





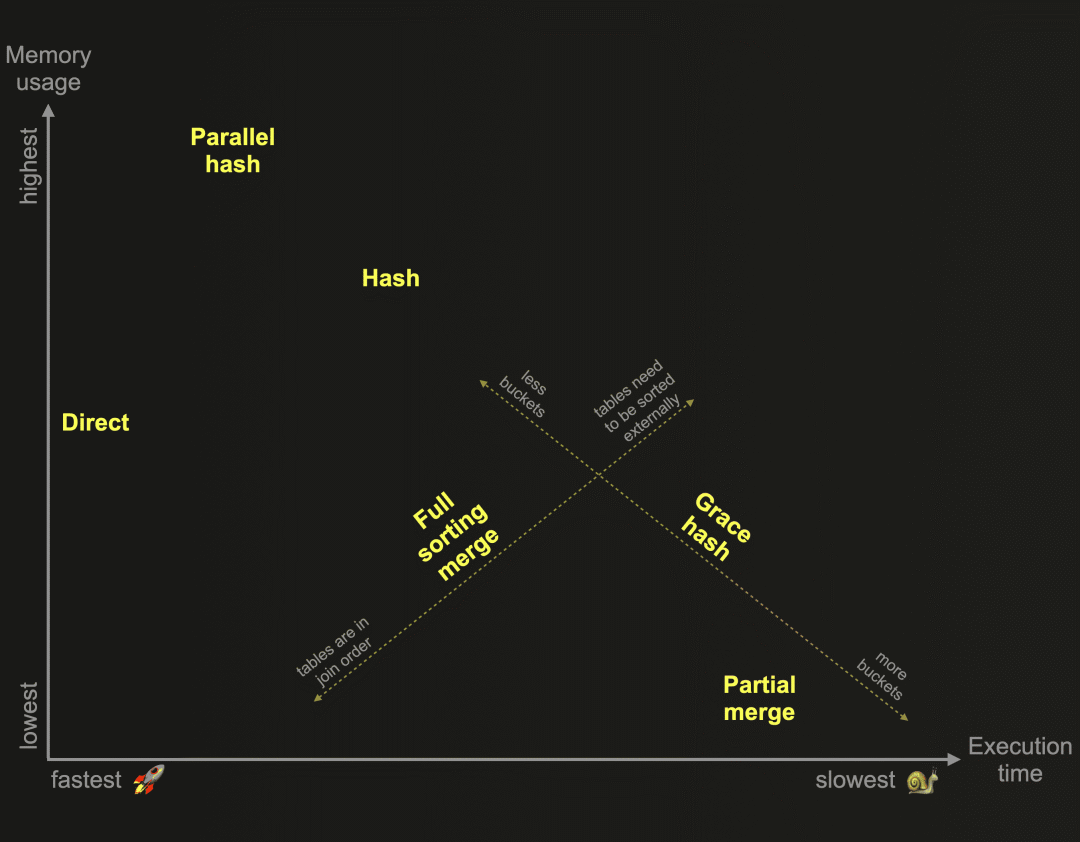
本文结束了我们对于ClickHouse开发的6种不同联接算法的探索。作为提醒:这些算法决定了联接查询的计划和执行方式。ClickHouse可以根据资源的可用性和使用情况,在运行时自适应地选择和动态更改要使用的联接算法。然而,ClickHouse也允许用户自行指定所需的联接算法。这张图表根据它们的相对内存消耗和执行时间,对这些算法进行了概览:
在我们的第二篇文章中,我们详细描述并比较了上述图表中基于内存哈希表的三种ClickHouse联接算法:
-
Hash join 哈希联接
-
Parallel hash join 并行哈希联接
-
Grace hash join 优雅哈希联接
作为提醒:哈希联接和并行哈希联接速度快,但受到内存限制。右侧表的联接数据需要适应内存。优雅哈希联接是一种非内存限制的版本,可以将数据临时溢出到磁盘,而无需对数据进行任何排序。这克服了其他将数据溢出到磁盘并要求对数据进行先前排序的联接算法的一些性能挑战。
在第三篇文章中,我们探讨并比较了上述图表中基于外部排序的两种算法:
-
Full sorting merge join 全排序合并联接
-
Partial merge join 部分合并联接
作为提醒:完全排序合并联接是一种非内存限制的算法,基于内存或外部排序,并且可以利用联接表的物理行顺序并跳过排序阶段。在这种情况下,联接性能可以与上述图表中的某些哈希联接算法竞争,同时通常需要明显较少的主内存。部分合并联接针对联接大型表时的最小化内存使用进行了优化,并且始终通过外部排序完全排序右表。左表也始终以块为单位在内存中排序。如果左表的物理行顺序与联接键排序顺序匹配,则联接匹配过程运行得更有效率。
我们将最佳内容留到最后,并将在本文中描述ClickHouse在上述图表中的最快联接算法,以完成我们对ClickHouse联接算法的探索:
-
Direct join 直接联接
直接联接算法可以在右侧表的底层存储支持低延迟键值请求时应用。特别是在右侧表很大的情况下,直接联接算法在执行时间上显著优于其他所有ClickHouse联接算法。
测试配置
我们使用第二篇文章中介绍的相同两个表格和相同的ClickHouse云服务实例。
对于所有示例查询运行,我们使用默认的 max_threads 设置。执行查询的节点具有30个CPU核心,因此 max_threads 的默认设置为30。为了保持流程图简洁易读,我们在ClickHouse查询流程中人为限制并行度的级别,设置 max_threads=2 。
直接联接
描述
直接联接算法可以在右侧表的底层存储支持低延迟键值请求时应用。ClickHouse提供了三种表引擎支持这一点:Join(基本上是一个预先计算的哈希表)、EmbeddedRocksDB和Dictionary。我们将在这里基于字典描述直接联接算法,但对于这三种引擎来说,机制是相同的。
字典是ClickHouse的一个重要特性,提供了对来自各种内部和外部源的数据的内存中的键值表示,经过优化以实现超低延迟的查找查询。这在各种场景下非常方便,例如在不降低摄入过程速度的情况下实时丰富摄入的数据,以及改善查询的性能,尤其是在JOIN操作中获得明显的好处。
下面我们对直接联接算法进行简要描述:
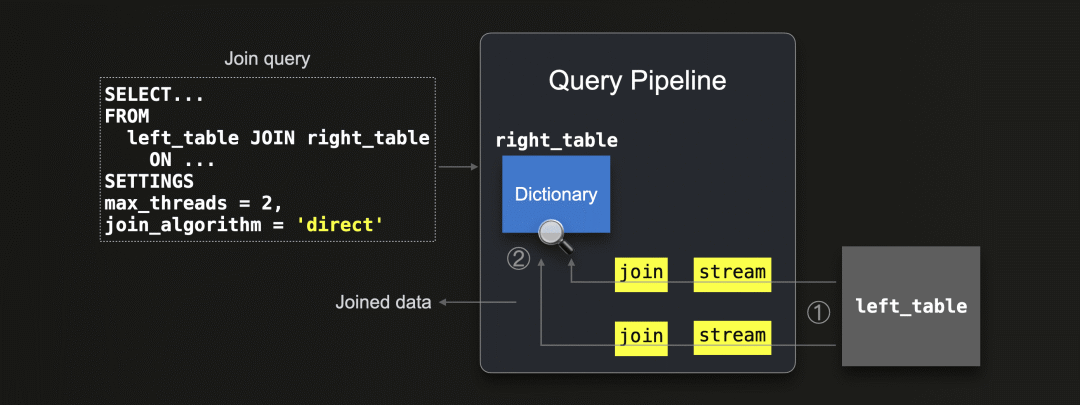
直接联接算法要求右表由字典支持,这样来自该表的待联接数据就已经以低延迟键值数据结构的形式存在于内存中。然后,①左表的所有数据通过2个流(因为 max_threads = 2 )并行地流式传输到查询引擎中,并且通过两个联接阶段并行地进行联接,通过对右表的底层字典进行查找来实现。
支持的联接类型
仅支持LEFT ANY联接类型。请注意,联接键需要与底层键值存储的键属性匹配。
示例
为了演示直接联接,我们首先需要创建一个字典。为此,我们需要选择一种布局,确定字典内容在内存中的存储方式。我们将使用平坦(flat)选项,并进行比较的还有散列(hashed)布局。这两种布局要求键属性的数据类型与UInt64类型兼容。平坦布局在所有布局选项中提供了最佳性能,并分配了一个内存数组,其中包含与键属性的最大值相等的条目数。例如,如果最大值为10万,则数组将有10万个条目的空间。这种数据布局允许以 0(1) 时间复杂度进行极快的键值查找,因为只需要进行简单的数组偏移查找。偏移量就是提供的键的值,数组中该偏移位置的条目包含相应的值。这非常适用于我们的演员和角色数据,其中在源表的键列( id 和 actor_id )中具有密集和单调递增的值,从0开始。因此,每个分配的数组条目都将被使用。散列布局将字典内容存储在哈希表中,适用性更广泛。例如,对于非从0开始的非密集键属性值,在内存中不会为其分配不必要的空间。但是,正如我们稍后将看到的,访问速度较慢,通常比平坦布局慢2-5倍。
