







 本文详细介绍了音视频从采集、处理、压缩编码、封装到推流的全过程,包括压缩编码的原理,如I帧、B帧、P帧以及空间冗余、时间冗余、视觉冗余和编码冗余。文章还讨论了常见的编码格式选择、封装过程、推流协议的优缺点,以及流媒体协议的延迟特性。
本文详细介绍了音视频从采集、处理、压缩编码、封装到推流的全过程,包括压缩编码的原理,如I帧、B帧、P帧以及空间冗余、时间冗余、视觉冗余和编码冗余。文章还讨论了常见的编码格式选择、封装过程、推流协议的优缺点,以及流媒体协议的延迟特性。
上次好早之前也写过一篇,随着工作的深入对这块知识又巩固了一遍,算是一个重写和扩展版
旧的总结跳转,那么有啥不同呢?
1. 介绍协议的优缺点以及怎么选择
2. 会介绍压缩编码的原理
3. 测试关注的质量指标
那么基本框架其实是不变的,都是采集–压缩编码–封装–推流–分发–流媒体协议观看
把架构图重新画了一遍,比上次精细了许多,重写版就是基于这个框架的深入介绍
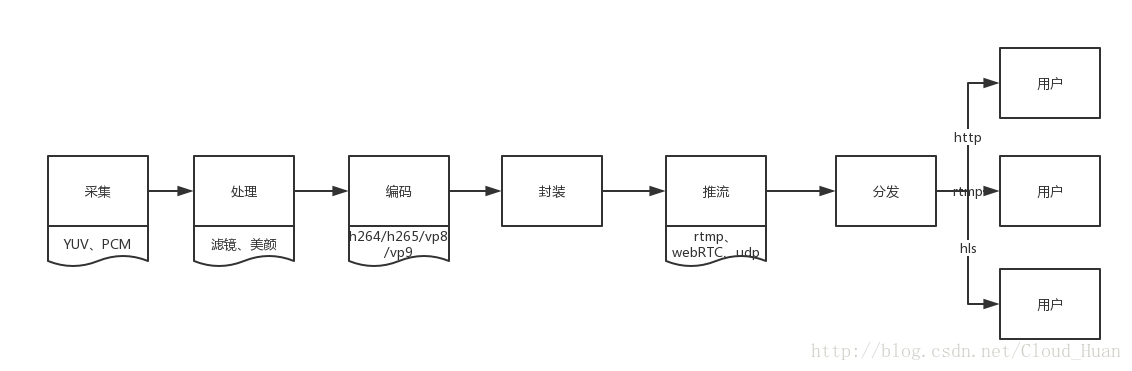
采集
我们知道计算机都是只认识二进制的,所以对于视频采集,其实就是把实际看到的东西转为二进制的格式,采集就是转为二进制流的过程。
这部分其实实际测试中关注的是比较少的,因为客户端针对的都是采集好的原始视频或音频流做处理,这里要知道采集成的格式视频是YUV,音频是PCM。
YUV来说,其中“Y”表示明亮度(Luminance或Luma),也就是灰阶值;而“U”和“V” 表示的则是色度(Chrominance或Chroma),作用是描述影像色彩及饱和度,用于指定像素的颜色。
处理
处理的过程主要是美颜和滤镜了,重点说说美颜,美颜有两步,一个是磨皮,一个是美白,要想正确美颜,所以还需要加上人脸识别技术和皮肤识别技术。
这里要说说题外话,美颜在压缩编码前处理可以说是最自然的,缺点也有,不能修改。所以也有一种是通过播放器渲染”美颜”。效果嘛,呵呵。可惜的是我们项目美颜滤镜就是这样做的,个人还是不敢苟同的,这样做缺点非常明显,画质不忍直视,还要十分拖累帧数,优点嘛,修改和实现非常简单,成本也低
在针对原始流的处理,除了滤镜美颜外,还可以自定义打logo,修改画面内容。
压缩编码
首先,要知道的是,一个视频是由一个个画面组成的,多个画面连续运动便构成了动画,也就是视频,一个个画面我们称为帧(笔者想起小时候玩的小玩具,一个小本本,里面有很多相似的图画,然后像翻书那样快速翻过,形成了动画)。
原始视频流是很大的,需要压缩,那么最简单的办法就是”推测”
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3450
3450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









