








本文字数:8052;估计阅读时间:21 分钟
作者:博睿数据 李骅宸(太道)& 娄志强(冬青)
本文在公众号【ClickHouseInc】首发
本系列第一篇内容:
100%降本增效!Bonree ONE平台通过ClickHouse实现了可观测信号数据的统一!
一、背景
Bonree ONE是博睿数据发布的一体化智能可观测平台,融合了指标、调用链、日志、会话、事件等多种数据。早期时候,调用链、会话、日志的数据存到了Elasticsearch。我们历史架构如下图,大数据团队需要维护多种存储。比如,告警业务A说要做AI训练,就得自己加工一份时序数据到HDFS,指标中心业务B说加工指标,就自己加工一条链路到ClickHouse,DEM业务C想做会话分析,APM业务D又想做调用链分析,日志业务E还想做日志分析,那么业务C、D、E就分别加工各自数据到ES,这就导致完全各自业务各自加工存储。这样烟囱式的发展到一定程度后,数据不好管理,资源浪费严重,并且各业务之间数据很难做关联式的统计和分析(比如用户的网络请求和后端调用链关联的多端打通场景),产品迭代越来越重。即使在产品web页面看起来能展示到一起,但下面架构和数据已经到了盘根错节的程度,对于千亿级、万亿级甚至更多的数据非常难治理,产品在私有化大B客户项目交付时更成为不可控的空中楼阁。
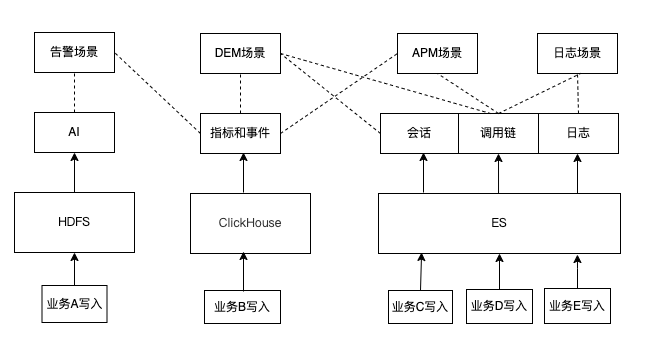
使用ES过程中我们也遇到了以下痛点:
-
数据割裂。由于可观测性的业务特性,数据融合是真正的能力,像历史烟囱式的异构存储给我们的数据融合本身就带来了阻碍。可观测性场景里有很多互相关联的分析场景(比如前后端数据融合打通业务和系统去做根因分析),这就导致要么多端数据可能不一致,要么做不到真正的关联分析或关联加工成本很高。
-
效率差。比如业务写入会话数据到ES的同时,相关联的快照数据写入对象存储系统,相对于快照数据的写入时间,ES数据写入响应时间需要等待至少亚秒级的延迟,导致产品上会有查询不到数据而出现天窗问题,影响体验。
-
分析效率低。产品有搜索+统计分析的结合场景,海量数据近30天的统计经常查不出来。
-
资源成本高。数据占用存储资源多,压缩效果不好,随着数据量的上涨,成本会越来越高。
-
维护成本高。IO资源开销大,尤其私有化混部场景,对部署在同一个机器上的其他组件,影响较大。我们经常发现很多B端用户混部时,因为ES的IO占用过高影响了其他组件的稳定性,尤其金融类大客户对稳定性要求极高,我们需要经常驻场排障。
由于ES存在诸多问题,使得我们迫切寻找一个新的架构和存储方案来进行升级,解决写入和查询的性能问题以及成本问题。
二、为什么选择ClickHouse
新的存储方案需要具备高写入吞吐、高读取效率、集群管理方便的特点。我们选中了ClickHouse是因为:
-
写入效率:ClickHouse写入可以达到100M/秒,同时在延迟性上,受攒批效率的影响,实现了亚秒级别的数据写入延迟,而且稳定性相对于ES来说更强。在ES里,随着数据量积累增加,索引的更新成本是在逐步增长的相对的,写入稳定性也在受影响。同时,ClickHouse的压缩效率明显比ES好。
-
读取效率:在会话场景里,业务查询数据的时间范围以及对应的统计分析都是不确定的,ClickHouse基于高频查询确认主键字段,基于常用高优查询指定索引等优化手段,保证查询效率稳定。而ES在应对非固定查询的场景下,会占用大量内存,同时由于索引块换入换出的问题,会引起IO较高的问题。
