







数据挖掘各流程中常用方法总结(一)
在完成两个kaggle竞赛的教学项目之后,对数据挖掘过程中的常用方法和基本原则有所体会,特此记录,方便今后复习整理。该系列系本人完全原创,对文中存在的不足和错误,望请指正!
在拿到数据的最开始,大多数情况下我们比较难对整个挖掘方法进行一个全盘的制定。事实上,从这两次的数据集看来,我接触到的数据往往存在几个特点:1、数据量和字段数量大,记录数通常破万甚至达到数十万的规模。2、字段意义可能不明确,在桑坦德银行客户满意度预测中,为了保护用户信息,我们拿到的是三百多个脱敏的特征。
因此,在特征繁多或含义不明的数据集中,首先我们难以对这些特征进行逐一分析,此外我们也难以对含义不明的特征进行先验的处理。接下来我们就对数据挖掘中的各个流程中的方法进行简单总结。
读取流程
我们读取的数据集通常来源于csv文件或excel文件,最终我们拿到的是pandas中的DataFrame,为了对数据集的规模有一个整体感知,我们通常会输出数据的记录数和字段数:
data.shape[0],data.shape[1]
此外,对于一些数据集,每条记录的Id可能作为一个特征存储在df中,因此我们应该加以删除。

我们通常可以使用.describe()函数对每个特征的分布情况进行分析,但是当特征太多的时候,我们可以将其转化为csv文件来查看。
#当变量比较多的时候,可以把desc保存为csv打开来看
train.describe().round(3).T.to_csv('./data/santander-customer-satisfaction/describe_train.csv')
EDA过程
当我们对一个特征的分布不了解时,我们往往希望通过作图的方式来对特征的整体分布情况进行分析。我们要关注的有以下几个方面,例如:
- 偏度和峰度
- 特征是分类型变量还是连续性变量
- 这个特征唯一值最多的几个值是什么,占比多少
- 对于目标变量的不同取值,该特征的唯一值分布是否不同(业务向)
- 目标变量的分布
- 特征在某个区间之内的数据占比
绘图函数
接下来,分享几个通用的作图函数,以便后续的分析:
1、绘制目标变量的频率分布
def countplot_target(df,h=500):
'''
:desc 绘制目标变量的频率分布
:param h:数据标签的附加高度
'''
plt.figure(figsize=(5,5))
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False#运行配置参数总的轴(axes)正常显示正负号(minus)
ax = sns.countplot(x='TARGET',data=df)
# ax.patches 表示条形图中的每一个矩形
for p in ax.patches:
height = p.get_height()
ax.text(p.get_x()+p.get_width()/2,height + h,'{:1.2f}%'.format(height*100/df.shape[0]),ha='center')#指定文字显示的位置
plt.title('TARGET变量的频率分布图')
print('满意客户的数量为%i,不满意客户的数量为 %i' % (
df[df['TARGET']==0].shape[0],
df[df['TARGET']==1].shape[0]
))
plt.show()
这里特别指出ax.patches的用法,.patches是针对柱状图中的每一个矩形,ax.text类似于legend,是在每一个矩形上方显示该矩形代表的数据,这里我们需要指定宽、高、文字标签,标签位置四个参数。
2、绘制训练集和测试集某一特征的直方图
#定义绘制函数hisplot_comb
def hisplot_comb(col,train=train,test=test,size=(20,5),bins=20):
'''
绘制训练集和测试集某一特征的直方图
'''
plt.subplots(1,2,figsize=size)#分割界面为1行2列
plt.subplot(121)
plt.title('训练集特征{}的分布'.format(col))
plt.ylabel('频数')
plt.xlabel(col)
plt.hist(train[col],bins=bins)
plt.subplot(122)
plt.title('测试集特征{}的分布'.format(col))
plt.ylabel('频数')
plt.xlabel(col)
plt.hist(test[col],bins=bins)#bins:直方图的柱数,即要分的组数
plt.show()
3、绘制特征在训练集和测试集中出现频率最高和最低的五个数据
def valuecounts_plot(col,train=train,test=test):
'''
绘制训练集和测试集特定列的频数分布折线图,并输出出现百分比最高的前5个值和最低的前5个值
'''
plt.subplots(1,2,figsize=(15,6))
plt.subplot(121)