我们创建一个具有平坦布局的字典,将角色表的内容完全加载到内存中,以进行低延迟的键值查找。我们将使用 actor_id 作为键属性。请注意,我们使用 max_array_size 设置指定初始和最大数组大小(默认值500,000太小)。我们还通过将 LIFETIME 设置为0来禁用字典的内容更新:
CREATE DICTIONARY imdb_large.roles_dict_flat
(
created_at DateTime,
actor_id UInt32,
movie_id UInt32,
role String
)
PRIMARY KEY actor_id
SOURCE(CLICKHOUSE(db 'imdb_large' table 'roles'))
LIFETIME(0)
LAYOUT(FLAT(INITIAL_ARRAY_SIZE 1_000_000 MAX_ARRAY_SIZE 1_000_000));接下来,我们创建一个类似的字典,但采用散列布局:
CREATE DICTIONARY imdb_large.roles_dict_hashed
(
created_at DateTime,
actor_id UInt32,
movie_id UInt32,
role String
)
PRIMARY KEY actor_id
SOURCE(CLICKHOUSE(db 'imdb_large' table 'roles'))
LIFETIME(0)
LAYOUT(hashed());请注意,在ClickHouse Cloud中,字典将自动在所有节点上创建。对于OSS版本,如果使用复制数据库(Replicated database),则可以实现此行为。其他配置将需要手动在所有节点上创建字典,或者通过使用ON CLUSTER子句来创建字典。
我们查询字典系统表以检查一些指标:
SELECT
name,
status,
formatReadableSize(bytes_allocated) AS memory_allocated,
formatReadableTimeDelta(loading_duration) AS loading_duration
FROM system.dictionaries
WHERE startsWith(name, 'roles_dict_')
ORDER BY name;
┌─name──────────────┬─status─┬─memory_allocated─┬─loading_duration─┐
│ roles_dict_flat │ LOADED │ 1.52 GiB │ 12 seconds │
│ roles_dict_hashed │ LOADED │ 128.00 MiB │ 6 seconds │
└───────────────────┴────────┴──────────────────┴──────────────────┘loading_duration 列显示了将源表内容加载到字典的内存布局中所花费的时间。 status 表示加载已完成。我们可以看到为字典分配了多少主内存空间。
使用上述字典DDL创建一个字典会自动创建一个由字典支持的具有字典表引擎的表。我们通过查询表系统表来验证这一点:
SELECT
name,
engine
FROM system.tables
WHERE startsWith(name, 'roles_dict_')
ORDER BY name;
┌─name──────────────┬─engine─────┐
│ roles_dict_flat │ Dictionary │
│ roles_dict_hashed │ Dictionary │
└───────────────────┴────────────┘在这样的表中,字典可以作为一级表实体进行操作,并且可以直接使用熟悉的SELECT子句读取数据。
与普通(MergeTree引擎系列)ClickHouse表不同,字典中的键属性是(自动)唯一的。例如,roles表中包含许多具有相同 actor_id 值的行,因为一般一个演员/女演员会有多个角色。当这些行以 actor_id 作为键属性加载到字典中时,具有相同键值的行会相互覆盖。实际上,字典中只包含特定 actor_id 的最后一行插入的数据。