-
集群管理:我们自研了ClickHouse集群的管理平台,支持对ClickHouse服务的数据写入、读取、节点状态等的监控,以及常用运维操作,比如扩缩容、数据均衡等。在 ES 的集群管理上,没有方便的页面工具覆盖到扩缩容、数据迁移等运维操作。
-
易用性:ClickHouse基于sql查询,业务接入直接基于jdbc的方式或者http的方式就可以直接使用。在ES中,大段的Json格式的查询,有一定的学习门槛。
三、从ES迁移到ClickHouse
经过烟囱式架构重构改造,我们把ClickHouse集群横向作为可观测性所有信号数据的统一存储,用自研的ck-consumer组件统一在存储写入层做了封装,做了精细化的攒批优化和脏数据阻断,让所有数据均衡写入ClickHouse集群,用自研的 ck-manager组件管理ClickHouse集群的状态、资源隔离、DDL、高可用容错等能力,用自研的one-service组件做了统一数据服务,屏蔽了存储(尤其对于信创改造收益较大),用自研的平台管理界面丰富了ClickHouse的拓扑信息、全方位自监控和告警、SQL执行、分区管理、配置管理、任务管理、TTL过期管理策略、磁盘预估策略等运维工具能力。这样先从架构数据上做好融合,把复杂交给底座引擎,把简单留给业务,让业务高效迭代。
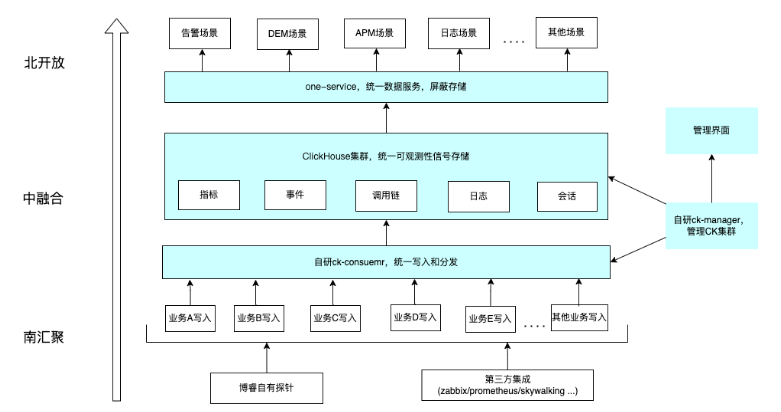
四、写入优化
1. 按表攒批
ClickHouse是擅长按批写入数据的,批次的数据越大,吞吐量越高。为应对多场景数据涉入的状况和减少业务端对数据存储感知的需求,我们通过消费节点来完成攒批逻辑,根据每个表的个性化定制策略,实现攒批效果的最大化,这既能满足业务效率的要求,又能实现ClickHouse数据摄入的最大吞吐量。在consumer增加每个业务独立的攒批逻辑,根据业务数据特性,按照数据大小和延迟时间等策略触发写入操作。
2. 动态限流
往往资源预估并非十分精准,但无论如何系统自身要有防挂手段来保证稳定性(尤其对金融类客户申请变更需要走复杂流程,来不及马上干预)。在有限存储资源的情况下,ClickHouse集群支持的摄入量是有限的,过大的数据写入主要有两个维度的原因,一个是写入的数据量过多,另一个是写入的峰值过高。前者会通过告警功能送达运维团队,通过扩容或数据降级或限流的操作来解决。后者在有限资源情况下通过蓄洪和限流来保证存储集群的稳定性。目前,在consumer节点,我们增加了窗口逻辑来满足限流操作策略介入的需要。比如依据总parts数和服务内存情况,通过指定的策略算法,动态计算出每个业务数据摄入的上限,写入操作会加入窗口逻辑,限制数据摄入的速度,防止存储超限。
3. too many parts问题
当写入超过ClickHouse服务承受的上限的时候,会出现too many parts异常。这个异常的本意是防止ClickHouse服务在超负载的情况下挂掉,同时给维护人一个信号。因此,出现too many parts异常的时候,维护人就要关注当前服务是不是遇到超高峰数据的写入了。此时可以关注的指标如下:
-
