








在我们之前的博文中,我们开始探索为ClickHouse开发的6种不同联接算法。作为提醒:这些算法决定了联接查询的计划和执行方式。ClickHouse可以根据资源的可用性和使用情况自适应选择和动态更改运行时使用的联接算法。然而,ClickHouse还允许用户自行指定所需的联接算法。下面的图表基于相对内存消耗和执行时间,概述了这些算法:
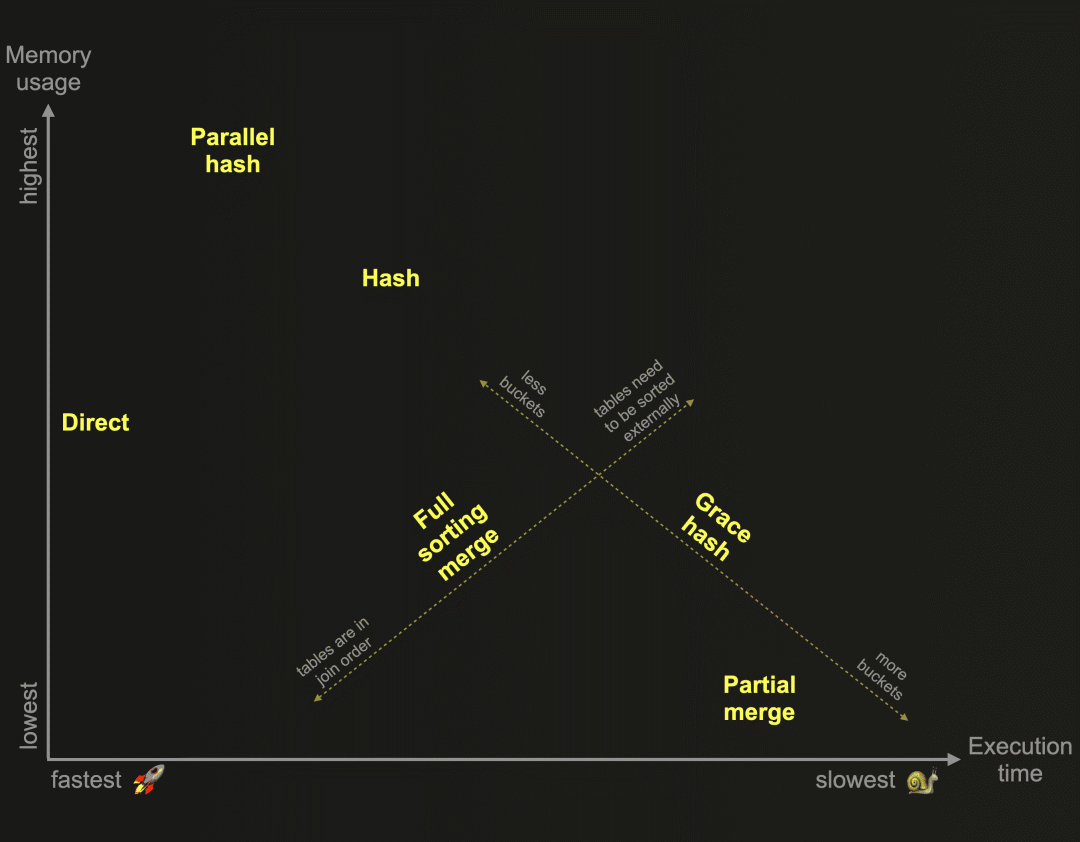
在我们之前的博文中,我们详细描述和比较了上图中基于内存哈希表的三种ClickHouse联接算法:
-
Hash join 联接联接
-
Parallel hash join 并行哈希联接
-
Grace hash join 优雅哈希联接
提醒一下:哈希联接和并行哈希联接速度快,但受限于内存。右侧表的联接数据需要适应内存。优雅哈希联接是一种非内存受限版本,可以将数据临时溢出到磁盘,而不需要对数据进行排序,因此克服了其他将数据溢出到磁盘并需要先对数据进行排序的联接算法的性能挑战。这让我们来到了这篇博文。
在本文中,我们将继续探索ClickHouse联接算法,并描述上图中基于外部排序的两种算法:
-
Full sorting merge join 全排序合并联接
-
Partial merge join 部分合并联接
这两种算法都不受内存限制,并使用联接策略,要求联接数据在联接键的顺序中首先进行排序,然后才能识别联接匹配。
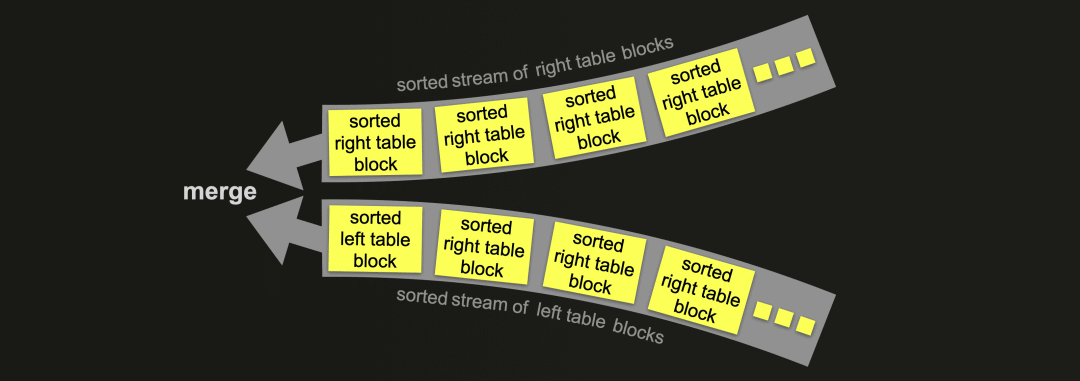
完全排序合并联接通过交错线性扫描和合并来联接两个表的行,这些行来自于两个表中的已排序行块的已排序流:
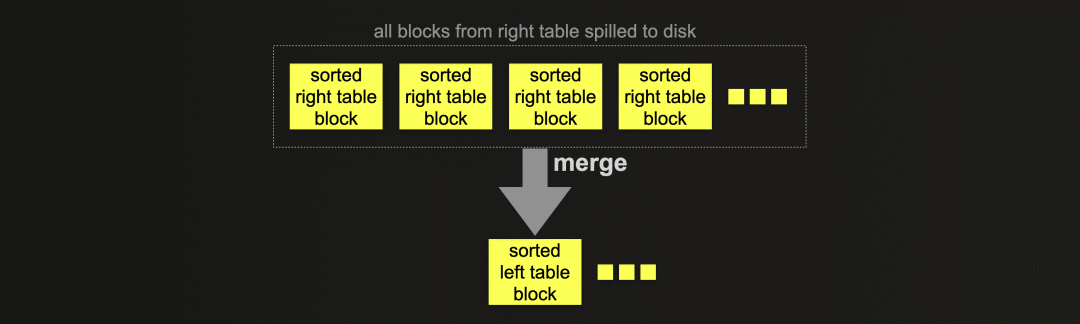
部分排序合并联接通过将左表的每个已排序行块与右表的已排序行块进行合并,来联接两个表的行:
完全排序合并联接可以利用一个或两个表的物理行顺序,从而跳过排序。在这种情况下,联接性能可以与上图中的哈希联接算法竞争,同时通常需要更少的内存。否则,完全排序合并联接需要在识别联接匹配之前完全排序表的行。排序可以在内存中进行(如果数据适合)或在外部磁盘上进行。
部分排序合并联接在处理大表联接时优化了内存使用。右表总是通过外部排序进行完全排序。为了在识别联接匹配时最小化处理在内存中的数据量,特殊的索引结构会在磁盘上创建。左表总是以块为单位在内存中进行排序。但如果左表的物理行顺序与联接键排序顺序匹配,则内存中识别联接匹配更高效。
我们将在下一篇博文中结束对ClickHouse联接算法的探索,并描述上图中ClickHouse最快的联接算法:
-
Direct join 直接联接
测试配置
我们使用与之前的博文中介绍的相同的两个表和ClickHouse Cloud服务实例。
对于所有示例查询运行,我们使用max_threads的默认设置。执行查询的节点有30个CPU核心,因此默认的 max_threads 设置为30。为了使查询管道的可视化简洁和可读,我们通过设置 max_threads = 2 人为地限制了ClickHouse查询管道中使用的并行级别。
现在让我们继续探索ClickHouse来联接算法。
全排序联接
描述
完全排序合并联接算法是集成到ClickHouse查询管道中的经典排序-合并联接。
ClickHouse版本的排序-合并联接提供了几个性能优化。
-
在进行任何排序和合并操作之前,联接的表可以通过彼此的联接键进行过滤,以最小化处理的数据量。
-
如果一个或两个表的物理行顺序与联接键的排序顺序相匹配,则对应表的排序阶段将被跳过。
我们将在后面详细讨论这些优化。
下图显示了未应用任何优化的全排序合并联接算法的一般版本:
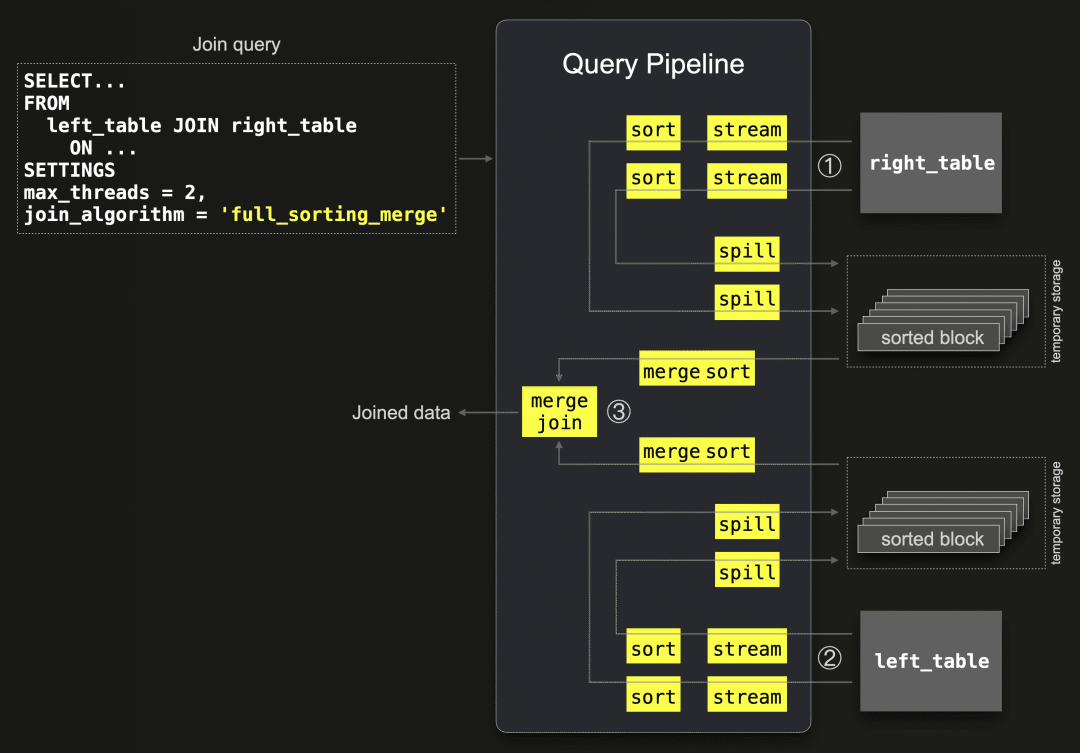
① 从右表格中的所有数据以块为单位并行地通过2个流式传输阶段(因为 max_threads = 2 )流式传输到内存中。两个并行的排序阶段按联接键列的值对每个流式传输的块中的行进行排序。这些排序后的块通过两个并行的溢出阶段溢出到临时存储中。
② 与①同时进行,左表格的所有数据以块为单位并行地通过2个线程( max_threads = 2 )流式传输,类似于①,每个块都会进行排序并溢出到磁盘上。
③ 以每个表格一个流的方式,从磁盘上读取排序后的块,并进行合并排序,通过合并(交替扫描)两个排序流来识别联接匹配项。
支持的联接类型
支持INNER、LEFT、RIGHT和FULL联接类型以及ALL和ANY严格度的所有联接。
示例
为了首先演示未应用任何优化的全排序合并联接算法的一般版本,我们使用一个联接查询,查找在电影中将演员的名字用作角色名的所有演员。通过设置 max_rows_in_set_to_optimize_join=0 ,我们禁用了在联接之前按照联接键过滤联接表的优化操作:
SELECT *
FROM actors AS a
JOIN roles AS r ON a.first_name = r.role
FORMAT `Null`
SETTINGS join_algorithm = 'full_sorting_merge', max_rows_in_set_to_optimize_join = 0;
0 rows in set. Elapsed: 11.559 sec. Processed 101.00 million rows, 3.67 GB (8.74 million rows/s., 317.15 MB/s.)像往常一样,我们可以查询query_log系统表以检查最后一个查询运行的运行时统计信息。请注意,我们使用ProfileEvents列中的一些键来检查在联接处理过程中通过外部排序溢出到磁盘的数据量:
SELECT
query,
formatReadableTimeDelta(query_duration_ms / 1000) AS query_duration,
formatReadableSize(memory_usage) AS memory_usage,
formatReadableQuantity(read_rows) AS read_rows,
formatReadableSize(read_bytes) AS read_data,
formatReadableSize(ProfileEvents['ExternalProcessingUncompressedBytesTotal']) AS data_spilled_to_disk_uncompressed,
formatReadableSize(ProfileEvents['ExternalProcessingCompressedBytesTotal']) AS data_spilled_to_disk_compressed
FROM clusterAllReplicas(default, system.query_log)
WHERE (type = 'QueryFinish') AND hasAll(tables, ['imdb_large.actors', 'imdb_large.roles'])
ORDER BY initial_query_start_time DESC
LIMIT 1
FORMAT Vertical;
Row 1:
──────
query: SELECT *