我们可以通过从字典的 roles 源表和自动创建的字典表中选择计数来验证这一点:
SELECT formatReadableQuantity(count()) as count FROM roles;
┌─count──────────┐
│ 100.00 million │
└────────────────┘
SELECT formatReadableQuantity(count()) as count FROM roles_dict_flat;
┌─count────────┐
│ 1.00 million │
└──────────────┘100万正好是 actors 表中独立演员的数量。这意味着roles字典包含了每个演员/女演员的一个角色的数据:
SELECT formatReadableQuantity(count()) as count FROM actors;
┌─count────────┐
│ 1.00 million │
└──────────────┘现在我们使用字典将 actors 表中的行与 roles 表中的信息进行关联。请注意,我们使用dictGet函数来执行低延迟的键值查找。对于 actors 表中的每一行,我们在字典中进行查找,使用 id 列的值,并请求以元组形式返回 created_at 、 movie_id 和 role 值:
WITH T1 AS (
SELECT
id,
first_name,
last_name,
gender,
dictGet('roles_dict_flat', ('created_at', 'movie_id', 'role'), id) as t
FROM actors)
SELECT
id,
first_name,
last_name,
gender,
id AS actor_id,
t.1 AS created_at,
t.2 AS movie_id,
t.3 AS role
FROM T1
LIMIT 1
FORMAT Vertical;
Row 1:
──────
id: 393216
first_name: Wissia
last_name: Breitenreiter
gender: F
actor_id: 393216
created_at: 2023-05-12 13:03:09
movie_id: 373614
role: Gaston Binet
1 row in set. Elapsed: 0.019 sec. Processed 327.68 thousand rows, 12.74 MB (17.63 million rows/s., 685.25 MB/s.)请注意,如果字典中不包含特定演员 id 值的键条目,则将返回配置的默认值作为所请求的属性值。另外,正如上面提到的,字典根据 actor_id 列对加载的数据进行去重,实际上只返回找到的第一个匹配项。因此,上述查询的行为等效于LEFT ANY JOIN。
在ClickHouse中,有一种更简单和更紧凑的方式来表达上述查询。我们之前展示了创建具有特定名称的字典时,ClickHouse会自动通过字典表引擎创建一个同名的表,该表由字典支持。通过使用 direct 联接算法的联接查询,我们可以使用这个表来表达与上述查询相同的逻辑:
SELECT *
FROM actors AS a
JOIN roles_dict_flat AS r ON a.id = r.actor_id
LIMIT 1
SETTINGS join_algorithm='direct'
FORMAT Vertical;
Row 1:
──────
id: 393216
first_name: Wissia
last_name: Breitenreiter
gender: F
actor_id: 393216
created_at: 2023-05-12 13:03:09
movie_id: 373614
role: Gaston Binet
1 row in set. Elapsed: 0.023 sec. Processed 327.68 thousand rows, 12.74 MB (14.28 million rows/s., 555.30 MB/s.)在内部,ClickHouse使用对右侧表支持的字典进行高效的键值查找来实现联接。这类似于使用 dictGet 函数进行查找的上述查询。我们可以通过使用EXPLAIN PLAN子句审查联接查询的查询计划来验证这一点:
EXPLAIN PLAN
SELECT *