df = train[col].value_counts().sort_index()
sns.lineplot(x=df.index,y=df.values)
plt.title("%s的频数分布折线图" % (col))
plt.ylabel('频数')
plt.subplot(122)
df = test[col].value_counts().sort_index()
sns.lineplot(x=df.index,y = df.values)
plt.title("%s的频数分布折线图" % (col))
plt.ylabel('频数')
plt.tight_layout()
#tight_layout会自动调整子图参数,使之填充整个图像区域。
# 这是个实验特性,可能在一些情况下不工作。它仅仅检查坐标轴标签、刻度标签以及标题的部分。
plt.show()
print("*"*100)
print("训练集特征'%s'其值占比(top 5): " % (col))
print("值\t 占比%")
print((train[col].value_counts()*100/train.shape[0]).iloc[:5])
print("*"*100)
print("训练集特征'%s'其值占比(bottom 5): " % (col))
print("值\t 占比%")
print((train[col].value_counts()*100/train.shape[0]).iloc[-5:])
print("测试集特征'%s'其值占比(top 5): " % (col))
print("值\t 占比%")
print((test[col].value_counts()*100/test.shape[0]).iloc[:5])
print("*"*100)
print("测试集特征'%s'其值占比(bottom 5): " % (col))
print("值\t 占比%")
print((test[col].value_counts()*100/test.shape[0]).iloc[-5:])
4、特征在不同目标变量下的分布
#定义绘图函数hisplot_target
def histplot_target(col,df=train,height=6,bins=20):
'''
:param col: 特征
:param df: 数据集
:param height: 附加高度
:param bins: 柱子数量
:return:
'''
sns.FacetGrid(data=df,hue='TARGET',height=height).map(plt.hist,col,bins=bins).add_legend()
plt.title('特征%s在不同目标变量下的频数分布' % (col))
plt.ylabel('频数')
plt.show()
这里sns.FacetGrid是一个功能十分强大的函数,这里是指定数据集按照target进行分组,对指定的col特征应用plt.hist函数并且添加图例add_legend()
sns.FacetGrid
百分位数
在探索性数据分析的过程中,有时候,我们希望通过分位数来对特征进行分析和处理,这里介绍两种获取百分位值的方法:
1、得到特征的某一百分位数的值
np.percentile(train[col],99)
2、得到某一百分位数之间的数据占所有数据的比例
stats.percentileofscore(train['var15'].values,30)
偏态分布
我们在绘制特征的分布的时候,一些连续性变量往往会呈现出偏态分布的特点
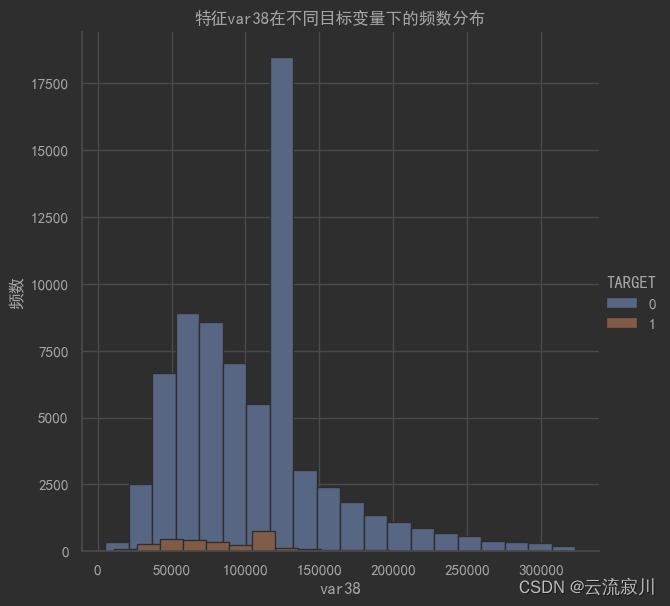
如图所示,除了一些特殊值以外,整体数据在较小且少部分数据非常大,即中位数小于均值,这种我们称为右偏分布。在数据挖掘过程中,无论是右偏分布还是左偏分布,我们通常采用对数变换来进行修正,使之近似满足正态分布
缺失值处理
我们拿到的原始数据中,由于各种各样的原因,往往会存在各种各样的缺失数据,就目前而言,缺失值主要来源有以下两个方面:1、数据录入过程中由于设备、偶发的异常等导致的数据缺失和不符合逻辑。2、由于某些特征本身就是一个较为苛刻的条件,例如:“家中泳池的面积”,“家中豪车的平均价格”。综合上面的缺失来源产生了很多的缺失值。
all_data_na = (all_data.isnull().sum() / len(all_data)) * 100#输出每个特征的缺失率
all_data_na
all_data_na = all_data_na.drop(all_data_na[all_data_na ==0].index).sort_values(ascending=False)#过滤缺失率为0的特征并降序排列
对于不同类型的特征,我们不能一概而论,即采取整列删除或删除少部分有缺失值的行。总体来讲,对于缺失值的处理我们有三种策略:
-
删除法
这种方法通常是将含有缺失值的行或列删除,一般地,如果一个特征的缺失值比例达到了80%以上,我们就有理由将这个特征全部删除.