当前服务占用的cpu是不是超预期了。关注merge任务是不是占满队列,通常写入超预期的情况下,parts数量也是暴涨,ClickHouse为了保证查询效率,merge任务就会暴涨,而merge任务是消耗硬件资源的,如果资源不够,merge任务运行缓慢,就会降低parts数量的减少效率,从而导致parts数量缓慢增加,当增加到parts_to_throw_insert的数值时,就会产生too many parts的异常。
-
关注写入数据攒批的状态,如果写入频繁,单批次数量较小,会导致parts数量增长很快,很容易触发到merge任务运行的最大值,从而引发too many parts异常。
经过团队合理优化攒批大小后,too many parts的问题得到有效解决,并且我们对parts单独增加了界面化监控。
五、读取优化
1. 查询加速
-
orderBy和primaryKey的高效使用:orderBy相关字段是表数据的排序设置,它对高频查询的效率有重要。一般orderBy的设置要尽量覆盖当前表业务的高频查询,从低基数到高基数进行排序设置。primaryKey默认与orderBy一致,如果filter条件没有覆盖所有的orderBy字段,则可以提取部分字段作为primaryKey,但是primaryKey必须是orderBy字段的前缀。
-
索引使用:高频查询要充分利用主键索引,主键索引满足不了的高频查询,借助索引来加速。针对等值过滤使用BF索引,针对范围查询使用minmax索引,针对全文模糊检索使用tokenbf索引。
-
物化视图:针对固定优化查询场景,使用物化视图,大大提高查询效率。但物化视图不保证和原表的数据一致性,需要业务自己维护或业务可容忍。物化视图要按需合理使用,否则如果创建过多的物化视图,也要同时考虑parts过多的风险。
-
projection:针对部分预聚合场景,使用projection的效率更高,查询有更友好的自动路由,且业务不用考虑和原表数据一致性的问题,减少业务侵入,正所谓“数据同源、同生共死”。有些首页统计或者个性化查询加速场景,经常用到projection来保障,业务也不用修改查询,这点非常受益。但projection也有一些限制,比如对高基维度不太友好。
-
大数据量查询过滤:例如调用链有百亿到千亿级数据。查询指定调用链,调用链详情在存储的时候会出现一天出现多条,同时出现跨分区的情况,但需要在海量数据中快速查找到指定的数据。即使加了索引之后,在扫描调用链超大量数据时,过滤之后还是会命中很多的granularity。这里可以按照调用链ID排序,分区内通过一级索引快速命中指定的调用链数据。同时为了查询出跨分区的调用链详情数据时,调大时间范围可以将调用链完整的数据全部查询出来。这样在数十亿条数据中查询一条完整的调用链数据耗时控制在毫秒级别。再比如按巨大量级调用链的耗时排序展示的场景,可以通过分位特征计算,缩放数据范围,也可以达到高速查询的效果。
2. 压缩和编码
ClickHouse提供了多种编码以及多种编解码器,极大提高数据的压缩效率,节省IO、存储等资源。ClickHouse支持的压缩算法举例:
-
NONE : No Compression.
-
LZ4 : Applies LZ4 fast compression.
-
LZ4HC[(level)] : LZ4 HC (high compression) algorithm with configurable level.