FROM actors AS a
JOIN roles_dict_flat AS r ON a.id = r.actor_id
SETTINGS join_algorithm='direct';
┌─explain───────────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ FilledJoin (JOIN) │
│ Expression ((Convert JOIN columns + Before JOIN)) │
│ ReadFromMergeTree (imdb_large.actors) │
└───────────────────────────────────────────────────────┘我们可以看到,ClickHouse使用了一个特殊的FilledJoin步骤,指示无需准备或加载右侧表,因为其内容已经以非常快速的键值查找数据结构的形式存在于内存中。这对于执行联接来说非常方便和理想。
为了比较,我们可以审查使用哈希算法的相同联接查询的查询计划:
EXPLAIN PLAN
SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
SETTINGS join_algorithm='hash';
┌─explain──────────────────────────────────────────────────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ Join (JOIN FillRightFirst) │
│ Expression (Before JOIN) │
│ ReadFromMergeTree (imdb_large.actors) │
│ Expression ((Joined actions + (Rename joined columns + (Projection + Before ORDER BY)))) │
│ ReadFromMergeTree (imdb_large.roles) │
└──────────────────────────────────────────────────────────────────────────────────────────────现在我们看到了 JOIN FillRightFirst 步骤,指示在执行哈希联接之前,将从右侧表加载数据到内存(哈希表)中。
我们将比较使用以下方式执行相同联接查询的执行时间:
-
哈希算法
-
并行哈希算法
-
使用散列布局的字典支持的直接算法
-
使用平坦布局的字典支持的直接算法
请注意,如上所述,使用字典支持的右侧表的直接联接实际上是LEFT ANY JOIN。为了进行公平比较,因此我们在使用哈希算法的查询运行中使用了这种联接类型。
我们运行哈希联接:
SELECT *
FROM actors AS a
LEFT ANY JOIN roles AS r ON a.id = r.actor_id
SETTINGS join_algorithm='hash'
FORMAT Null;
0 rows in set. Elapsed: 1.133 sec. Processed 101.00 million rows, 3.67 GB (89.13 million rows/s., 3.24 GB/s.)我们运行并行哈希联接:
SELECT *
FROM actors AS a
LEFT ANY JOIN roles AS r ON a.id = r.actor_id
SETTINGS join_algorithm='parallel_hash'
FORMAT Null;
0 rows in set. Elapsed: 0.690 sec. Processed 101.00 million rows, 3.67 GB (146.38 million rows/s., 5.31 GB/s.)我们运行直接联接时,右侧表的底层字典采用散列内存布局:
SELECT *
FROM actors AS a
JOIN roles_dict_hashed AS r ON a.id = r.actor_id
SETTINGS join_algorithm='direct'
FORMAT Null;
0 rows in set. Elapsed: 0.113 sec. Processed 1.00 million rows, 38.87 MB (8.87 million rows/s., 344.76 MB/s.)最后,我们运行直接联接,右侧表的底层字典采用平面内存布局:
