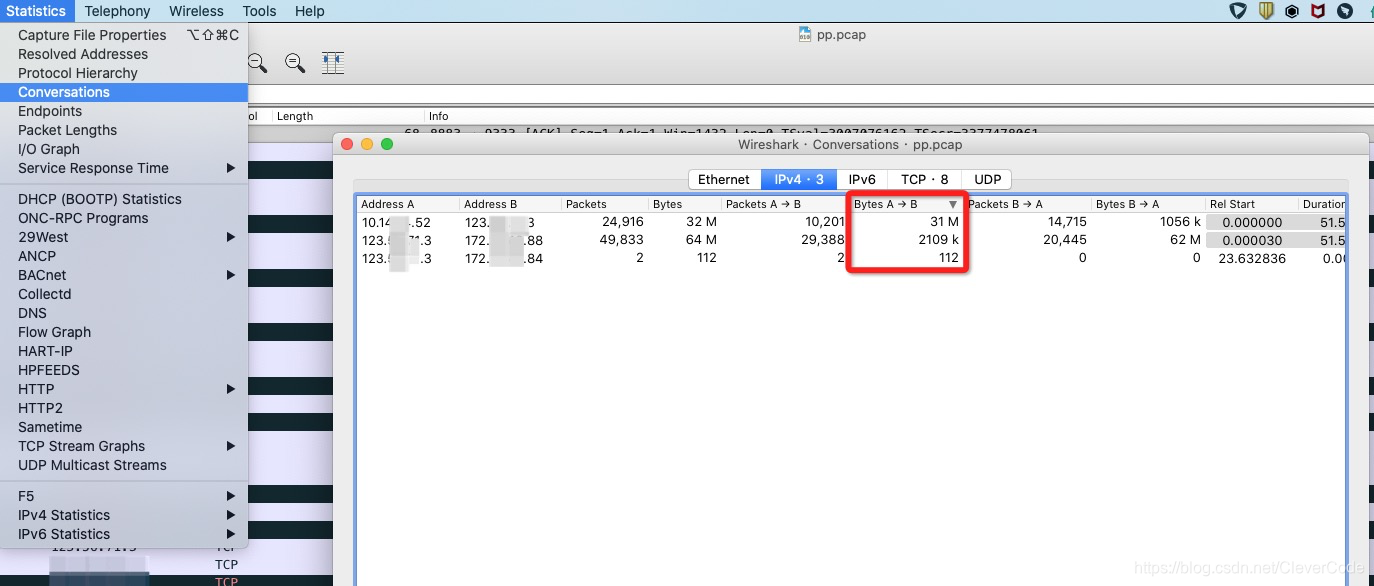
13,01:00,联系8xx3的进程的负责人,他们发布在20:35发布的一个配置,让8xx3进行上报进程走了123.x.x3的外网ip。他们进行紧急修复,变成了100.x.x.x的内网ip。流出流量变成下降。
14, 01:05 。8xx3,其实在第8步骤的iftop命令应该可看出来的。这个secure-mqtt其实就是8xx3接口。123.x.x.3是外网Ip。只是这个secure-mqtt是一个加密协议,当时没有仔细查明就是8xx3端口(知识储备不足)。

#参考文档
《Linux使用tcpdump命令抓包保存pcap文件wireshark分析》:https://www.cnblogs.com/bass6/p/5819928.html
《Linux 服务器带宽异常跑满分析解决》:https://blog.csdn.net/qinrenzhi/article/details/82147267
技术交流
欢迎关注我的微信公众号:程序员大宝。一个乐于分享的程序员!关注免费领取架构师学习资料和精选大厂高频面试题库。
















 356
356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









