





本文字数:10377;估计阅读时间:26 分钟
作者: Tom Schreiber
本文在公众号【ClickHouseInc】首发

在实际业务场景中,如仪表板、告警监控或交互式分析,查询往往会反复使用相同的过滤条件(WHERE 条件),无论是针对静态数据,还是不断增长的数据,比如可观测性场景中的日志查询。尽管 ClickHouse 速度很快,但这些重复扫描仍然可能带来额外的计算开销,尤其是在过滤条件具有较强的筛选能力,但又无法充分利用主索引时。
为了解决这个问题,ClickHouse 25.3 引入了 查询条件缓存(query condition cache)——一种轻量级且高效利用内存的机制,用于记录哪些数据范围符合(或不符合)特定的查询条件。该缓存以数据粒度(granule)为单位运行,使 ClickHouse 在重复执行查询时能够跳过大量无关数据,即使查询结构发生变化,也能显著提升性能。
为了庆祝我们全新 JSON 类型的 GA(正式发布),我们将通过一个真实的数据集演示查询条件缓存的工作方式:一个从热门社交媒体平台 Bluesky 采集的 JSON 事件流。同时,我们还会深入解析 ClickHouse 的数据处理流程,以及查询条件缓存在其中的作用。提前透露一下,它速度快,占用空间小,而且即便是用于查找帖子中的椒盐卷饼表情符号这样的小众需求,依然表现卓越。
让我们深入了解一下吧!
初始化数据:导入 1 亿条 JSON 事件
我们首先在一台 32 核 CPU 的测试服务器上创建一个简化的表:
CREATE TABLE bluesky
(
data JSON(
kind LowCardinality(String),
time_us UInt64)
)
ORDER BY (
data.kind,
fromUnixTimestamp64Micro(data.time_us))
SETTINGS index_granularity_bytes = 0;注意:设置 index_granularity_bytes = 0 会禁用自适应数据粒度阈值。这种配置 不适用于生产环境,本次实验仅使用该设置,以确保粒度大小固定,便于观察效果。
接下来,我们从 100 个存储在 S3 上的文件中导入 1 亿条 Bluesky 事件到表中:
INSERT INTO bluesky
SELECT *
FROM s3('https://clickhouse-public-datasets.s3.amazonaws.com/bluesky/file_{0001..0100}.json.gz', 'JSONAsObject')
SETTINGS
input_format_allow_errors_num = 100,
input_format_allow_errors_ratio = 1,
min_insert_block_size_bytes = 0,
min_insert_block_size_rows = 20_000_000;注意:
-
input_format_allow_errors_* 选项可防止 ClickHouse 因少量 JSON 解析错误而终止执行。
-
min_insert_block_size_* 选项可加快数据导入速度并减少表数据合并的开销,但会占用更多内存。在低内存系统上,建议降低单次导入的行数阈值。
在正式介绍查询条件缓存之前,我们先简单了解一下 ClickHouse 的数据组织方式。
ClickHouse 的数据组织方式
目前,这张表包含 5 个数据分片,共计 1 亿行数据,未压缩数据大小为 36 GiB。
SELECT
count() AS parts,
formatReadableQuantity(sum(rows)) AS rows,
formatReadableSize(sum(data_uncompressed_bytes)) AS data_size
FROM system.parts
WHERE active AND (database = 'default') AND (`table` = 'bluesky');┌─parts─┬─rows───────────┬─data_size─┐
│ 5 │ 100.00 million │ 35.87 GiB │
└───────┴────────────────┴───────────┘在数据处理过程中,这 1 亿行数据会被划分为 粒度(granule),这是 ClickHouse 处理数据的最小单位。我们可以检查这 5 个数据分片 各自包含多少个粒度:
SELECT
part_name,
max(mark_number) AS granules
FROM mergeTreeIndex('default', 'bluesky')
GROUP BY part_name;┌─part_name───┬─granules─┐
│ all_9_9_0 │ 1227 │
│ all_10_10_0 │ 1194 │
│ all_8_8_0 │ 1223 │
│ all_1_6_1 │ 7339 │
│ all_7_7_0 │ 1221 │