但同时,暴力删除法往往也会使得数据集损失大量的有效信息,从而使得模型的预测能力下降,另外,删除大量的信息也有可能改变特征本身的分布,偏离正态分布程度很大。 -
填补法
这种方法会根据不同的数据特点,对数据中存在的缺失部分进行填值,常见的有:
1、众数插补
2、中位数插补
3、均值插补
数据的属性分为定类和定量。如果缺失值是定量,用属性的平均数(mean)(正态分布) 或中位数(median)(⻓尾分布)填补;如果缺失值是定类,用该属性的众数(即出现频率最高的值)来补齐缺失的值。
具体使用哪种策略,可以根据数据的实际情况考量。填补法的优点是能够有效地保留数据行;同时针对某一特定数据列,在统计学上也可以有效地保留数据特性。但填补法也有一定的缺点,就是根据数据列填补时,若涉及到统计学或分析等,可能会引入一定的误差,从而会对模型训练和推断造成影响。
- 插补法
插补法是对填补法的升级,是将缺失值用模型来拟合或推断出来,使用最佳拟合的参数来替代缺失值的一种方法。插补法的特点是可以根据剩余的有效样本最接近的特征拟合缺失值,因此可以更有效地保留数据特性,但也有拟合精度上的限制。
这里分享三种常见的用于插补的模型:
1、回归插补
2、KNN插补
3、RandomForest插补
本质上,利用模型的插补方法都是将目标缺失值所在特征作为目标变量,将其他变量作为已知特征,进行模型的拟合,然后将缺失值以预测值的形式插补进去。
数据预处理
对于偏态分布的处理
在回归分析中,各类回归模型往往会要求数据集的各类特征甚至是目标变量具有近似正态分布的特性,有些模型的应用条件就是要求数据满足正态性分布的。比如说:贝叶斯、逻辑回归、KNN、Kmean等设计到概率分布、参数距离比较等,转换为正态分布,模型条件更充足。
其次,正态分布,数据的泛化性高。因为自然界很多事物的概率密度很大是正态分布的。
最后,从目标分布来说,偏态分布会导致label数据的MSE出现误导,或许结果看着很小,但实际结果很大。
然而,在实际问题的处理过程中,由于样本规模小,分布特点不可能与正态分布完全一致,即出现一定的偏态。因此,我们有必要对某些出现偏态的特征进行纠偏操作。
偏态的检测
频数分布图与QQ图
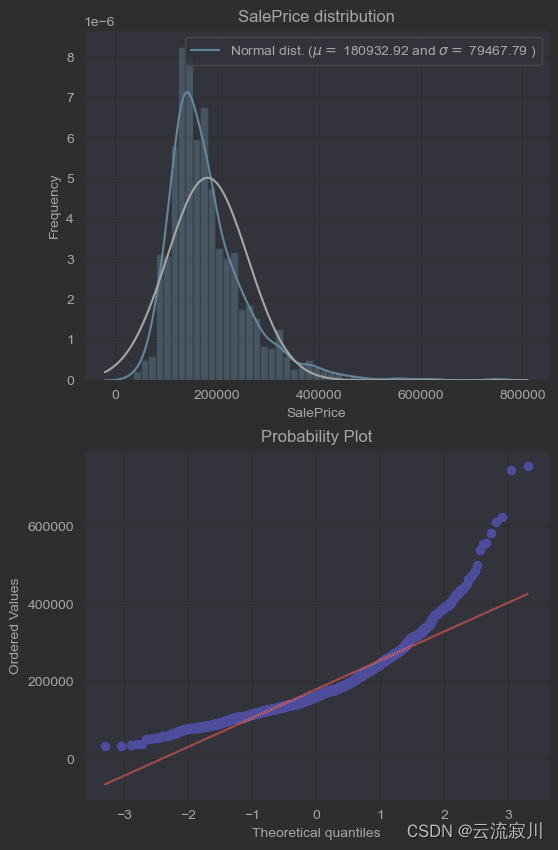
对于偏态的检测,第一种方式是直接绘图。频数分布图可以直观的展现数据的分布特点,与标准正态分布曲线对比,我们可以粗略的知道特征是否出现了偏态。
另一种方式为QQ图,QQ图是由标准正态分布的分位数为横坐标,样本为纵坐标绘制而成的散点图。如果QQ图上的点在一条直线附近,则说明数据近似于正态分布,且该直线的斜率为标准差,截距为均值。这种图可以在更细致地体现数据的偏离正态的程度。
直接输出特征偏度值
如果我们想用数字量化偏度具体的程度,直接输出偏度峰度是很好的方法。