-
ZSTD[(level)] : ZSTD compression algorithm with configurable level.
我们场景经过测试对比,大部分ZSTD的压缩效率是LZ4的5~6倍。若想要更高的压缩效率,数据的存储编码是一种更好的优化手段。ClickHouse提供的特殊编码算法举例:
-
Delta : This approach stores the difference between 2 neighbor values. It can be combined with LZ4 and ZSTD.
-
DoubleDelta : This approach stores the difference between 2 neighbor delta values (delta of deltas). Suitable for time series data.
-
Gorilla : Calculates XOR between current and previous value. Suitable for slowly changing floating numbers.
-
T64 : It crops unused high bits of values in integer data types(include Enum, Date, DateTime) and puts them into a 64×64 bit matrix.
-
FPC : Used in floating point values. XOR between the actual value and the predicted value.
针对以上编码算法的特性,类似时间等递增字段我们选择基于DoubleDelta编码的ZSTD(1)压缩算法,String类型使用ZSTD(1)的压缩算法。
3. 字段精细化
ClickHouse提供了非常精细的数据字段进行压缩,比如整数就支持int8、int16、int32、int64,ClickHouse之所以这么细化数据类型,是为了高效的存储和计算,所以在业务使用端,也要做到精确化管理。
-
低基数的String使用 LowCardinality,会将string类型的字段使用类似于码表的手段将转换成数值类型字段进行存储,进而提高压缩率。
-
能用更少位数的数据存储,就选择最少位数的数据存储,比如优先使用int8,而不是默认使用int64。
-
半结构化数据优先使用Map结构,其次是JSON结构。
4. 天窗问题
调用链改造前使用ES存储统计数据,使用公司自研的BRFS小文件系统存储调用链详情数据,无法做到数据写入的原子性,经常会导致列表数据和详情数据不一致的天窗问题。之前是在业务层自己做处理,但成本较高且方案不通用。为了解决此问题,我们使用Null引擎将详情数据和统计数据一起入CK库。再通过物化视图将数据进行分拆到不同的表中,这样就保障了多页面之间数据一致性。
六、参数调优
ClickHouse开放了很多参数,参数调优是个细活。拿几个举例吧:
-
max_bytes_before_external_group_by:通过维度聚合查询时,当内存消耗超过这个阈值,GROUP BY会把多余的临时数据输出到文件系统并在磁盘进行处理计算,通常会建议配置成当前服务内存的80%。
-
max_bytes_before_external_sort:涉及数据排序时,当内存消耗超过这个阈值,ORDER BY 会把多余的临时数据输出到文件系统并在磁盘进行排序计算,通常会建议配置成当前服务内存的80%。
-
max_memory_usage:单条查询可以使用的最大内存,通常对不同的硬件配置以及不同的业务诉求配置不同的内存大小,我们场景一般会配置成当前服务内存的80%。
-
max_execution_time:单条查询可以执行的最长时间。一般跟业务相关,是业务可容忍的最大查询时间。
-
max_threads:用于控制一个用户的查询线程数,可以在合理范围内提高查询并行度。