└─────────────┴──────────┘注意:数据分片的命名方式具有特定含义,相关文档中有详细说明【https://github.com/ClickHouse/ClickHouse/blob/f90551824bb90ade2d8a1d8edd7b0a3c0a459617/src/Storages/MergeTree/MergeTreeData.h#L130】,供有兴趣的读者进一步探索。
默认情况下,一个粒度包含 8192 行数据。我们可以验证这张表是否符合该默认设置:
SELECT avg(rows_in_granule)
FROM mergeTreeIndex('default', 'bluesky');┌─avg(rows_in_granule)─┐
│ 8192 │
└──────────────────────┘了解了 ClickHouse 的数据组织方式后,我们可以通过一个示例来看看查询条件缓存如何提升查询性能。
无法有效利用主索引的查询
身在西班牙的我,时常想念家乡的 椒盐卷饼 🥨,于是,我开始关注社交媒体上提到它的帖子。在我们的数据集中,这类帖子记录是这样的:

下面的查询用于统计所有包含 椒盐卷饼表情符号 的帖子数量:
SELECT count()
FROM bluesky
WHERE
data.kind = 'commit'
AND data.commit.operation = 'create'
AND data.commit.collection = 'app.bsky.feed.post'
AND data.commit.record.text LIKE '%🥨%';┌─count()─┐
│ 69 │
└─────────┘
1 row in set. Elapsed: 0.529 sec. Processed 99.46 million rows, 7.96 GB (187.85 million rows/s., 15.03 GB/s.)
Peak memory usage: 240.27 MiB.请注意,这个查询 几乎无法受益于主索引优化,因为主索引是基于 kind 和 data.time_us 这两个 JSON 路径构建的,最终不得不扫描几乎整张表。
初步分析跟踪日志
我们让 ClickHouse 服务器返回查询执行期间的所有 跟踪级别(trace-level) 日志:
SELECT count()
FROM bluesky
WHERE
data.kind = 'commit'
AND data.commit.operation = 'create'
AND data.commit.collection = 'app.bsky.feed.post'
AND data.commit.record.text LIKE '%🥨%'
SETTINGS send_logs_level='trace';① <Trace> ...: Filtering marks by primary keys
① <Debug> ...: Selected ... 12141/12211 marks by primary key,
② <Debug> ...: 12141 marks to read from 10 ranges
③ <Trace> ...: Spreading mark ranges among streams
③ <Debug> ...: Reading approx. 99459072 rows with 32 streams从日志中可以看到:
-
① 主索引几乎没有过滤粒度(在跟踪日志中可见相关标记)。
-
② ClickHouse 需要扫描 12141 个粒度,这些粒度跨越 10 个数据范围,分布在 5 个数据分片 中。
-
③ 在 32 核 CPU 上,ClickHouse 在 32 个并行处理流 中分配并处理这 10 个数据范围。
启用查询条件缓存后重新运行查询
注意:查询条件缓存 默认尚未启用。我们仍在优化其稳定性,特别是在 ReplacingMergeTree 和 AggregatingMergeTree 的 FINAL 查询 这类边缘场景下,确保其行为可靠后才会默认开启。
接下来,我们在启用查询条件缓存的情况下运行相同的查询:
SELECT count()
FROM bluesky
WHERE
data.kind = 'commit'
AND data.commit.operation = 'create'
AND data.commit.collection = 'app.bsky.feed.post'
AND data.commit.record.text LIKE '%🥨%'
SETTINGS use_query_condition_cache = true;┌─count()─┐
│ 69 │
└─────────┘
1 row in set. Elapsed: 0.481 sec. Processed 99.43 million rows, 7.96 GB (206.78 million rows/s., 16.54 GB/s.)