FROM actors AS a
JOIN roles AS r ON a.first_name = r.role
FORMAT `Null`
SETTINGS join_algorithm = 'full_sorting_merge',
max_rows_in_set_to_optimize_join = 0;
query_duration: 11 seconds
memory_usage: 4.71 GiB
read_rows: 101.00 million
read_data: 3.41 GiB
data_spilled_to_disk_uncompressed: 0.00 B
data_spilled_to_disk_compressed: 0.00 B我们可以看到,ClickHouse没有将任何数据溢出到磁盘,并且完全在内存中处理了联接,内存使用峰值为4.71 GiB。
执行上述查询的ClickHouse节点具有可用的120 GiB主内存。
SELECT formatReadableSize(getSetting('max_memory_usage'));
┌─formatReadableSize(getSetting('max_memory_usage'))─┐
│ 120.00 GiB │
└────────────────────────────────────────────────────┘当要排序的数据量超过可用主内存的一半时,ClickHouse会配置为使用外部排序。
SELECT formatReadableSize(getSetting('max_bytes_before_external_sort'));
┌─formatReadableSize(getSetting('max_bytes_before_external_sort'))─┐
│ 60.00 GiB │
└──────────────────────────────────────────────────────────────────┘我们可以通过在查询的SETTINGS子句中将 max_bytes_before_external_sort 设置为较低的阈值来触发联接示例查询的外部排序:
SELECT *
FROM actors AS a
JOIN roles AS r ON a.first_name = r.role
FORMAT `Null`
SETTINGS join_algorithm = 'full_sorting_merge', max_rows_in_set_to_optimize_join = 0, max_bytes_before_external_sort = '100M';
0 rows in set. Elapsed: 12.267 sec. Processed 132.92 million rows, 4.82 GB (10.84 million rows/s., 393.25 MB/s.)我们为最好连词的联接示例检查实时统计数据:
SELECT
query,
formatReadableTimeDelta(query_duration_ms / 1000) AS query_duration,
formatReadableSize(memory_usage) AS memory_usage,
formatReadableQuantity(read_rows) AS read_rows,
formatReadableSize(read_bytes) AS read_data,
formatReadableSize(ProfileEvents['ExternalProcessingUncompressedBytesTotal']) AS data_spilled_to_disk_uncompressed,
formatReadableSize(ProfileEvents['ExternalProcessingCompressedBytesTotal']) AS data_spilled_to_disk_compressed
FROM clusterAllReplicas(default, system.query_log)
WHERE (type = 'QueryFinish') AND hasAll(tables, ['imdb_large.actors', 'imdb_large.roles'])
ORDER BY initial_query_start_time DESC
LIMIT 2
FORMAT Vertical;
Row 1:
──────
query: SELECT *
FROM actors AS a
JOIN roles AS r ON a.first_name = r.role
FORMAT `Null`
SETTINGS join_algorithm = 'full_sorting_merge',
max_rows_in_set_to_optimize_join = 0,
max_bytes_before_external_sort = '100M'
query_duration: 12 seconds
memory_usage: 3.49 GiB
read_rows: 132.92 million
read_data: 4.49 GiB
data_spilled_to_disk_uncompressed: 1.79 GiB
data_spilled_to_disk_compressed: 866.36 MiB
Row 2:
──────
query: SELECT *
FROM actors AS a
JOIN roles AS r ON a.first_name = r.role
FORMAT `Null`
SETTINGS join_algorithm = 'full_sorting_merge',
max_rows_in_set_to_optimize_join = 0
query_duration: 11 seconds
memory_usage: 4.71 GiB
read_rows: 101.00 million
read_data: 3.41 GiB
data_spilled_to_disk_uncompressed: 0.00 B
data_spilled_to_disk_compressed: 0.00 B我们可以看到,对于使用降低的 max_bytes_before_external_sort 设置运行的查询,使用的内存较少,并且数据溢出到磁盘,表明使用了外部排序。请注意,此查询的 read_rows 指标对于具有外部处理的管道目前不是精确的
查询流水线和追踪日志
如同在本博客系列的前一部分中所做的那样,我们可以使用ClickHouse命令行客户端(快速安装说明在此处)来检查示例联接查询的ClickHouse查询管道(max_threads设置为2)。我们使用EXPLAIN语句来打印用DOT图形描述语言描述的查询管道图,并使用Graphviz dot将图形呈现为PDF格式:
clickhouse client --host ekyyw56ard.us-west-2.aws.clickhouse.cloud --secure --port 9440 --password <PASSWORD> --database=imdb_large --query "