SELECT *
FROM actors AS a
JOIN roles_dict_flat AS r ON a.id = r.actor_id
SETTINGS join_algorithm='direct'
FORMAT Null;
0 rows in set. Elapsed: 0.044 sec. Processed 1.00 million rows, 38.87 MB (22.97 million rows/s., 892.85 MB/s.)现在,让我们检查最近四次查询运行的运行时间统计:
SELECT
query,
query_duration_ms,
(query_duration_ms / 1000)::String || ' s' AS query_duration_s,
formatReadableSize(memory_usage) AS memory_usage,
formatReadableQuantity(read_rows) AS read_rows,
formatReadableSize(read_bytes) AS read_data
FROM clusterAllReplicas(default, system.query_log)
WHERE (type = 'QueryFinish') AND (hasAll(tables, ['imdb_large.actors', 'imdb_large.roles']) OR arrayExists(t -> startsWith(t, 'imdb_large.roles_dict_'), tables))
ORDER BY initial_query_start_time DESC
LIMIT 4
FORMAT Vertical;
Row 1:
──────
query: SELECT *
FROM actors AS a
JOIN roles_dict_flat AS r ON a.id = r.actor_id
SETTINGS join_algorithm='direct'
FORMAT Null;
query_duration_ms: 44
query_duration_s: 0.044 s
memory_usage: 83.66 MiB
read_rows: 1.00 million
read_data: 37.07 MiB
Row 2:
──────
query: SELECT *
FROM actors AS a
JOIN roles_dict_hashed AS r ON a.id = r.actor_id
SETTINGS join_algorithm='direct'
FORMAT Null;
query_duration_ms: 113
query_duration_s: 0.113 s
memory_usage: 102.90 MiB
read_rows: 1.00 million
read_data: 37.07 MiB
Row 3:
──────
query: SELECT *
FROM actors AS a
LEFT ANY JOIN roles AS r ON a.id = r.actor_id
SETTINGS join_algorithm='parallel_hash'
FORMAT Null;
query_duration_ms: 689
query_duration_s: 0.689 s
memory_usage: 4.78 GiB
read_rows: 101.00 million
read_data: 3.41 GiB
Row 4:
──────
query: SELECT *
FROM actors AS a
LEFT ANY JOIN roles AS r ON a.id = r.actor_id
SETTINGS join_algorithm='hash'
FORMAT Null;
query_duration_ms: 1084
query_duration_s: 1.084 s
memory_usage: 4.44 GiB
read_rows: 101.00 million
read_data: 3.41 GiB从第一行的直接联接运行结果来看,右侧表由平坦内存布局的字典支持,比第三行的并行哈希联接运行结果快大约15倍,比第四行的哈希联接运行结果快约25倍,比第二行的右侧表由散列内存布局的字典支持的直接联接运行结果快约2.5倍。这速度真是太快了!