Peak memory usage: 258.10 MiB.查询方式没有变化,依然几乎执行了一次 完整的表扫描,运行时间和内存占用也没有明显变化。然而,与之前不同的是,ClickHouse 现在会将扫描过的粒度信息存入查询条件缓存。下图展示了这一过程:
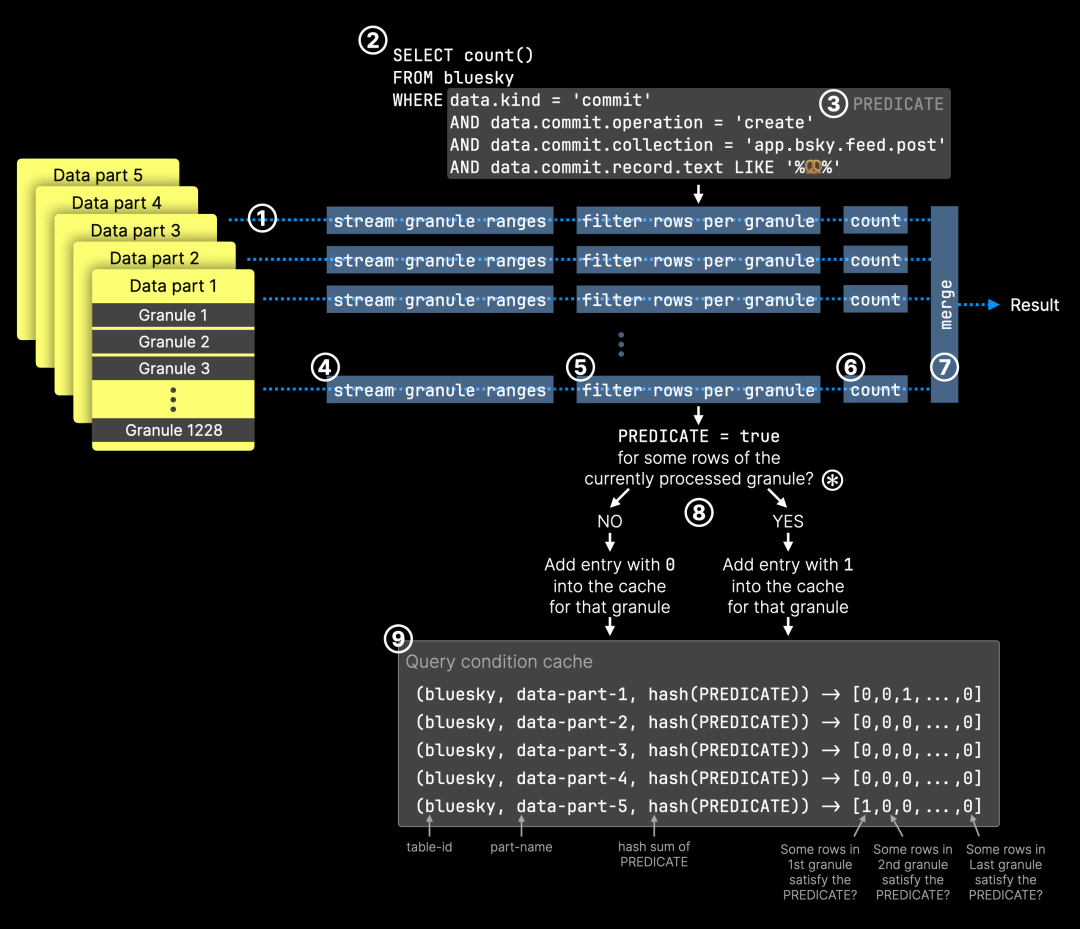
在查询执行过程中,选中的粒度按以下步骤处理:① 由 32 个并行处理流(图中的蓝色虚线)传输到查询引擎,② 执行查询以统计 Bluesky 事件,③ 使用谓词过滤包含椒盐卷饼表情符号的帖子。每个处理流的具体流程如下:④ 分配到特定的粒度范围,⑤ 对该粒度内的所有行应用查询谓词进行筛选,⑥ 统计匹配的行数,⑦ 所有部分结果合并为最终查询结果。
在 步骤 ⑤ 中,每处理一个粒度,ClickHouse 都会向查询条件缓存写入一条记录,记录格式如下:⑧ 缓存键 由 表 ID、粒度所属数据分片的名称 和 查询谓词的哈希值 组成,⑨ 该键映射到一个数组,数组的每个位置对应数据分片中的某个粒度,值的含义如下:(0)该粒度内 没有 符合查询条件的行。(1)该粒度内 至少 有一行符合查询条件。对于 筛选力度较强的查询(即只允许少量行通过的过滤器),这个数组中的大部分值通常为 0。
⊛ 需要注意的是,缓存的读写方式如果处理不当,可能会影响查询性能。为了避免查询条件缓存成为瓶颈,ClickHouse 采用 批量处理方式,一次性写入多个粒度的匹配结果,以减少缓存开销。
查看查询条件缓存
我们可以在 query_condition_cache 系统表 中查看缓存数据:
SELECT table_uuid, part_name, key_hash, matching_marks
FROM system.query_condition_cache LIMIT 1 FORMAT Vertical;table_uuid: 6f0f1c9d-3e98-4982-8874-27a18e8b0c2b
part_name: all_9_9_0
key_hash: 10479296885953282043
matching_marks: [1,1,1,0,0,0, ...]对比使用和不使用缓存的查询情况
现在,查询条件缓存已存储 第一个示例查询的结果,我们可以 再次运行该查询,并启用查询条件缓存:
SELECT count()
FROM bluesky
WHERE
data.kind = 'commit'
AND data.commit.operation = 'create'
AND data.commit.collection = 'app.bsky.feed.post'
AND data.commit.record.text LIKE '%🥨%'
SETTINGS use_query_condition_cache = true;┌─count()─┐
│ 69 │
└─────────┘
1 row in set. Elapsed: 0.037 sec. Processed 2.16 million rows, 173.82 MB (59.21 million rows/s., 4.76 GB/s.)