EXPLAIN pipeline graph=1, compact=0
SELECT *
FROM actors AS a
JOIN roles AS r ON a.first_name = r.role
SETTINGS max_threads = 2, join_algorithm = 'full_sorting_merge', max_rows_in_set_to_optimize_join = 0
;" | dot -Tpdf > pipeline.pdf我们使用与上面的抽象图中相同的编号注释了管道,稍微简化了主要阶段的名称,并添加了两个联接的表格以对齐这两个图表:
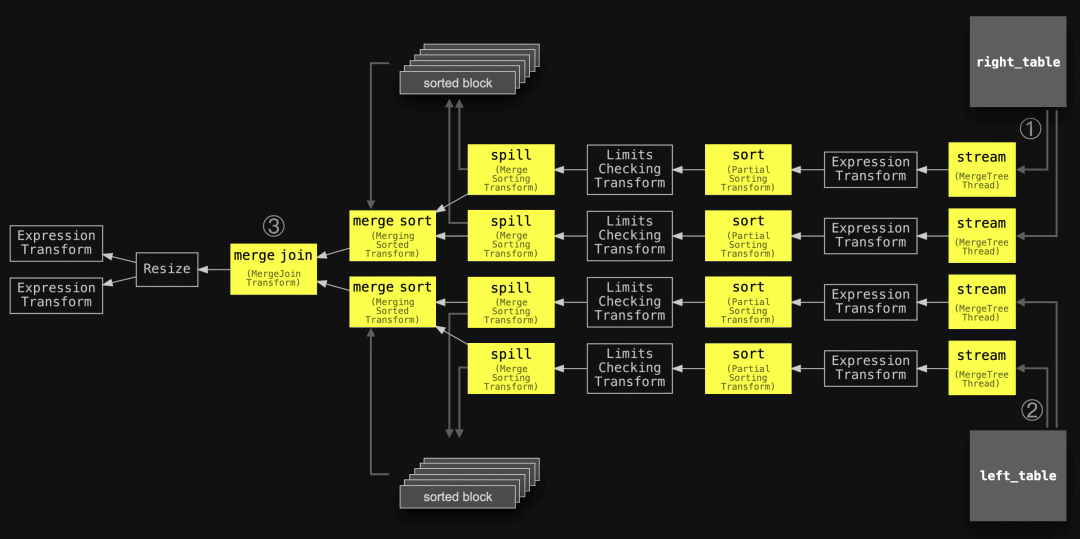
我们可以看到查询管道与上面的抽象版本相匹配。
请注意,如果要排序的块数据的峰值内存占用量保持在配置的外部排序阈值以下,则会忽略溢出阶段,并且排序后的块会立即进行合并排序和联接。
另请注意,要排序的块数据的峰值内存占用量与两个联接表中的总数据量关系不大,而更多地取决于查询管道内配置的并行级别。在ClickHouse中,数据是流式处理的:数据以并行和块方式流式传输到(内存中的)查询引擎中。流式传输的数据块按顺序和并行方式由特定的查询管道阶段进行处理,因此一旦一些表示(部分)查询结果的块可用,它们就会从内存中流式传输回查询的发送方。
为了观察外部排序和数据溢出到磁盘,我们通过要求ClickHouse在执行期间将跟踪级别的日志发送给ClickHouse命令行客户端,来检查两个示例联接查询运行的实际执行情况。
首先,我们获取降低了外部排序阈值的查询运行的跟踪日志:
clickhouse client --host ea3kq2u4fm.eu-west-1.aws.clickhouse.cloud --secure --password <PASSWORD> --database=imdb_large --send_logs_level='trace' --query "
SELECT *
FROM actors AS a
JOIN roles AS r ON a.first_name = r.role
FORMAT `Null`
SETTINGS join_algorithm = 'full_sorting_merge', max_rows_in_set_to_optimize_join = 0, max_bytes_before_external_sort = '100M';"
...
... imdb_large.actors ... : Reading approx. 1000000 rows with 6 streams
...
... imdb_large.roles ... : Reading approx. 100000000 rows with 30 streams
...
... MergeSortingTransform: ... writing part of data into temporary file …
...
... MergingSortedTransform: Merge sorted … blocks, … rows in … sec., … rows/sec., … MiB/sec
...
... MergeJoinAlgorithm: Finished processing in … seconds, left: 16 blocks, 1000000 rows; right: 1529 blocks, 100000000 rows, max blocks loaded to memory: 3
...在分析上述跟踪日志条目之前,快速提醒一下,我们对所有示例查询运行使用了默认的 max_threads 设置。该设置控制查询管道内的并行级别。执行查询的节点具有30个CPU核心,因此默认的 max_threads 设置为30。为了使查询管道的可视化简洁和可读性好,我们人为地限制了ClickHouse查询管道中使用的并行级别,将设置 max_threads = 2 。
我们可以看到有6个并行流和30个并行流分别用于以块为单位将数据从两个表格流式传输到查询引擎中。这是因为 max_threads 设置为30。请注意,仅使用了6个并行流,而不是30个并行流,用于包含100万行的 actors 表。这是因为设置了merge_tree_min_rows_for_concurrent_read_for_remote_filesystem(对于云端而言,对于OSS而言,设置为merge_tree_min_rows_for_concurrent_read)。该设置配置了单个查询执行线程应该至少读取/处理的最小行数。默认值为163,840行。而1百万行/163,840行=6个线程。对于包含1亿行的 roles 表,结果将为610个线程,超过了我们配置的最大值30个线程。
此外,我们还可以看到MergeSortingTransform(在上面的图表中被简化为'spill')阶段的条目,指示数据(排序后的块的数据)溢出到磁盘上的临时存储中。MergingSortedTransform阶段(在上面的图表中称为'merge sort')的条目总结了从临时存储中读取的排序块的合并排序过程。
最后的MergeJoinAlgorithm条目总结了联接处理过程:来自左表的1百万行以块为单位(通过6个并行流)以16个块的形式流式传输(每个块中约62500行-接近默认块大小)。来自右表的1亿行以块为单位(通过30个并行流)以1529个块的形式流式传输(每个块中约65400行)。在流式处理过程中,在 merge join 阶段同时最多在内存中保存3个具有相同联接键的块中的行。对于我们示例查询中INNER联接的ALL严格性而言,这些行的笛卡尔乘积在内存中完成。
接下来,我们获取没有降低外部排序阈值的查询运行的跟踪日志:
clickhouse client --host ea3kq2u4fm.eu-west-1.aws.clickhouse.cloud --secure --password <PASSWORD> --database=imdb_large --send_logs_level='trace' --query "
SELECT *
FROM actors AS a
JOIN roles AS r ON a.first_name = r.role
FORMAT `Null`
SETTINGS join_algorithm = 'full_sorting_merge', max_rows_in_set_to_optimize_join = 0;"
...
... imdb_large.actors ... : Reading approx. 1000000 rows with 6 streams
...
... imdb_large.roles ... : Reading approx. 100000000 rows with 30 streams
...
... MergingSortedTransform: Merge sorted … blocks, … rows in … sec., … rows/sec., … MiB/sec
...