-
background_pool_size:表引擎操作后台的线程数。太大会影响cpu资源,太小会影响parts数量,从而可能触发parts_to_throw_insert的异常。
-
parts_to_throw_insert:表分区之中活跃part数目超过多少,会抛出异常。针对不同的业务量,这个数字应该是不同的,用来保证相应的资源匹配相应的写入量级。
-
ttl_only_drop_parts:ClickHouse在数据过期的时候可以使用merge进行删除数据,做到了数据即时删除,但是也引起了一些风险。在删除数据时会消耗大量资源删除这些数据,而且数据量越大,对于系统整体的资源消耗越明显。如果希望这些资源用在入库和查询上,而不是浪费在释放一些磁盘的工作上,可以通过调整参数ttl_only_drop_parts=1,来设置过期的时候按照分区删除,并设置合理的分区,在牺牲很少一部分磁盘的情况下将mergeTTL这些资源节省出来提供给查询和入库,从而减少merge频率,降低负载。
七、多租户
ClickHouse为了保障多业务稳定查询,支持了多租户,减少业务之间的影响。我们基于ClickHouse的多租户能力,给予每条产品线单独的租户,实现租户资源个性化配置,满足不同业务不同优先级的诉求。
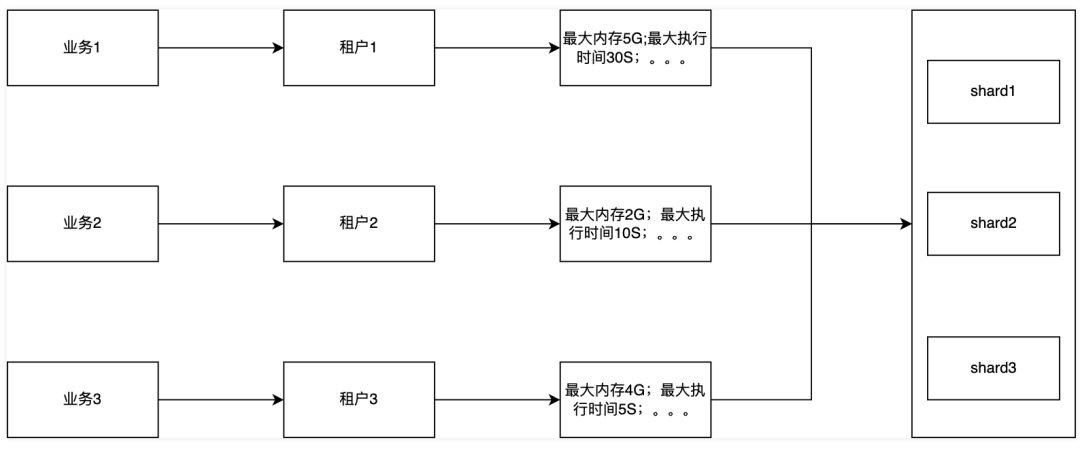
系统是根据各个租户的业务重要程度与场景响应需求来制定对应的租户资源显示的。目前ClickHouse支持了多租户资源限制,但是对于ClickHouse内部的资源还没有绝对隔离,在这一点上,我们是通过完整的监控告警链路来跟进,减少资源冲突带来的不稳定性,支持租户资源的快速释放,从而快速解决某些应急场景。
八、高可用保障
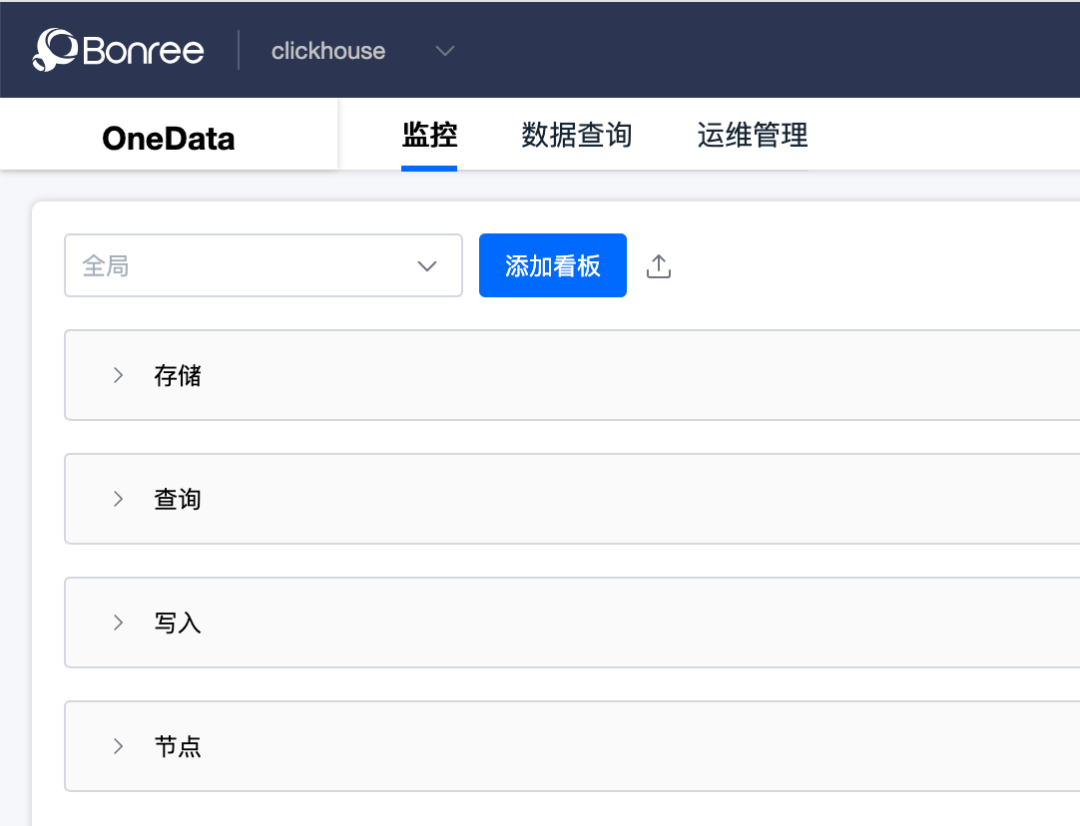
1. 监控
我们自研了界面工具,方便监控和运维:
-