Peak memory usage: 163.38 MiB.这一次,查询运行 快了很多。ClickHouse 只需扫描 约 200 万行,相比之前的 1 亿行,大幅减少了扫描数据量。由于 查询条件缓存 的作用,ClickHouse 能够跳过所有不包含匹配行的粒度,从而显著提升查询效率。
在跟踪日志中验证缓存命中
我们可以在 跟踪日志(trace logging) 中观察缓存命中情况:
SELECT count()
FROM bluesky
WHERE
data.kind = 'commit'
AND data.commit.operation = 'create'
AND data.commit.collection = 'app.bsky.feed.post'
AND data.commit.record.text LIKE '%🥨%'
SETTINGS use_query_condition_cache = true, send_logs_level='trace';① <Trace> ...: Filtering marks by primary keys
...
② <Debug> QueryConditionCache: Read entry for table_uuid:
6f0f1c9d-3e98-4982-8874-27a18e8b0c2b, part: all_1_6_1,
condition_hash: 10479296885953282043, ranges: [0,0,...]
...
② <Debug> ...: Query condition cache has dropped 11970/12138 granules for WHERE condition and(equals(data.kind, 'commit'_String), equals(data.commit.operation, 'create'_String), equals(data.commit.collection, 'app.bsky.feed.post'_String), like(data.commit.record.text, '%🥨%'_String)).
...
③ <Debug> ...: 168 marks to read from 73 ranges
④ <Trace> ...: Spreading mark ranges among streams
④ <Debug> ...: Reading approx. 1376256 rows with 18 streams① 主索引 先裁剪部分粒度。② ClickHouse 检查查询条件缓存,发现匹配的缓存条目,并跳过大部分粒度。之前需要扫描 约 12000 个粒度(分布在 10 个大数据范围 内),现在 ③ 只需读取 168 个粒度,这些粒度分布在 73 个较小的数据范围 内。由于需要处理的数据量大幅减少,仅剩 约 130 万行,ClickHouse 在 32 核 CPU 机器上,④ 仅使用了 18 个并行处理流,而非 32 个,每个流都需要足够的任务量,才能被合理分配。
下图展示了基于 查询条件缓存 的 粒度裁剪 过程:
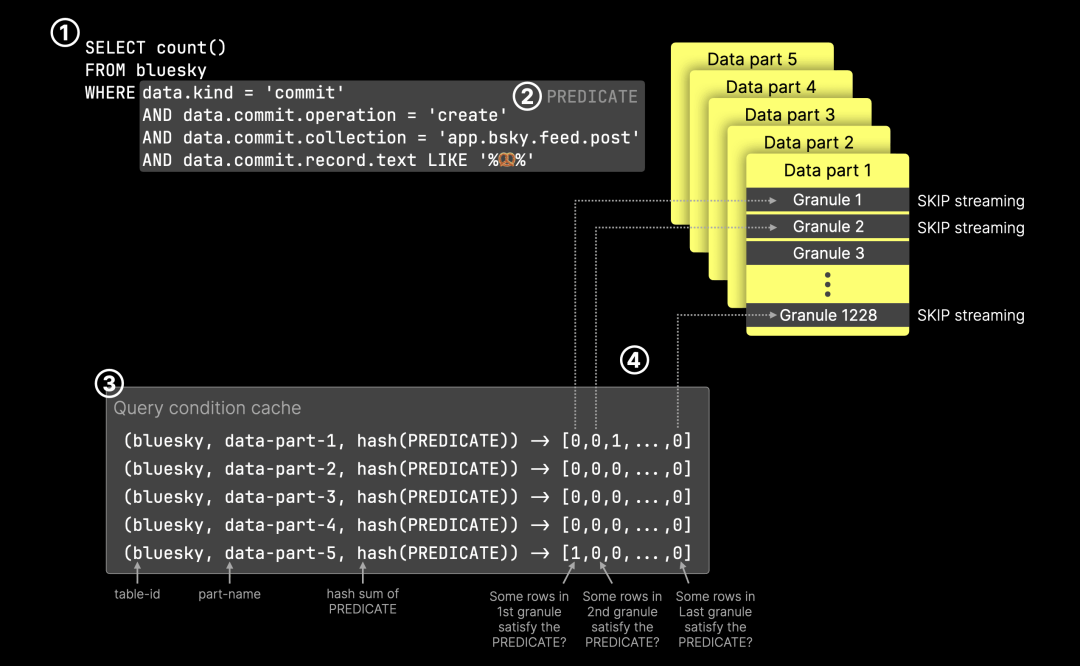
对于 ① 查询,在给定的 表、其 数据分片 以及 ② 查询谓词 的情况下,ClickHouse 在 ③ 查询条件缓存 中找到了匹配条目。④ 所有标记为 0 的粒度都会被跳过,避免不必要的计算。
查询条件缓存的内存效率
查询条件缓存在内存使用上非常高效。它为每个过滤条件和每个 granule 只存储 1 个比特位。缓存大小可以通过参数 query_condition_cache_size 进行配置,默认值为 100 MB。在默认的 100 MB 大小下,缓存最多可以保存大约 8.39 亿个 granule 条目(100 * 1024 * 1024 * 8),每个 granule 覆盖 8,192 行。也就是说,在仅使用一列进行过滤的情况下,最多可以缓存约 6.8 万亿行的数据。如果过滤条件中使用了多个列,这个总行数会相应除以列数。相比之下,查询结果缓存会将整个查询与其完整的结果集进行映射,因此每条缓存记录通常会占用更多的内存。