#计算特征的偏度
numeric_data = all_data[numeric_feats]
skewed_feats = numeric_data.apply(lambda x:skew(x.dropna())).sort_values(ascending=False)
skewness = pd.DataFrame({'skew':skewed_feats})
skewness
上面的代码输出了numeric_data中每一列的偏度,并按照降序排序,结果如下:
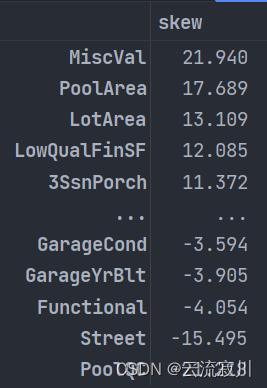
代表特征呈现负偏态或左偏态,即大部分对象高于均值,但是有少部分对象特征值过低,拉低了整体的水平,体现出中位数小于均值的特点。这里所谓的左偏和右偏的叫法,是根据尾部的方向来说的。如果尾部在左侧,那么它是左偏(负偏);而尾部是在右侧,它是右偏(正偏)偏度为负。
| 偏度 | 偏度值 |
|---|---|
| 对称 | -0.5 到 0.5 |
| 中度正/负偏度 | -0.5 到 -1.0 以及 0.5 到 1.0 |
| 高度正/负偏度 | < -1.0 以及 > 1.0 |
偏态的处理
一般来说,如果一个呈现出偏态分布,我们通常考虑对其进行对数变换:
train['SalePrice'] = np.log1p(train['SalePrice'])
或者
mask['var38'] = np.log(mask.var38).values
np.log(x) 以e为底的对数(自然对数)
np.log10(x) 以10为底的对数
np.log2(x) 以2为底的对数
np.log1p(x) 等价于:np.log(x + 1)
当然,对数变换不总是适用的。一般地,对于像上述偏度非常大的特征,采用对数变换往往有效,但对于一些中度偏态的特征,我们考虑采用np.sqrt(),即开方变换的方法来纠偏。中度和重度偏态的辨别方法如下:
| skew | kurtosis | |
|---|---|---|
| 中度正偏度 | 0.656308 | 0.584120 |
| 高度正偏度 | 1.271249 | 2.405999 |
| 中度负偏度 | -0.690244 | 0.790534 |
| 高度负偏度 | -1.201891 | 2.086863 |
一般来讲,偏度大于0.6,小于1.2,就被认为是中度偏态,大于1.2的被认为是重度偏态。
那么,有没有一种方法,可以根据数据的特点自动选择纠偏的方法呢。显然是有的,我们将其称为Box-Cox变换
我们用一个公式来统一上面两种函数,看公式,
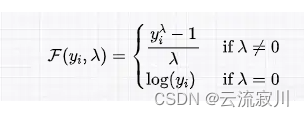
调用 scipy 的 boxcox
