






 文章介绍了七种主要的软件规模估算方法,包括LOC、故事点、FPA、COSMIC、QFPA、IFPUG功能点估算以及自动化功能点估算。其中,CoCode需求分析工具利用AI和NLP技术实现了自动化估算,显著提高了效率。该工具提供智能项目管理、需求分析等功能,支持CMMI落地。
文章介绍了七种主要的软件规模估算方法,包括LOC、故事点、FPA、COSMIC、QFPA、IFPUG功能点估算以及自动化功能点估算。其中,CoCode需求分析工具利用AI和NLP技术实现了自动化估算,显著提高了效率。该工具提供智能项目管理、需求分析等功能,支持CMMI落地。
业内主要的软件规模估算方法:LOC估算方法、故事点估算法、FPA功能点估算方法、COSMIC功能点估算方法、快速功能点估算方法、IFPUG功能点估算方法和自动化功能点估算方法。
1、LOC估算方法
LOC是源代码的总行数。通过统计源代码中的行数,来估算软件规模。
是最早使用的方法,其实质是一个工作量的代理。它的主要问题是:不能跨语言进行估算。如汇编的代码和和JAVA的代码,同样的100行代码,其代表的工作量是不同的,需要进行换算。
2、故事点估算法(Story Points)
是敏捷开发中使用的一种方法。故事点是用来衡量用户故事大小、复杂度以及数量的单位,故事点用来衡量用户故事的大小和数量。
这个方法的优势是速度快,在跨项目估算时,在定义组织内的基准故事点后,就可以通过故事点数对不同项目中进行估算和比较。但这个估算方法不是很准确,偏差范围比较大。
3、FPA功能点估算方法
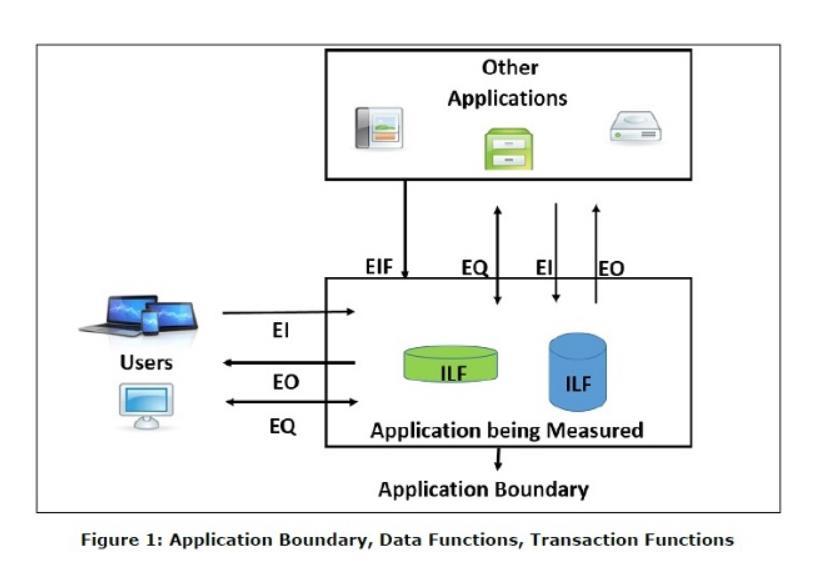
是一种功能点估算方法,它通过评估输入、输出、查询、接口和数据存储来计算功能点。