复用查询谓词:热门椒盐卷饼帖子的语言分布
查询条件缓存 的最大优势在于,它针对的是查询谓词,而非完整查询。这意味着 所有包含相同查询谓词的查询 都能 自动受益,无论查询的其他部分如何变化。相比之下,查询结果缓存(query result cache) 只存储 完整查询的结果,即使多个查询使用相同的过滤逻辑,目前 仍无法复用缓存结果。
我们可以用另一个 统计最多椒盐卷饼帖子的语言分布 查询来演示这一点:
SELECT
arrayJoin(CAST(data.commit.record.langs, 'Array(String)')) AS language,
count() AS count
FROM bluesky
WHERE
data.kind = 'commit'
AND data.commit.operation = 'create'
AND data.commit.collection = 'app.bsky.feed.post'
AND data.commit.record.text LIKE '%🥨%'
GROUP BY language
ORDER BY count DESC
SETTINGS use_query_condition_cache = true;┌─language─┬─count─┐
│ en │ 38 │
│ de │ 10 │
│ ja │ 8 │
│ es │ 5 │
│ pt │ 2 │
│ nl │ 1 │
│ zh │ 1 │
│ el │ 1 │
│ fr │ 1 │
└──────────┴───────┘
9 rows in set. Elapsed: 0.055 sec. Processed 1.08 million rows, 98.42 MB (19.83 million rows/s., 1.80 GB/s.)
Peak memory usage: 102.66 MiB.55 毫秒 的查询时间极为迅速,如果没有查询条件缓存,这个查询本应扫描整张表。由于 之前的查询已将匹配情况存入查询条件缓存,ClickHouse 跳过了大部分粒度,从而 大幅减少了需要扫描的行数。
为了对比,我们 禁用查询条件缓存 后 再次运行相同查询:
SELECT
arrayJoin(CAST(data.commit.record.langs, 'Array(String)')) AS language,
count() AS count
FROM bluesky
WHERE
data.kind = 'commit'
AND data.commit.operation = 'create'
AND data.commit.collection = 'app.bsky.feed.post'
AND data.commit.record.text LIKE '%🥨%'
GROUP BY language
ORDER BY count DESC
SETTINGS use_query_condition_cache = false;┌─language─┬─count─┐
│ en │ 38 │
│ de │ 10 │
│ ja │ 8 │
│ es │ 5 │
│ pt │ 2 │
│ nl │ 1 │
│ zh │ 1 │
│ el │ 1 │
│ fr │ 1 │
└──────────┴───────┘
9 rows in set. Elapsed: 0.601 sec. Processed 99.43 million rows, 9.00 GB (165.33 million rows/s., 14.96 GB/s.)