至于参数值是如何从数据中估计的我们先不管它,接下来直接使用 SciPy 提供的 Box-Cox 来估计参数以及变换数据。
# import modules
import numpy as np
from scipy import stats
from sklearn.model_selection import train_test_split
# transform training data & save lambda value
train_data,fitted_lambda = stats.boxcox(train)
# use lambda value to transform test data
test_data = stats.boxcox(test, fitted_lambda)
下面三张QQ图按照原始图像,对数变换,Box-Cox变换的顺序展现纠偏效果
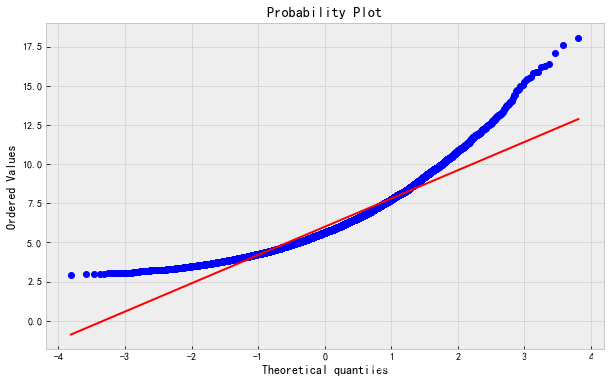
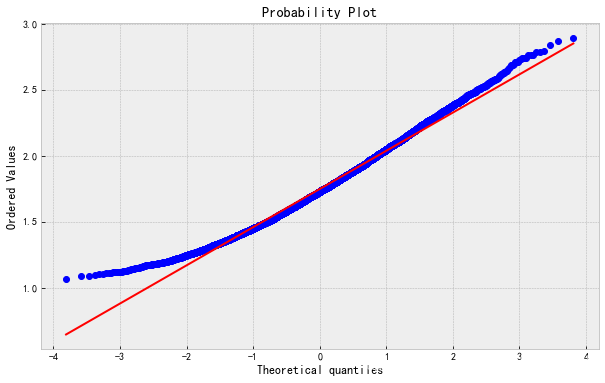
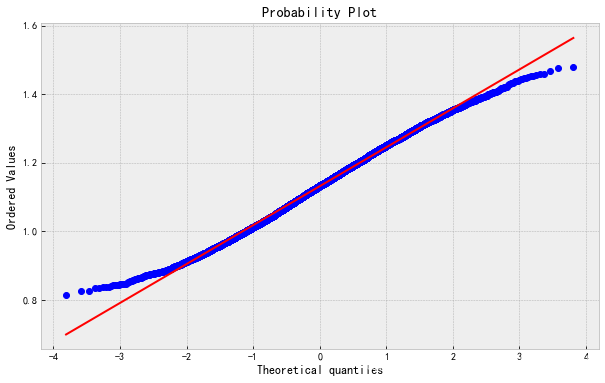
实践证明,Box-Cox 变换比开根号和对数变换的纠偏效果更好。
from scipy.special import boxcox1p
skewed_features = new_skewness.index
lam = 0.15
for feat in skewed_features:
all_data[feat] = boxcox1p(all_data[feat],lam)#指定要平滑的列和需要平滑到的峰度
过滤占比大的无效信息
一些特征在实际情况中往往呈现出某一个特征值占比非常大的情况,由于这类值的存在,“少数派”数据的分布特点无法被我们捕捉,因此在对整个特征进行可视化展现的时候,往往会一无所获。
因此,我们可以在可视化之前过滤“多数派”,只绘制少数派的分布图像。下面是一个案例:
# 绘制特定列的频数分布折线图
valuecounts_plot(train=train, test=test, col=col)
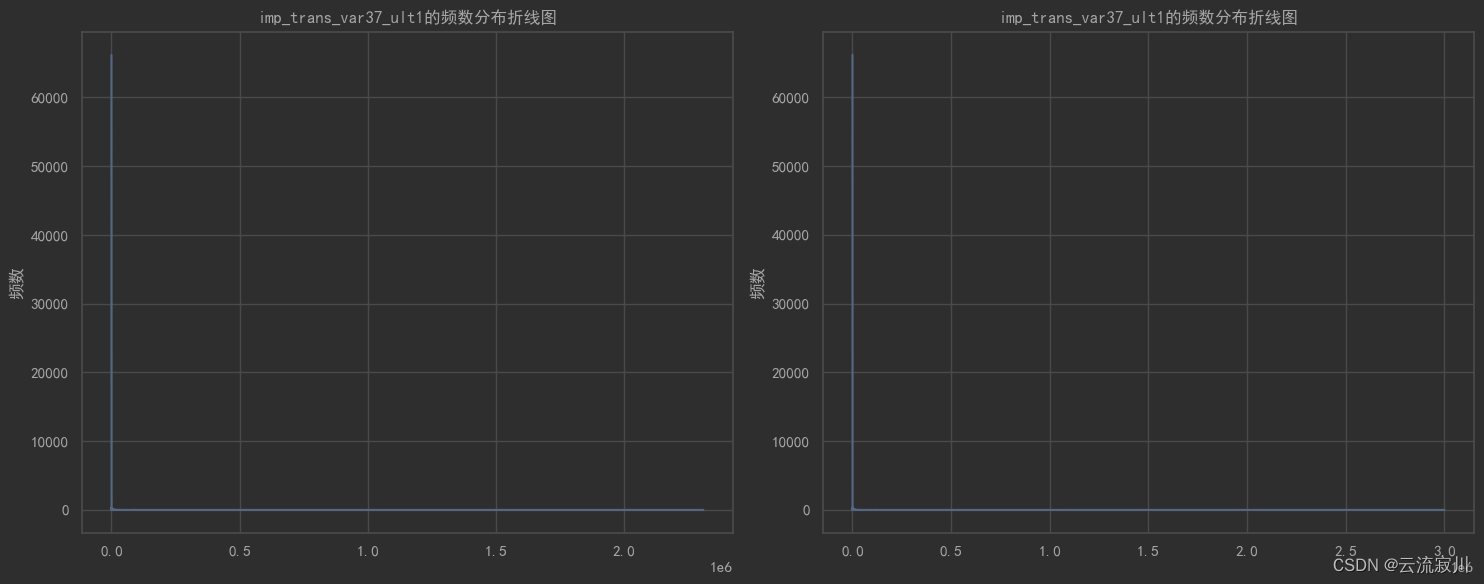
****************************************************************************************************
训练集特征'imp_trans_var37_ult1'其值占比(top 5):
值 占比%
0.0 87.069192
300.0 0.536701
600.0 0.420942
1500.0 0.361747
150.0 0.344646
......