... MergeJoinAlgorithm: Finished processing in … seconds, left: 16 blocks, 1000000 rows; right: 1529 blocks, 100000000 rows, max blocks loaded to memory: 3
...日志条目表明查询执行未触发任何数据溢出到磁盘,因为块数据的内存中峰值体积保持在默认的外部排序阈值以下。因此,溢出阶段被跳过,排序块立即进行了合并排序和联接操作,而无需进行基于磁盘的排序。
扩展
在上一篇文章中,我们解释了 "max_threads "设置可控制查询流水线的并行程度。为了提高可读性,我们人为地限制了查询管道可视化的并行程度,设置为 max_threads=2。
现在我们可以检查 max_threads 设置为 4 的完全排序合并联接查询的查询流程图:
clickhouse client --host ekyyw56ard.us-west-2.aws.clickhouse.cloud --secure --port 9440 --password <PASSWORD> --database=imdb_large --query "
EXPLAIN pipeline graph=1, compact=0
SELECT *
FROM actors AS a
JOIN roles AS r ON a.first_name = r.role
SETTINGS max_threads = 4, join_algorithm = 'full_sorting_merge', max_rows_in_set_to_optimize_join = 0
;" | dot -Tpdf > pipeline.pdf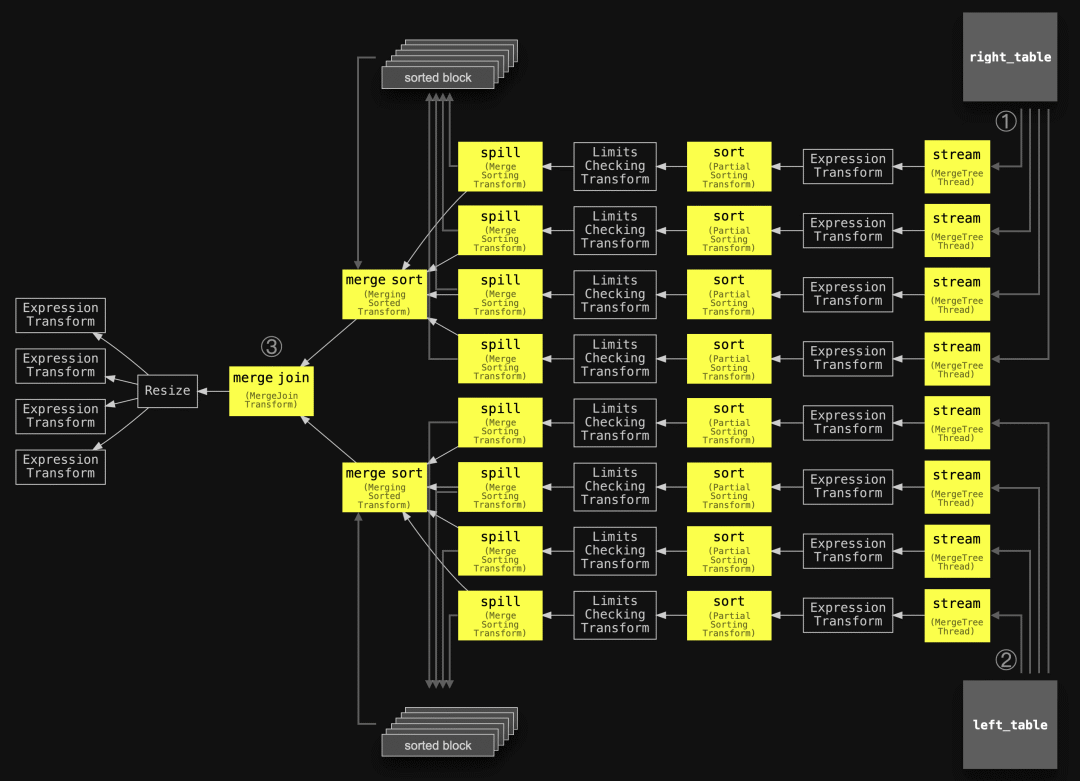
现在每个表都使用了四个并行的流、排序和溢出阶段。这加速了数据块的(外部)排序。然而,每个表的合并排序阶段和最终的合并联接阶段需要保持单线程以确保正确运行。不过,ClickHouse还提供了一些附加的性能优化方法,我们接下来将讨论这些优化方法。
优化
在联接之前,通过使用彼此的联接键值对表进行筛选。
在排序合并联接之前,可以通过彼此的联接键对加入的表进行过滤,以最小化需要排序和合并的数据量。为此,如果可能的话(见下文),ClickHouse会构建一个内存集合,其中包含右表的联接键列的(唯一)值,并使用该集合过滤掉左表中所有不可能有联接匹配的行,反之亦然。如果一张表比另一张表小得多,并且表的唯一联接键列值适合内存,那么这个方法尤其有效。
哈希联接在这种情况下也会表现良好。但是,完全排序合并联接以相同的方式适用于左表和右表,在两个表都大于可用内存的情况下,它将自动回退到外部排序。这种优化是为了将哈希联接的性能带到完全排序合并联接的特定用例中。max_rows_in_set_to_optimize_join设置控制着这种优化。将其设置为0会禁用它。默认值为100,000。该值指定了两个表集合的最大允许大小(按条目计算)。这意味着如果两个集合加在一起仍然低于阈值,则优化将应用于两个表。如果两个集合加在一起超过了阈值,那么仍然可能有一个集合低于阈值,并且优化将仅应用于一个表。正如我们将在下面的跟踪日志中看到的那样,ClickHouse将顺序尝试为两个表构建集合,并在超过限制时进行回退和跳过构建集合。
我们的示例联接查询是通过 first_name 和 role 列进行联接的:
SELECT *
FROM actors AS a
JOIN roles AS r ON a.first_name = r.role
FORMAT `Null`
SETTINGS join_algorithm = 'full_sorting_merge';我们检查(较小的)左表中唯一联接键列值的数量:
SELECT countDistinct(first_name)
FROM actors;
┌─uniqExact(first_name)─┐
│ 109993 │
└───────────────────────┘然后,我们检查(较大的)右表中唯一联接键列值的数量:
SELECT countDistinct(role)
FROM roles;
┌─uniqExact(role)─┐
│ 999999 │
└─────────────────┘使用 max_rows_in_set_to_optimize_join 设置的默认值100,000,该优化不会应用于任何表。
为了演示,我们使用 max_rows_in_set_to_optimize_join 的默认值执行示例查询:
SELECT *
FROM actors AS a
JOIN roles AS r ON a.first_name = r.role
FORMAT `Null`
SETTINGS join_algorithm = 'full_sorting_merge';
0 rows in set. Elapsed: 11.602 sec. Processed 101.00 million rows, 3.67 GB (8.71 million rows/s., 315.97 MB/s.)现在,我们执行带有 max_rows_in_set_to_optimize_join 设置为 200,000 的示例查询。请注意,这个限制对于构建两个表的集合来说仍然太低。但它允许构建较小的左表的集合,这是这种优化的主要思想,即当一个表远小于另一个表,并且表的唯一联接键列值适合内存时,它的效果尤其好:
SELECT *
FROM actors AS a
JOIN roles AS r ON a.first_name = r.role
FORMAT `Null`
SETTINGS join_algorithm = 'full_sorting_merge', max_rows_in_set_to_optimize_join = 200_000;
0 rows in set. Elapsed: 2.156 sec. Processed 101.00 million rows, 3.67 GB (46.84 million rows/s., 1.70 GB/s.)我们已经可以看到更快的执行时间。让我们检查一下两个查询运行的运行时统计信息,以获取更多细节:
SELECT
query,
formatReadableTimeDelta(query_duration_ms / 1000) AS query_duration,
formatReadableSize(memory_usage) AS memory_usage,
formatReadableQuantity(read_rows) AS read_rows,
formatReadableSize(read_bytes) AS read_data,
formatReadableSize(ProfileEvents['ExternalProcessingUncompressedBytesTotal']) AS data_spilled_to_disk_uncompressed,
formatReadableSize(ProfileEvents['ExternalProcessingCompressedBytesTotal']) AS data_spilled_to_disk_compressed
FROM clusterAllReplicas(default, system.query_log)
WHERE (type = 'QueryFinish') AND hasAll(tables, ['imdb_large.actors', 'imdb_large.roles'])
ORDER BY initial_query_start_time DESC
LIMIT 2
FORMAT Vertical;
Row 1:
──────
query: SELECT *
FROM actors AS a
JOIN roles AS r ON a.first_name = r.role
FORMAT `Null`
SETTINGS join_algorithm = 'full_sorting_merge',