Peak memory usage: 418.93 MiB.此时,查询 退回到了近乎完整表扫描的状态,因为 它无法充分利用表的主索引,导致查询效率下降。
复用查询谓词:椒盐卷饼帖子的发布时间高峰
我们最后再运行一个查询,来完成这次 椒盐卷饼帖子的分析。这个查询 依然复用了之前的查询谓词,用于分析 Bluesky 上发布椒盐卷饼帖子的热门时段:
SELECT
toHour(fromUnixTimestamp64Micro(data.time_us)) AS hour_of_day,
count() AS count,
bar(count, 0, 10, 30) AS bar
FROM bluesky
WHERE
data.kind = 'commit'
AND data.commit.operation = 'create'
AND data.commit.collection = 'app.bsky.feed.post'
AND data.commit.record.text LIKE '%🥨%'
GROUP BY hour_of_day
SETTINGS use_query_condition_cache = true;┌─hour_of_day─┬─count─┬─bar──────────────────────┐
│ 0 │ 2 │ ██████ │
│ 1 │ 6 │ ██████████████████ │
│ 2 │ 6 │ ██████████████████ │
│ 3 │ 6 │ ██████████████████ │
│ 4 │ 1 │ ███ │
│ 5 │ 4 │ ████████████ │
│ 6 │ 3 │ █████████ │
│ 7 │ 3 │ █████████ │
│ 9 │ 6 │ ██████████████████ │
│ 10 │ 8 │ ████████████████████████ │
│ 16 │ 2 │ ██████ │
│ 17 │ 2 │ ██████ │
│ 18 │ 4 │ ████████████ │
│ 19 │ 2 │ ██████ │
│ 20 │ 2 │ ██████ │
│ 21 │ 3 │ █████████ │
│ 22 │ 2 │ ██████ │
│ 23 │ 7 │ █████████████████████ │
└─────────────┴───────┴──────────────────────────┘
Query id: 5ccec420-6f13-43c2-959e-403054d9243a
18 rows in set. Elapsed: 0.036 sec. Processed 884.74 thousand rows, 78.37 MB (24.38 million rows/s., 2.16 GB/s.)
Peak memory usage: 83.42 MiB.在查询日志中验证缓存命中情况
除了 查看跟踪日志(trace logs),我们可以 不用查看跟踪日志,而是直接查询 query_log 系统表,方法是使用 上面查询返回的 Query ID 来验证 查询是否受益于查询条件缓存。
SELECT
ProfileEvents['QueryConditionCacheHits'] AS num_parts_with_cache_hits,
ProfileEvents['QueryConditionCacheMisses'] AS num_parts_with_cache_misses
FROM system.query_log
WHERE
type = 'QueryFinish'
AND query_id = '5ccec420-6f13-43c2-959e-403054d9243a';┌─num_parts_with_cache_hits─┬─num_parts_with_cache_misses─┐
│ 5 │ 0 │
└───────────────────────────┴─────────────────────────────┘ClickHouse 在 查询涉及的 5 个数据分片 中 都找到了缓存命中,说明 查询条件缓存成功生效。
总结
查询条件缓存 虽然简单,但对 ClickHouse 的查询性能提升 具有 巨大价值。它在后台 自动优化查询,尤其是对于 带有高选择性过滤条件的重复查询,无需修改表结构或手动优化索引,即可 减少数据扫描量并加速查询执行。无论是 构建仪表板、分析事件流,还是在 JSON 数据流 中追踪社交媒体上的热点内容,查询条件缓存都能帮 ClickHouse 做更少的工作,返回更快的查询结果。
欢迎试用,相信你会对它的效果感到惊喜!
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


















 1993
1993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