valuecounts_plot(train=train[train[col] != 0],test=test[test[col] != 0],col=col)
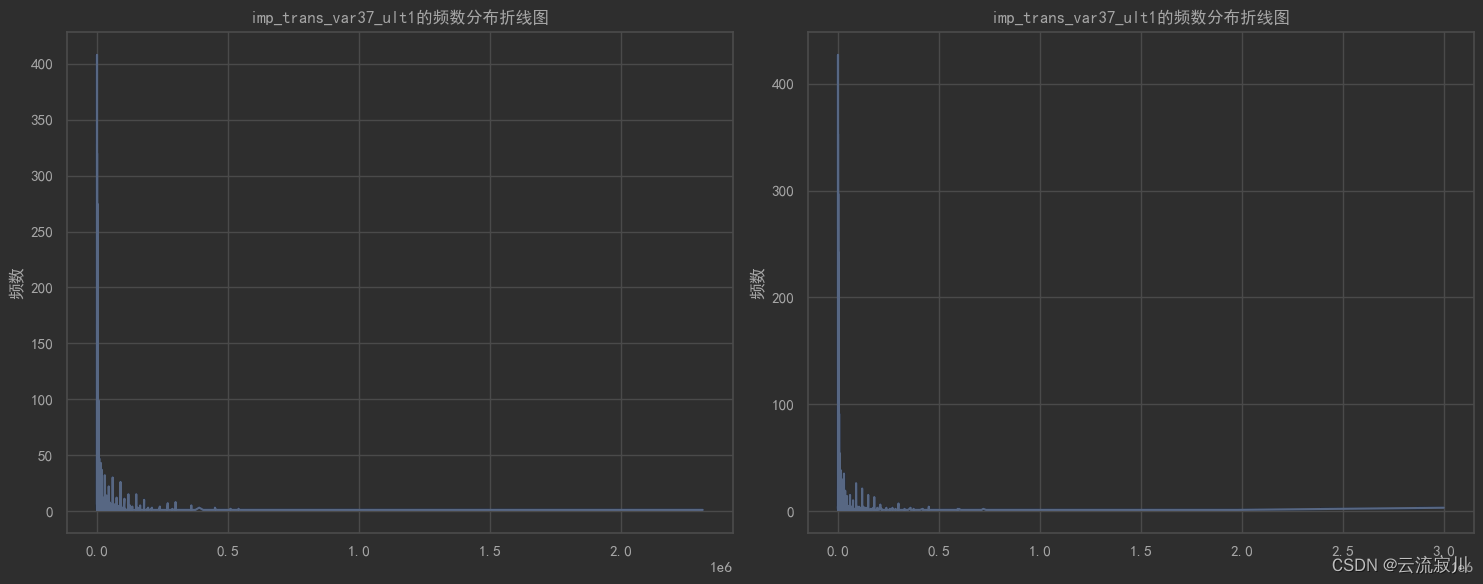
训练集特征'imp_trans_var37_ult1'其值占比(top 5):
值 占比%
300.0 4.150560
600.0 3.255341
1500.0 2.797558
150.0 2.665310
900.0 2.492370
df = train[train[col] != 0]
df1 = test[test[col] != 0]
for data in [df, df1]:
data.loc[data[col] != 0, col] = np.log(data.loc[data[col] != 0, col])
hisplot_comb(col, train=df, test=df1)
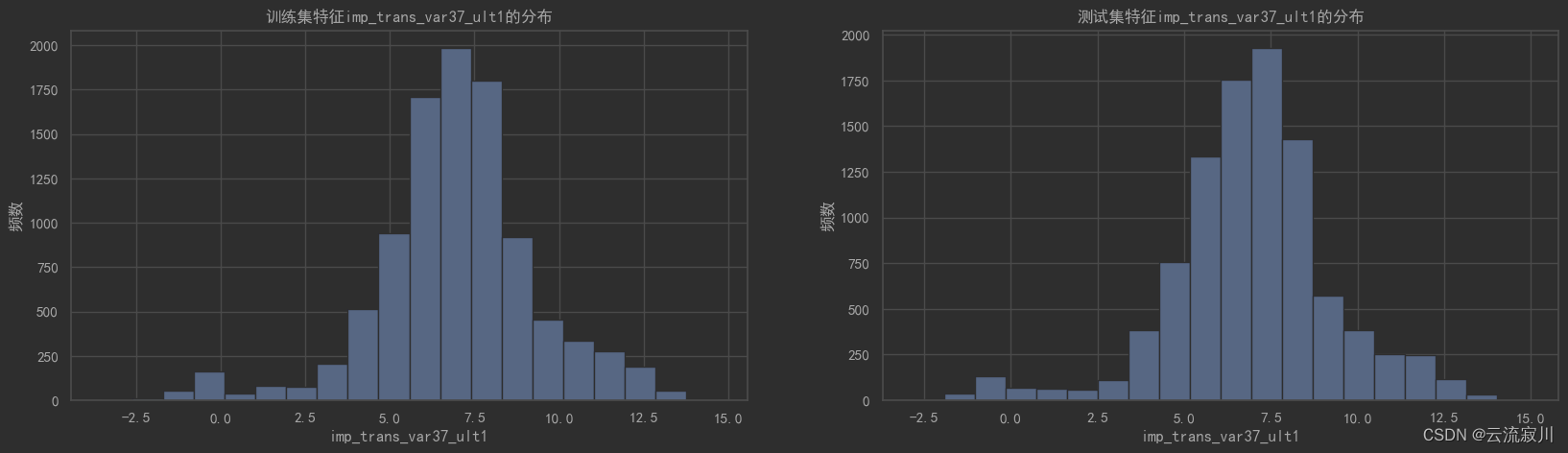
特征转换
1、转换部分数值特征为分类特征
我们注意到有些特征虽然是数值型的,但其实表征的只是不同类别,其数值的大小并没有实际意义,因此我们将其转化为分类特征
all_data['MSSubClass'] = all_data['MSSubClass'].apply(str)#apply函数默认对列进行操作
all_data['YrSold'] = all_data['YrSold'].apply(str)
all_data['MoSold'] = all_data['MoSold'].apply(str)
2、转换部分分类特征为数值特征
反过来,有些类别特征实际上有高低好坏之分,这些特征的质量越高,就可能在一定程度上导致房价越高
我们将这些特征的类别映射成有大小的数字,以此来表征这种潜在的偏序关系。(标签编码:LabelEncoder)
#处理列,将标签编码应用于分类特征
for c in cols:
lbe = LabelEncoder()
all_data[c] = lbe.fit_transform(list(all_data[c].values))
衍生(交互)特征的构建
特征交互也叫特征组合,通过将两个或多个特征相乘,来实现对样本空间的非线性变换,增加模型的非线性能力。从本质上讲,特征交叉是利用非线性映射函数将样本从原始空间映射到特征空间的过程,有点像机器学习中的核函数技巧。因此,可以认为,特征交叉的意义就在于提高模型的非线性建模能力,提升模型的效果。
一个更好地诠释好的交叉特征的实例是类似于(经度,纬度)。一个相同的经度对应了地图上很多的地方,纬度也是一样。但是一旦你将经度和纬度组合到一起,它们就代表了地理上特定的一块区域,区域中每一部分是拥有着类似的特性。
我们再用一个更通俗易懂的案例来解释