首要跟踪的监控是写入和读取两个方向,比如每分钟写入量,写入耗时、查询QPS等,针对特定敏感业务可以个性化跟踪。
-
针对节点本身的状态信息进行监控,比如服务负载、merge任务数、parts数量等,这些指标可以及时发现服务的稳定性风险。
-
针对集群的均衡性进行监控,比如parts数据同步的延迟时间、各个节点的查询均衡性、各个节点的写入均衡性等,避免集群倾斜。
2. 容错
-
写入节点单节点异常,不影响整体服务写入。
-
ClickHouse单节点异常,不影响整体集群的写入也不影响读取。
-
还有其他数据问题、服务问题等容错,这里先不开展了。
3. failover
数据的摄入和读取需要高可用机制来满足需求,比如写入端某个consumer节点异常,或者某个ClickHouse节点异常等情况,我们如何保证集群的稳定性。
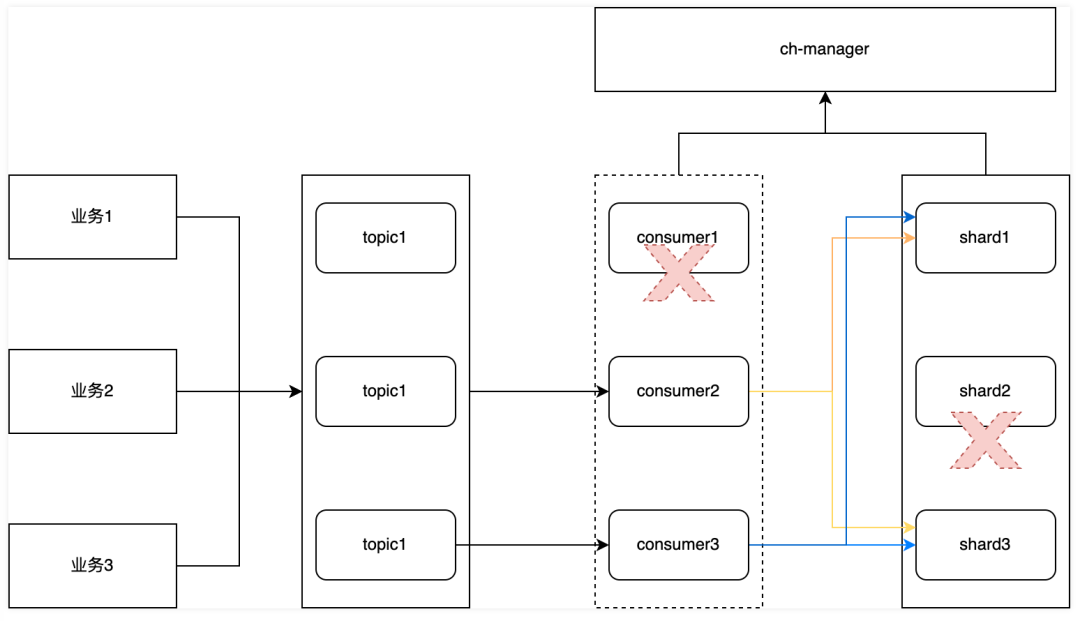
当consumer节点或者ClickHouse节点遇到异常时,manager节点能够感知到节点异常进行流量调度,使异常节点不影响数据正常摄入和查询,同时调整流量写入策略,保证consumer节点写入的稳定性,避免发生级联雪崩状况。
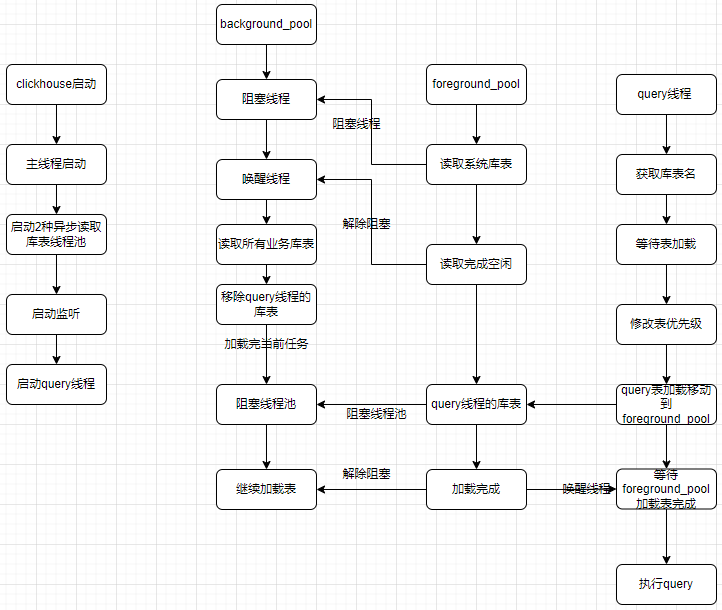
4. 重启慢
当集群容纳的数据量比较多的时候,ClickHouse的重启耗时会比较长,通常会达到几十分钟到小时级别不等。重启服务时间过长,对于整个服务的高可用会挑战很大,写入端的稳定性、容错性以及实时性,都会受到挑战。clickhouse23.11版本具备懒加载功能,clickhouse主线程启动后,库表分级异步加载模式去保证服务启动加速,期间读写请求优先级大于加载中库表优先级。
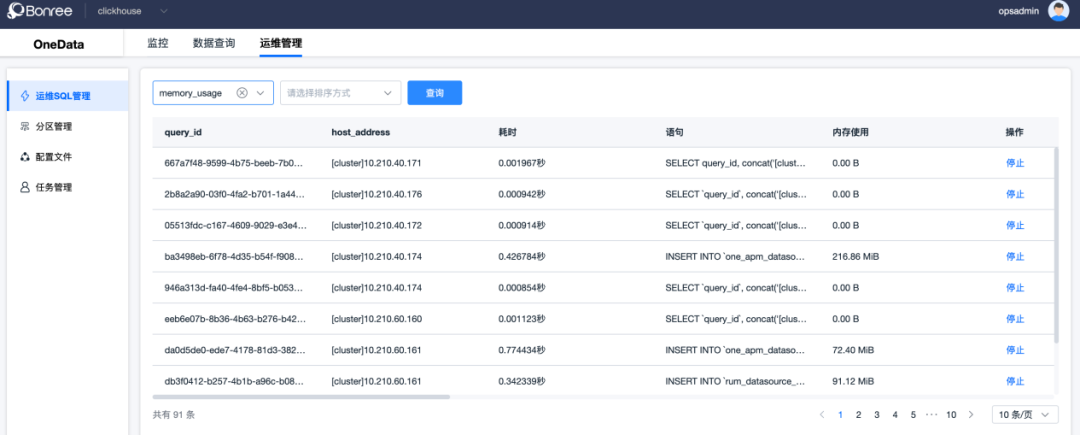
5. 自运维工具
我们基于manager组件研发了ClickHouse集群的运维工具,目前可以做SQL任务管理、配置管理、分区管理、数据迁移等。方便在私有云场景对故障能有干预能力。