max_rows_in_set_to_optimize_join = 200_000;
query_duration: 2 seconds
memory_usage: 793.30 MiB
read_rows: 101.00 million
read_data: 3.41 GiB
data_spilled_to_disk_uncompressed: 0.00 B
data_spilled_to_disk_compressed: 0.00 B
Row 2:
──────
query: SELECT *
FROM actors AS a
JOIN roles AS r ON a.first_name = r.role
FORMAT `Null`
SETTINGS join_algorithm = 'full_sorting_merge';
query_duration: 11 seconds
memory_usage: 4.71 GiB
read_rows: 101.00 million
read_data: 3.41 GiB
data_spilled_to_disk_uncompressed: 0.00 B
data_spilled_to_disk_compressed: 0.00 B我们可以看到预过滤优化的效果:执行时间快了5倍,峰值内存消耗减少了约6倍。
现在我们来检查启用了优化的查询流程:
clickhouse client --host ekyyw56ard.us-west-2.aws.clickhouse.cloud --secure --port 9440 --password <PASSWORD> --database=imdb_large --query "
EXPLAIN pipeline graph=1, compact=0
SELECT *
FROM actors AS a
JOIN roles AS r ON a.first_name = r.role
SETTINGS max_threads = 2, join_algorithm = 'full_sorting_merge';" | dot -Tpdf > pipeline.pdf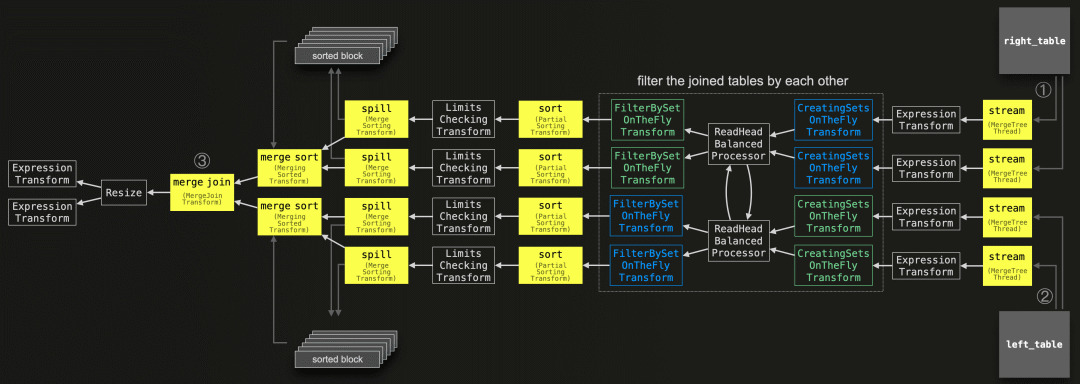
与未应用任何优化的全排序合并联接算法的通用版本相比,我们可以看到额外的阶段(在上面的图表中以蓝色和绿色表示)。这些阶段负责在联接之前通过彼此的联接键值来过滤两个表:
如果可能的话,使用两个并行的蓝色 CreatingSetsOnTheFlyTransform 阶段来构建包含右表联接键列值的内存集合。然后,这个集合由两个并行的蓝色 FilterBySetOnTheFlyTransform 阶段使用,用于过滤掉左表中所有不可能有联接匹配的行。
如果可能的话,使用两个并行的绿色 CreatingSetsOnTheFlyTransform 阶段来构建包含左表联接键列值的内存集合。然后,这个集合由两个并行的绿色 FilterBySetOnTheFlyTransform 阶段使用,用于过滤掉右表中所有不可能有联接匹配的行。
在这些集合从联接键列中完全构建之前,通过并行块来流式传输包含所有所需列的行,绕过过滤优化以便对每个块内的行按其联接键进行排序并(可能)将其溢写到磁盘。过滤器仅在集合准备好之后开始工作。这就是为什么还有两个 ReadHeadBalancedProcessor 阶段。这些阶段确保在集合准备好之前,以两个表的总大小成比例的方式从两个表中流式传输数据,以防止在小表用于过滤之前,大表的数据大部分被处理完的情况发生。
为了检查这些额外阶段的执行情况,我们查看查询执行的跟踪日志:
clickhouse client --host ea3kq2u4fm.eu-west-1.aws.clickhouse.cloud --secure --password <PASSWORD> --database=imdb_large --send_logs_level='trace' --query "
SELECT *
FROM actors AS a
JOIN roles AS r ON a.first_name = r.role
FORMAT `Null`
SETTINGS join_algorithm = 'full_sorting_merge', max_rows_in_set_to_optimize_join = 200_000;"
...
... imdb_large.actors ... : Reading approx. 1000000 rows with 6 streams
...
... imdb_large.roles ... : Reading approx. 100000000 rows with 30 streams
...
... CreatingSetsOnTheFlyTransform: Create set and filter Right joined stream: set limit exceeded, give up building set, after reading 577468 rows and using 96.00 MiB
...
... CreatingSetsOnTheFlyTransform: Create set and filter Left joined stream: finish building set for [first_name] with 109993 rows, set size is 6.00 MiB
...
... FilterBySetOnTheFlyTransform: Finished create set and filter right joined stream by [role]: consumed 3334144 rows in total, 573440 rows bypassed, result 642125 rows, 80.74% filtered
... FilterBySetOnTheFlyTransform: Finished create set and filter right joined stream by [role]: consumed 3334144 rows in total, 573440 rows bypassed, result 642125 rows, 80.74% filtered
...
... MergingSortedTransform: Merge sorted … blocks, … rows in … sec., … rows/sec., … MiB/sec
...
... MergeJoinAlgorithm: Finished processing in 3.140038835 seconds, left: 16 blocks, 1000000 rows; right: 207 blocks, 13480274 rows, max blocks loaded to memory: 3
...我们看到使用6个并行流和30个并行流来将数据从两个表流式传输到查询引擎。
接下来,我们看到了一个 CreatingSetsOnTheFlyTransform 阶段的条目,表明无法构建包含右表联接键列的内存集,因为条目数量将超过 max_rows_in_set_to_optimize_join 设置的阈值200000。
另一个 CreatingSetsOnTheFlyTransform 阶段的条目显示成功构建了包含左表联接键列的集合。该集合用于过滤右表的行,这由 FilterBySetOnTheFlyTransform 阶段的30个条目表示(我们只显示前两个条目,省略其余的)。30个条目对应于ClickHouse使用30个并行流阶段从右表流式传输行,并使用30个并行的 FilterBySetOnTheFlyTransform 阶段来过滤这30个流。
优化物理行顺序
如果一个或两个联接的表的物理行顺序与联接键排序顺序匹配,则完整排序合并联接算法的排序阶段将被跳过。