设想你要预测一个厨房做菜的时间,输入主要包括了菜品和厨房编号。如果我们只是拿菜品当特征,那就会得到做剁椒鱼头需要多长时间,做小炒黄牛肉需要多长时间。而每个厨房的厨师多少不一样,厨师水平也不一样,光是拿菜品当特征,同时又要拟合所有数据,这个会导致模型非常拧巴,因为一个菜品的weight要适应不同的厨房,而又只有一个weight(比如我们就用线性模型)。这个时候怎么办呢?我拿菜品和厨房id做交叉,原来剁椒鱼头是一个特征,现在剁椒鱼头+厨房1, 剁椒鱼头+厨房2.。。。就有了多个交叉特征。如果你从剁椒鱼头的角度来看,你就会发现,这不是把剁椒鱼头给向量话了么,剁椒鱼头向量化成了{厨房1, 厨房2, 。。。},每个厨房对应一个weight。所以在我看来,交叉就是相互把对方给向量化,这个也可以看做embedding的朴素来源,同时这种embedding的维度还是变化的。比如剁椒鱼头只有5个厨房能做,而小炒黄牛肉没那么麻烦,有8个厨房能做,因此剁椒鱼头就变成了5维向量,而小炒黄牛肉就变成了8维向量,比固定维度更好理解,也更符合直觉。以前剁椒鱼头一个weight要适应100个样本,有出现大bias的可能性,现在向量话以后,空间更大,weight更容易得到调整。
上面提到的案例大多是简单地对两个特征进行拼接或者相乘,没有更深层次的交互。下面我们分享两个特征的交互案例,在一般的房价预测任务中,一些特征被认为是体现房屋特点的重要因素:
- TotalBsmtSF:地下室总面积
- 1stFlrSF:一层面积
- 2ndFlrSF:二层面积
- OverallQual:整体材料和装饰综合质量
- GrLivArea:地上生活面积
- TotRmsAbvGrd:地上总房间数
- GarageArea:车库面积
- YearBuilt:建造时间
对于面积来说,地下室、一层、二层面积都代表着房屋面积的一个方面,要说明房屋到底有多大,我们可以把三个特征的值进行相加,构成“房屋可用总面积”。另外,材料和装饰综合质量相近的住宅,其房价受到多个因素的影响,往往产生不小的差异。因此,我们将材料和其他因素进行相乘,反映出在重点关注这两个方面的前提下房屋的质量。
# 构造更多的特征
all_data['TotalSF'] = all_data['TotalBsmtSF'] + all_data['1stFlrSF'] + all_data['2ndFlrSF'] # 房屋总面积
all_data['OverallQual_TotalSF'] = all_data['OverallQual'] * all_data['TotalSF'] # 整体质量与房屋总面积交互项
all_data['OverallQual_GrLivArea'] = all_data['OverallQual'] * all_data['GrLivArea'] # 整体质量与地上总房间数交互项