这个方法的优势是估算较为完整,准确,覆盖面较广。但是它较为复杂,花费时间较多。
4、COSMIC功能点估算方法
是欧洲的组织建立的,是一种更为现代的功能点计算方法,用于评估软件的大小,它主要侧重数据移动,从这个角度来估算软件规模,在多层次的软件系统中适用。
5、QFPA快速功能点估算方法
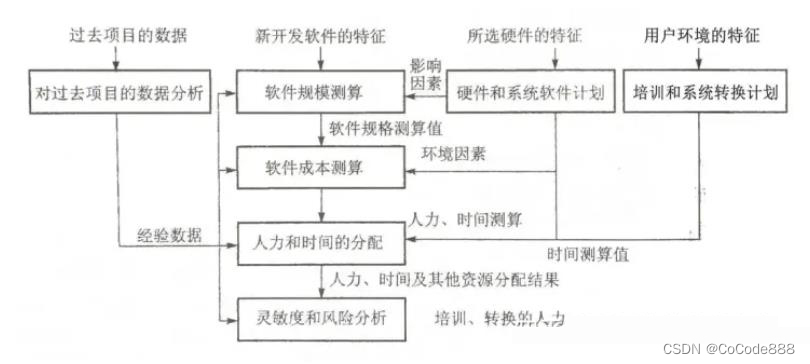
是出自中国国家标准《信息技术信息系统开发项目管理规范》,这个估算方法的估算准确度较高,但此方法较为复杂,需要经过培训,学习成本高,花费时间较多。
6、IFPUG功能点估算方法
国际功能点用户组织来定义的一种功能点计算方法,使用范围较广。
7、自动化功能点估算方法
自动化功能点估算方法,是近两年兴起的,基于自然语言和AI技术,旨在解决专业估算人员短缺、效率低下和准确性不足的问题。随着AI时代的发展,自动化估算方法将会成为业内主流的规模估算方法。
而“CoCode需求分析工具”是国内第一款自动化软件规模估算工具,是通过NLP自然语言的AI分析的算法,实现对功能点的识别,内部逻辑文件和外部逻辑文件的实现,从而能够自动估算项目规模、工作量和产品报价。
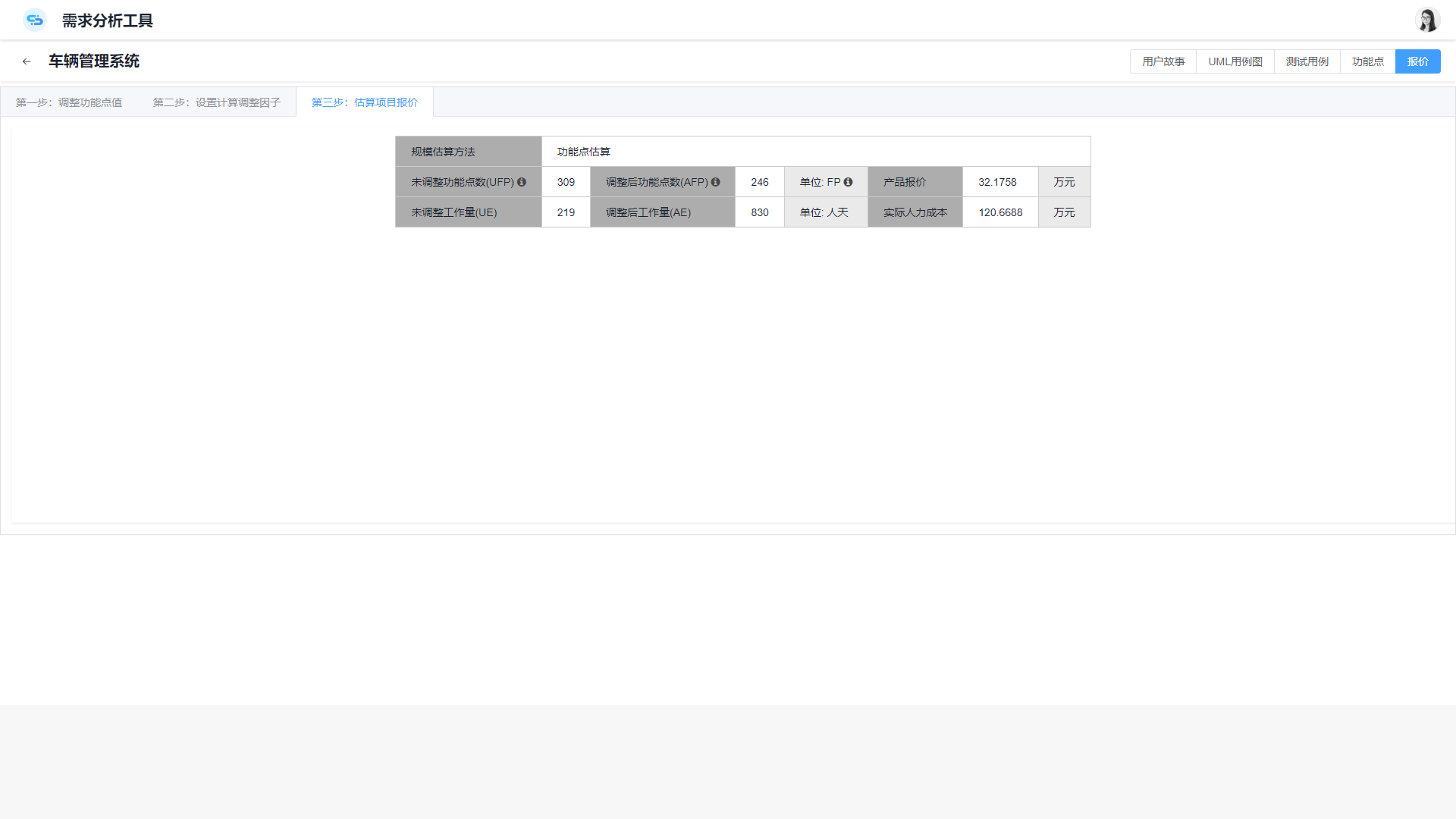
案例数据显示,使用该需求分析工具,原本需要两周完成的软件规模估算工作,现仅需两小时,实现了40倍的生产率提升。
CoCode发布四大开发工具:Co-Project智能项目管理工具、需求分析工具、评审分析工具、故事点估算工具。项目管理平台发布4大版本,30天免费试用。CMMI落地工具上线,全面支持CMMI3-5级高效落地。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