我们可以通过检查使用与两个表的排序键匹配的联接键的联接查询的查询流程来验证这一点。首先,我们检查两个联接表的排序键:
SELECT
name AS table,
sorting_key
FROM system.tables
WHERE database = 'imdb_large';
┌─table───────┬─sorting_key───────────────────────┐
│ actors │ id, first_name, last_name, gender │
│ roles │ actor_id, movie_id │
└─────────────┴───────────────────────────────────┘我们使用一个联接查询,通过将两个示例表按照 actors 表的 id 和 roles 表的 actor_id 联接,找到每个演员的所有角色。这些联接键是表的排序键的前缀,使得ClickHouse可以通过按照它们在磁盘上存储的顺序读取来自两个表的行来跳过完整排序合并算法的排序阶段。
我们检查这个查询的查询流程:
clickhouse client --host ekyyw56ard.us-west-2.aws.clickhouse.cloud --secure --port 9440 --password <PASSWORD> --database=imdb_large --query "
EXPLAIN pipeline graph=1, compact=0
SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
SETTINGS max_threads = 2, join_algorithm = 'full_sorting_merge', max_rows_in_set_to_optimize_join = 0, max_bytes_before_external_sort = '100M';" | dot -Tpdf > pipeline.pdf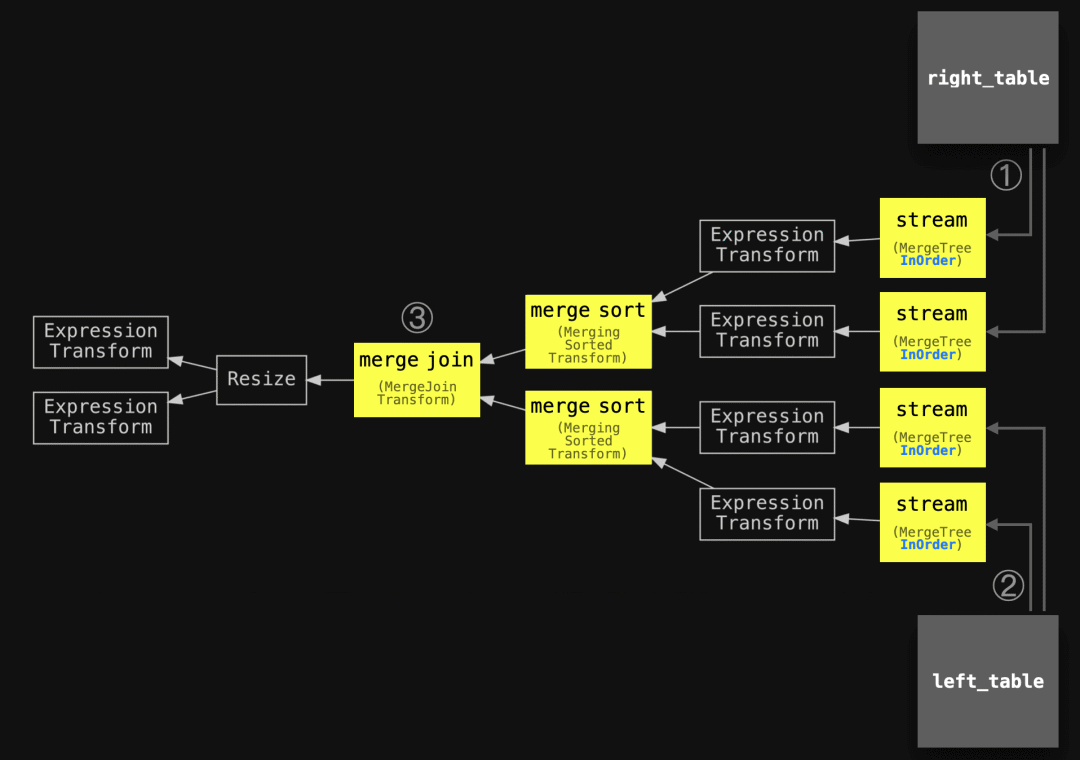
我们可以看到查询流程中的①和②是两个并行的流式传输阶段,每个表使用两个流式传输阶段(因为 max_threads 设置为2),将行以块为单位从两个表中流式传输到查询引擎中。
请注意缺少排序和溢写阶段。已经排序的块会按表进行合并排序,然后通过合并(交叉扫描)两个排序的流来识别③的联接匹配。
我们运行了不包含排序和溢写阶段的查询。请注意,目前只有在 max_rows_in_set_to_optimize_join 设置被禁用时才应用读取顺序优化。有一个待处理的PR,在ClickHouse能够按顺序读取数据时自动禁用该设置。ClickHouse不支持同时进行按顺序优化和预过滤。有了上面提到的PR,将优先选择按顺序优化:
SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'full_sorting_merge', max_rows_in_set_to_optimize_join = 0;
0 rows in set. Elapsed: 7.280 sec. Processed 101.00 million rows, 3.67 GB (13.87 million rows/s., 503.56 MB/s.)为了进行比较,我们运行了相同的查询,通过不禁用 max_rows_in_set_to_optimize_join 设置来强制排序:
SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'full_sorting_merge';
0 rows in set. Elapsed: 7.542 sec. Processed 101.00 million rows, 3.67 GB (13.39 million rows/s., 486.09 MB/s.)为了进一步进行比较,我们运行了相同的查询,通过不禁用 max_rows_in_set_to_optimize_join 设置并降低 max_bytes_before_external_sort 值来强制进行外部排序:
SELECT *
FROM actors AS a
INNER JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'full_sorting_merge', max_bytes_before_external_sort = '100M';
0 rows in set. Elapsed: 8.332 sec. Processed 139.35 million rows, 5.06 GB (16.72 million rows/s., 606.93 MB/s.)我们检查最近三次查询运行的运行时间统计:
SELECT
query,
formatReadableTimeDelta(query_duration_ms / 1000) AS query_duration,
formatReadableSize(memory_usage) AS memory_usage,
formatReadableQuantity(read_rows) AS read_rows,
formatReadableSize(read_bytes) AS read_data,
formatReadableSize(ProfileEvents['ExternalProcessingUncompressedBytesTotal']) AS data_spilled_to_disk_uncompressed,
formatReadableSize(ProfileEvents['ExternalProcessingCompressedBytesTotal']) AS data_spilled_to_disk_compressed
FROM clusterAllReplicas(default, system.query_log)
WHERE (type = 'QueryFinish') AND hasAll(tables, ['imdb_large.actors', 'imdb_large.roles'])
ORDER BY initial_query_start_time DESC
LIMIT 3
FORMAT Vertical;
Row 1:
──────
query: SELECT *
FROM actors AS a
INNER JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'full_sorting_merge',
max_bytes_before_external_sort = '100M';
query_duration: 8 seconds
memory_usage: 3.56 GiB
read_rows: 139.35 million
read_data: 4.71 GiB
data_spilled_to_disk_uncompressed: 1.62 GiB
data_spilled_to_disk_compressed: 1.09 GiB
Row 2:
──────
query: SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'full_sorting_merge';
query_duration: 7 seconds
memory_usage: 5.07 GiB
read_rows: 101.00 million
read_data: 3.41 GiB
data_spilled_to_disk_uncompressed: 0.00 B
data_spilled_to_disk_compressed: 0.00 B
Row 3:
──────
query: SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'full_sorting_merge',
max_rows_in_set_to_optimize_join = 0;
query_duration: 7 seconds