主要原因是右侧表的数据已经存在于内存中。相反,哈希和并行哈希算法需要首先将数据加载到内存中。此外,正如前面提到的,具有平坦布局的字典的内存中数组允许以 0(1) 时间复杂度进行极快的键值查找,因为只需要进行简单的数组偏移查找。
请注意, query_log 系统表的 memory_usage 列不包括字典本身分配的内存。因此,为了进行公平的峰值内存消耗比较,我们需要将字典系统表的 bytes_allocated 列的相应值添加进来 - 请参考我们上面对该系统表的查询。我们将在本文的摘要部分进一步进行这样的比较。正如您将看到的,即使将字典的 bytes_allocated 添加到直接联接运行的 memory_usage 中,峰值内存消耗与哈希和并行哈希联接运行相比仍然显著较低。
查询流水线
在 max_threads 设置为 2 的情况下,让我们反观一下直接联接查询的实际查询流水线:
clickhouse client --host ekyyw56ard.us-west-2.aws.clickhouse.cloud --secure --port 9440 --password <PASSWORD> --database=imdb_large --query "
EXPLAIN pipeline graph=1, compact=0
SELECT *
FROM actors AS a
JOIN roles_dict_flat AS r ON a.id = r.actor_id
SETTINGS max_threads = 2, join_algorithm = 'direct';" | dot -Tpdf > pipeline.pdf我们使用与上述抽象图中相同的圈定数字对流程图进行了标注,稍微简化了主要阶段的名称,并添加了字典和左侧表,以使两个图表保持一致:
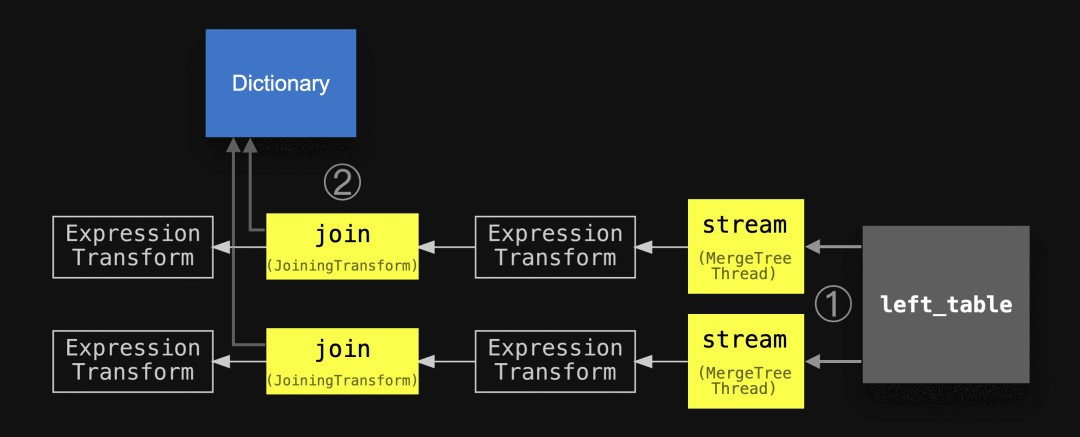
我们可以看到实际的查询流程与我们上面的抽象版本相匹配。
总结
这篇博文描述了ClickHouse最快的联接算法:直接联接。当右侧表的底层存储支持低延迟键值请求时,该算法是适用的。特别是在右侧表很大的情况下,直接联接在执行时间上优于所有其他ClickHouse联接算法。
下面的图表总结和比较了本文中联接查询运行的内存使用和执行时间。为此,我们始终运行相同的查询,连接相同的数据,右侧表为具有30个CPU核心的节点上的较大表(因此 max_threads 设置为30):

上面的图表非常清晰。使用直接联接算法是获得最快速度的方法。①当右侧表由具有平坦内存布局的字典支持时,该算法比哈希联接快约25倍,比并行哈希快约15倍,比②右侧表由具有散列内存布局的字典支持的直接联接快约2.5倍。无论字典布局类型如何,整体峰值内存消耗(包括字典的 bytes_allocated 添加到直接联接运行的 memory_usage 中)与哈希算法运行相比都较低。
这结束了我们对ClickHouse的6种联接算法的三部分深入探讨。
在本系列的下一篇文章中,我们将总结并直接比较所有6种ClickHouse联接算法。我们还将提供一个便捷的决策树和联接类型支持概述,您可以使用它来决定哪种联接算法最适合您的特定场景。

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求

















 1855
1855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