九、效果
23年我们持续做架构精简,并围绕ClickHouse底座也做了大量的研究和落地工作:
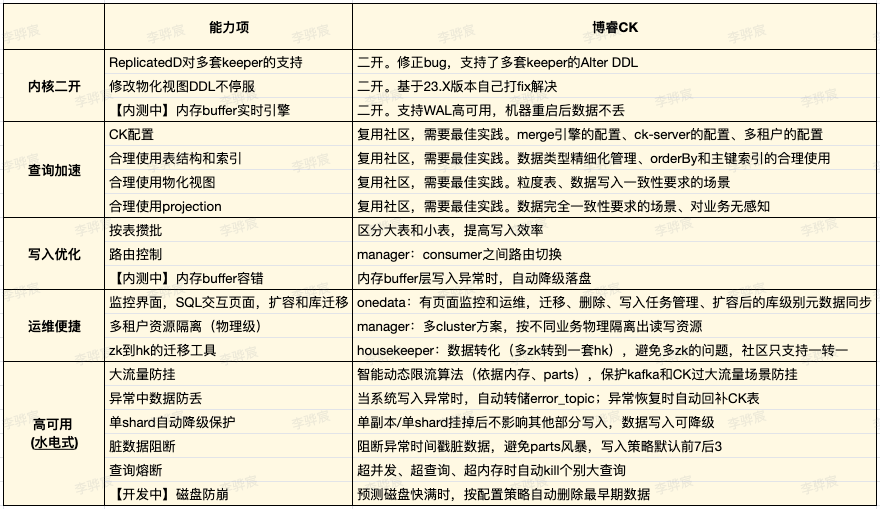
后来将调用链/日志/会话的几个ES集群全部迁移到ClickHouse之后:
-
性能方面:写入效率根据不同业务提高了3-5倍,SQL查询P99耗时从4s+降到356ms,平均耗时降到62ms。稳定性更强,团队内部会定期演练一些故障场景,能够应对超预期的流量和更多容错场景。
-
资源方面:我们自建云集群下线了24台ES机器(16C32G3T),同时扩容了10台同等配置的ClickHouse,节省了58%的机器成本。如果从单资源类型成本考虑,更加节省。相比ES,ClickHouse在内存和磁盘方面优势更加明显。以下仅是在我们自建云集群的对比结果(千亿级数据量),私有化客户量级会大更多。

十、最后
未来,我们会更加专注ClickHouse集群的更多优化,主要聚焦在以下方向:
-
buffer实时引擎。打造纯实时ClickHouse底座,继续瘦身kafka链路和consumer组件,在可观测性核心场景做到真正的写入即可见。二开支持bufferr层的WAL高可用。
-
merge的效率提升。merge资源有时会和写入、查询资源互撞,影响系统稳定性,如何做到更佳的平衡和控制,需要再进一步摸索。
-
存算分离。目前ClickHouse存算分离能力没有开源,需要考虑实际扩容单一类型资源的成本问题。
以上三个方向的优化与完善都能够进一步提升ClickHouse集群的性能、时效性、稳定性,帮助我们应对更多的业务场景,让业务发展稳中提效。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求

















 2027
2027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