all_data['OverallQual_TotRmsAbvGrd'] = all_data['OverallQual'] * all_data['TotRmsAbvGrd'] # 整体质量与地上生活面积交互项
all_data['GarageArea_YearBuilt'] = all_data['GarageArea'] * all_data['YearBuilt'] # 车库面积与建造时间交互项
另外,对于更深层地交互,下面的银行客户满意度预测案例进行了展现:
def average_col(col,features,train=X_train,test=X_test):
'''
获取'col'特征中每一种唯一值的情况下feature特征的均值,并令其为新特征
'''
for df in [train,test]:
unique_values = df[col].unique()
for feature in features:
#对每一个特征求他在指定特征col的每一个唯一值下的均值
avg_value = []
for value in unique_values:
#对于每一个特征列col,求其每一种唯一值的情况下feature特征的均值
avg = df.loc[df[col] == value,feature].mean()
avg_value.append(avg)
avg_dict = dict(zip(unique_values,avg_value))
new_col = 'avg_'+ col + '_' + feature
df[new_col] = np.zeros(df.shape[0])#新建新特征
for value in unique_values:
df.loc[df[col]==value,new_col] = avg_dict[value]
我们已知,saldo特征和imp特征的分布较为零散,且呈现一个左偏分布的特点,因此我们考虑利用构造他们的均值来作为一个新特征。但是,取所有记录的均值只能得到两列毫无波动的特征,如何才能体现出均值的波动呢?我们前面提到过特征的分布是零散的,也就是说特征是以簇状、集群来分布的,我们可以猜测:这两类特征以某几个其他特征的某些唯一值分组,组内的特征值大体相近,即在同一水平。因此,我们取唯一值个数在[50,210)的特征,我们称为可以称为标靶特征,saldo和imp特征称为子弹特征,我们取每一个标靶特征在其每一个唯一值的情况下,对应子弹特征的均值。每一个标靶特征和每一个子弹特征的组合构成一个新特征。这样我们新增了700多个特征,代表了子弹特征均值的波动。
这一块目前我的水平有限,理解的还不够深刻,之后有了更深的认识我会进行更新…














 1129
1129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