memory_usage: 497.88 MiB
read_rows: 101.00 million
read_data: 3.41 GiB
data_spilled_to_disk_uncompressed: 0.00 B
data_spilled_to_disk_compressed: 0.00 B第3行的查询运行,跳过了排序和溢出阶段,具有最快的执行时间和非常低的内存使用。因为来自两个表的数据以块为单位通过查询引擎流动,并且按顺序排列,所以只有少量数据块同时存在于内存中,并且只需要进行合并和流回查询的发送方。
我们可以看到在第2行中强制进行排序的查询运行中,排序发生在内存中,因为没有数据被溢出到磁盘。这个查询运行的内存使用量比第3行中没有排序的运行高出10倍。
而在第1行中强制进行外部排序的查询运行中,执行时间最慢,但内存使用量比第2行中强制进行内存排序的查询运行低。
当只有其中一个表的物理行顺序与联接键排序顺序匹配时,流式按顺序优化也会被应用。我们可以通过检查左表通过与表格的物理行顺序匹配的列进行联接的联接查询的查询流程来证明这一点,但对于右表来说,情况并非如此。
clickhouse client --host ekyyw56ard.us-west-2.aws.clickhouse.cloud --secure --port 9440 --password <PASSWORD> --database=imdb_large --query "
EXPLAIN pipeline graph=1, compact=0
SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.movie_id
SETTINGS max_threads = 2, join_algorithm = 'full_sorting_merge', max_rows_in_set_to_optimize_join = 0;" | dot -Tpdf > pipeline.pdf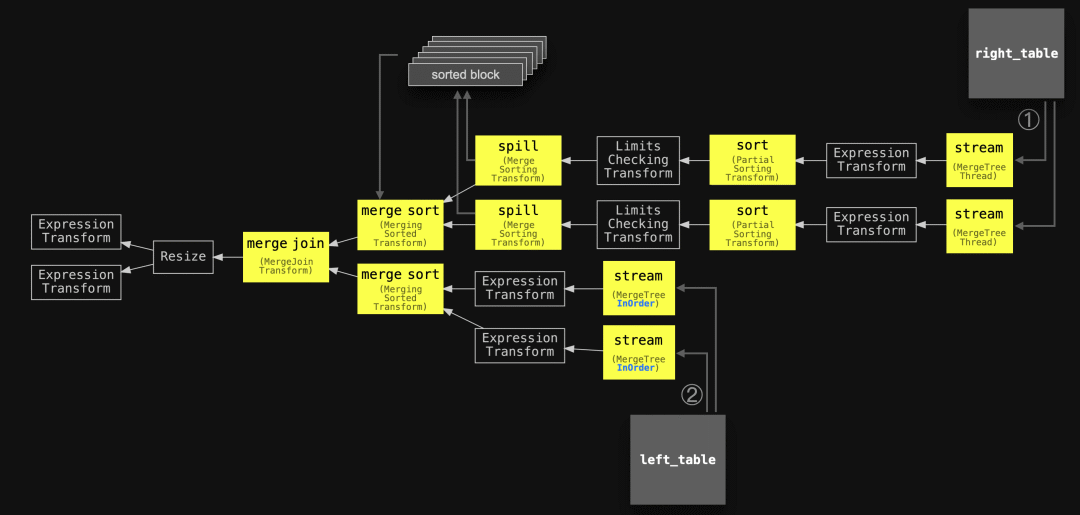
左表的行按顺序通过两个并行流式传输到查询引擎中。这些已经按顺序排列的流的排序和溢出阶段是缺失的。相反,右表的阶段显示了排序和(可能的)溢出。
并行合并联接
描述
ClickHouse的部分合并联接算法是对排序-合并联接的一种优化。当联接大型表时,它通过仅对右表进行外部排序来最小化内存使用。为了减少在内存中处理的数据量,它在磁盘上创建了最小-最大索引。左表始终以块方式和内存中进行排序。但是,如果左表的物理行顺序与联接键的排序顺序匹配,则内存中识别联接匹配更为高效。
该算法的具体步骤如下:
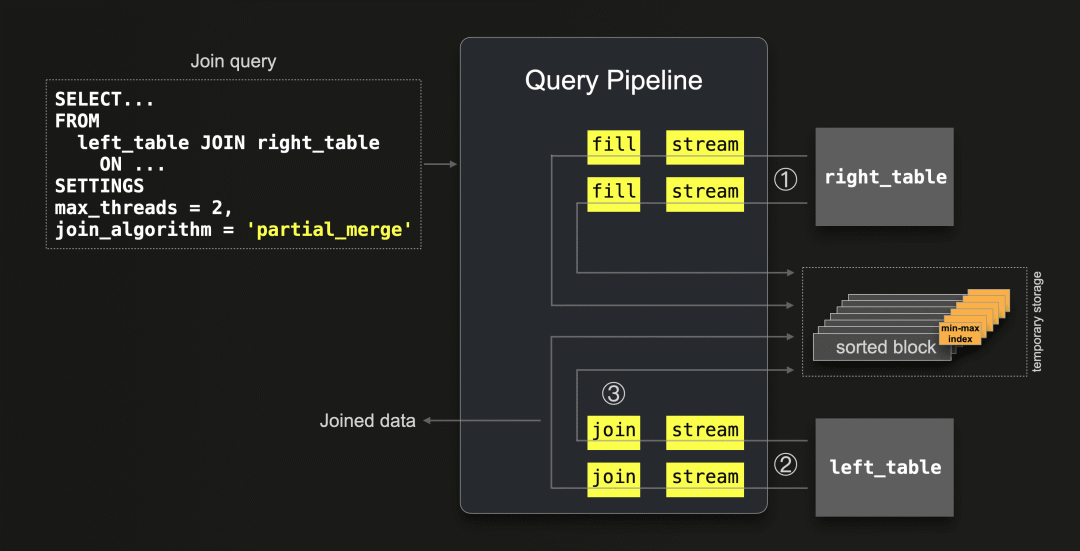
ClickHouse的部分合并联接算法与哈希联接算法的流程非常相似,并且这并非巧合。部分合并联接重用了哈希联接的流程,因为它也具有构建和扫描阶段。回想一下,哈希联接首先从右表构建哈希表,然后扫描左表。类似地,部分合并联接首先构建右表的排序版本,然后扫描左表:
① 首先,将右表的所有数据按块通过并行的两个流(因为 max_threads = 2 )流式传输到内存中。通过填充阶段,对每个流式传输的块中的行按联接键列的值进行排序,并与每个排序块一起将它们溢出到临时存储中。每个排序块都包含一个最小-最大索引,该索引存储了该块包含的联接键的最小和最大值。在步骤 ② 中,通过这些最小-最大索引来最小化内存中处理的数据量,以便在识别联接匹配时使用。
② 然后,所有来自左表的数据按块通过两个流( max_threads = 2)同时流式传输。每个块在流式传输时根据联接键进行即时排序,然后与右表在磁盘上的排序块进行匹配(步骤 ③)。最小-最大索引用于仅加载可能包含联接匹配的右表块。
这种联接处理策略非常高效地利用了内存,无论联接表的大小和物理行顺序如何。在上述的步骤 ① 中,右表的只有少量块在被写入临时存储之前会通过内存进行流式传输。在步骤 ② 中,只有少量块从左表通过内存进行流式传输。步骤 ① 中创建的最小-最大索引有助于最小化从临时存储加载右表块的数量,以识别联接匹配。
需要注意的是,如果左表的物理行顺序与联接键的排序顺序匹配,则基于最小-最大索引的跳过非匹配右表块的操作最为有效。然而,当左表的数据块具有一般分布的联接键值时,使用部分合并联接算法的代价最高。因为如果左表的每个数据块包含一大部分分布广泛的联接键值,那么右表的排序块的最小-最大索引就无法起到作用,实际上会在每个左表块和一大组从磁盘加载的右表排序块之间创建一个笛卡尔积。
支持的联接类型
ClickHouse支持多种联接类型和严格性设置。以下是支持的联接类型和严格性组合列表。
示例
我们使用部分合并算法运行示例联接查询(使用联接键作为联接表排序键的前缀,以从上述基于最小-最大索引的性能优化中获益)。
SELECT *
FROM actors AS a
INNER JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'partial_merge';
0 rows in set. Elapsed: 33.796 sec. Processed 101.00 million rows, 3.67 GB (2.99 million rows/s., 108.47 MB/s.)现在我们运行相同的查询,但是左表在磁盘上具有不同的物理顺序。我们创建了一个按非联接键列排序的演员表副本。这意味着行按照随机的联接键顺序排列。正如上面解释的,这对于部分合并联接的执行时间来说是最糟糕的情况:
SELECT *
FROM actors_unsorted AS a
INNER JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'partial_merge';
0 rows in set. Elapsed: 44.872 sec. Processed 101.00 million rows, 3.67 GB (2.25 million rows/s., 81.70 MB/s.)相比上一次运行,执行时间慢了36%。
为了进一步比较,我们使用完全排序合并算法运行相同的查询。为了与部分合并算法进行公平比较,我们强制进行外部排序。通过禁用完全排序合并算法的“按顺序流式处理优化”(不将 max_rows_in_set_to_optimize_join 设置为0)。并且降低 max_bytes_before_external_sort 的值:
SELECT *
FROM actors AS a
INNER JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'full_sorting_merge', max_bytes_before_external_sort = '100M';
0 rows in set. Elapsed: 7.381 sec. Processed 139.35 million rows, 5.06 GB (18.88 million rows/s., 685.11 MB/s.)我们检查最近三次查询运行的运行时间统计:
SELECT
query,
formatReadableTimeDelta(query_duration_ms / 1000) AS query_duration,
formatReadableSize(memory_usage) AS memory_usage,
formatReadableQuantity(read_rows) AS read_rows,
formatReadableSize(read_bytes) AS read_data,
formatReadableSize(ProfileEvents['ExternalProcessingUncompressedBytesTotal']) AS data_spilled_to_disk_uncompressed,
formatReadableSize(ProfileEvents['ExternalProcessingCompressedBytesTotal']) AS data_spilled_to_disk_compressed
FROM clusterAllReplicas(default, system.query_log)
WHERE (type = 'QueryFinish') AND (hasAll(tables, ['imdb_large.actors', 'imdb_large.roles']) OR hasAll(tables, ['imdb_large.actors_unsorted', 'imdb_large.roles']))
ORDER BY initial_query_start_time DESC
LIMIT 3
FORMAT Vertical;
Row 1:
──────
query: SELECT *
FROM actors AS a
INNER JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'full_sorting_merge',
max_bytes_before_external_sort = '100M';
query_duration: 7 seconds
memory_usage: 3.54 GiB
read_rows: 139.35 million
read_data: 4.71 GiB
data_spilled_to_disk_uncompressed: 1.62 GiB
data_spilled_to_disk_compressed: 1.09 GiB
Row 2:
──────
query: SELECT *
FROM actors_unsorted AS a
INNER JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'partial_merge';
query_duration: 44 seconds
memory_usage: 2.20 GiB
read_rows: 101.00 million
read_data: 3.41 GiB
data_spilled_to_disk_uncompressed: 5.27 GiB
data_spilled_to_disk_compressed: 3.52 GiB
Row 3:
──────
query: SELECT *
FROM actors AS a
INNER JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'partial_merge';
query_duration: 33 seconds
memory_usage: 2.21 GiB
read_rows: 101.00 million
read_data: 3.41 GiB
data_spilled_to_disk_uncompressed: 5.27 GiB
data_spilled_to_disk_compressed: 3.52 GiB在第2行和第3行中,我们可以看到两次部分合并联接的内存使用量和溢出到磁盘的数据量相同。然而,正如上面详细解释的那样,当左表的物理行顺序与联接键顺序匹配时,在第3行的运行中执行速度更快。
即使在联接表的(人为强制)完全外部排序的情况下,第1行的完全排序合并联接的执行速度几乎比第3行的部分合并联接的执行速度快5倍。尽管部分合并联接的设计意图是使用更少的内存。
查询流水线和追踪日志
在 max_threads 设置为 2 的情况下,我们对部分合并联接示例的查询管道进行自省:
clickhouse client --host ekyyw56ard.us-west-2.aws.clickhouse.cloud --secure --port 9440 --password <PASSWORD> --database=imdb_large --query "
EXPLAIN pipeline graph=1, compact=0
SELECT *
FROM actors AS a
JOIN roles AS r ON a.first_name = r.role
SETTINGS max_threads = 2, join_algorithm = 'partial_merge';" | dot -Tpdf > pipeline.pdf为了与上面的抽象图进行对齐,使用了圈出的数字、稍微简化的主要阶段名称和添加的两个联接表:
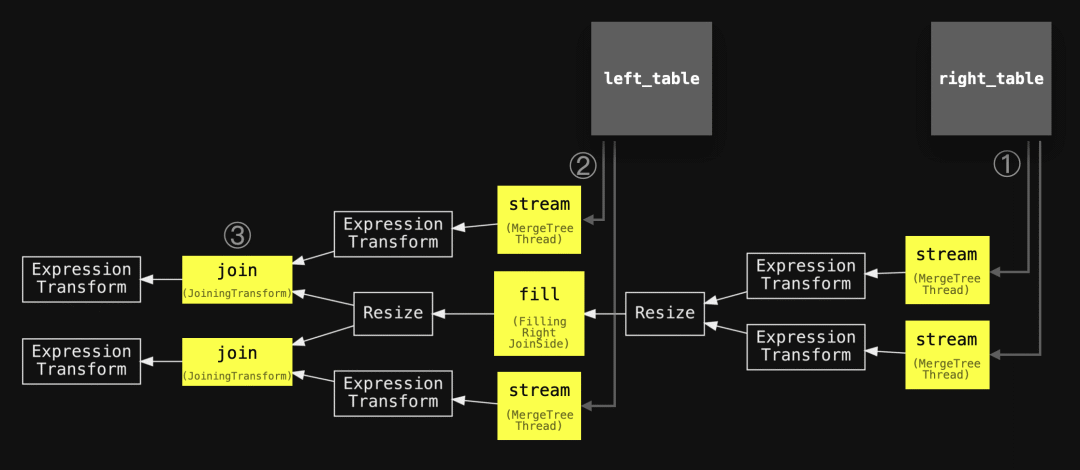
实际的查询流程反映了我们上面的抽象版本。如前所述,部分排序合并联接重用了哈希联接的流程,因为它像哈希联接一样有构建和扫描阶段:部分合并联接首先构建右表的排序版本,然后扫描左表。
由于上述流程重用,右表块的排序和与左表块的排序合并在流程中不直接可见。
为了审查这些阶段的执行情况,我们检查查询执行的跟踪日志:
clickhouse client --host ea3kq2u4fm.eu-west-1.aws.clickhouse.cloud --secure --password <PASSWORD> --database=imdb_large --send_logs_level='trace' --query "
SELECT *
FROM actors AS a
JOIN roles AS r ON a.first_name = r.role
FORMAT `Null`
SETTINGS join_algorithm = 'partial_merge';"
...
... imdb_large.actors ... : Reading approx. 1000000 rows with 6 streams
...
... imdb_large.roles ... : Reading approx. 100000000 rows with 30 streams
...
... MergingSortedTransform: Merge sorted 1528 blocks, 100000000 rows …
...我们可以看到有6个和30个并行流用于以块为单位将数据从两个表流式传输到查询引擎。
一个MergingSortedTransform条目总结了联接处理过程:来自具有1亿行的右表的1528个数据块被排序,然后与左表的块进行合并联接。请注意,100 million行的1528个数据块相当于每个块约为~65445行,这对应于默认的块大小。
总结
这篇博客文章详细描述并比较了两种基于外部排序的ClickHouse联接算法。
完全排序合并联接不受内存限制,基于内存或外部排序,并且可以利用联接表的物理行顺序并跳过排序阶段。在这种情况下,联接性能可以与哈希联接算法竞争,同时通常需要较少的主内存。
部分合并联接针对联接大型表时的最小化内存使用进行了优化,并且始终通过外部排序完全排序右表。左表也总是以块为单位在内存中进行排序。如果左表的物理行顺序与联接键的排序顺序匹配,则联接匹配过程的运行效率更高。
这张图表总结并比较了本文中一些联接查询运行的内存使用和执行时间。我们始终使用相同的联接查询来联接相同的数据,在具有30个CPU核心的节点上(因此将 max_threads 设置为30)将较大的表放在右侧进行运行。
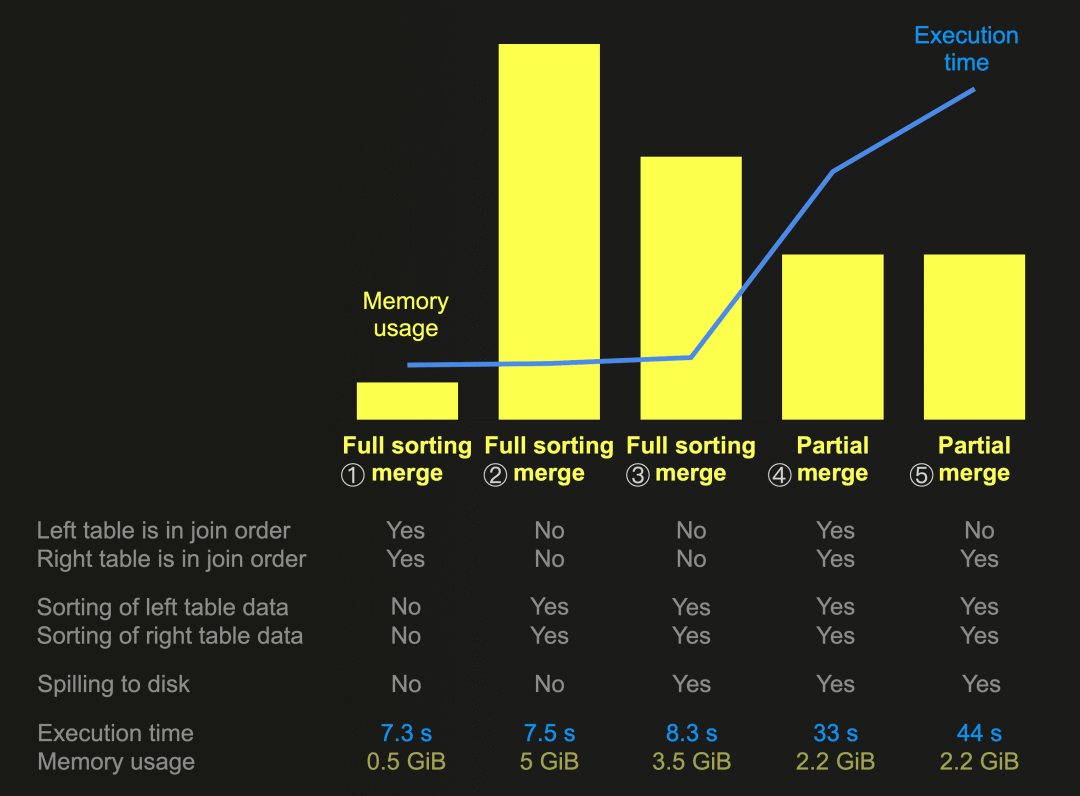
① 在这次运行中,完全排序合并联接跳过了排序和溢出阶段,因为两个联接表的物理行顺序与联接键排序顺序匹配。这导致了最快的执行时间和显著最低的内存使用。
② 对于两个联接表的内存排序,完全排序合并联接的内存消耗最高,而③ 使用外部排序而不是内存排序可以减少内存消耗,但牺牲了执行速度的降低。
④ 部分合并联接始终通过外部排序对右表的数据进行排序。我们可以看到,相对于使用外部排序的所有联接查询运行中,这种算法的内存使用最低。这正是这种算法以牺牲相对较低的执行速度为代价进行优化的目标。左表的数据也始终以块为单位在内存中进行排序。但是,⑤ 我们可以看到,如果左表的物理行顺序与联接键顺序不匹配,执行速度会变得最差。

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









