






尽管大模型厂商不大会收集用户调用模型API时传入的数据,但企业多少会有些不放心把某些敏感的内部数据传输到外部大模型,这势必限制了LLM在企业中的使用场景。为了避免这个安全合规“风险”,这段时间有机会在一块英伟达RTX4090 GPU显卡上做LLM模型本地化测试工作。这篇文章就简单记录一下模型本地化部署的相关内容。
测试用的GPU卡有24GB内存,我们分别做了文本生成(Text Generation),嵌入(Embedding) 和重排序(ReRanker)模型的本地部署和测试验证。采用目前比较成熟的模型本地化部署平台(Ollama,LocalAI),基本能够实现AI应用需要的全部LLM本地化,也包括 OCR 部署。

1、系统准备
我们用的是Ubuntu系统,系统和GPU显卡安装不是本文重点,就不介绍了。运行 nvidia-smi 工具可以看到类似如下信息说明安装成功。
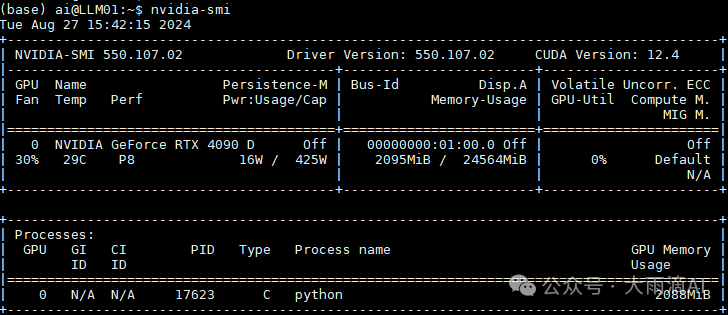
2、Ollama
Ollama是一个基于 Go 语言开发的本地大语言模型运行框架,目前可以支持文本生成和嵌入及其他多模态LLM,但暂时不支持Reranker模型。Ollama简单易用,几乎完全借鉴了Docker的使用和管理方式,熟悉Docker的道友会感受非常亲切。
相关资源
https://ollama.com/ - Ollama 主站点
https://ollama.com/library - Ollama模型库,也支持从HuggingFace模型库下载装入
https://github.com/ollama/ollama - Ollma Github站点
https://huggingface.co/ - HuggingFace
1)安装Ollama
Ollama安装非常简单。我使用的是Ubuntu系统,采用Linux安装方式,
curl -fsSL https://ollama.com/install.sh | sh
安装完成后,运行ollama命令验证安装成功,
ollama --help
ollama --version
ollama list / ollama ps #刚安装好Ollama,还未下载模型时,不会有模型信息

2)模型下载运行
Ollama模型库提供的模型,下载非常简单。先到ollama模型库上去搜索一个已有的模型,

点击模型名称进入详情页面,直接copy运行模型的命令在本地服务器上执行,Ollama会自动先下载该模型并运行。

下载完自动进入交互模式(我这里已经下载过该模型,因此直接进入交互模式了,如果是新下载模型,会看到下载过程),提个问题试试,验证模型下载运行成功。

像qwen2:72b ,llama3.1:70b 这样较大的模型也可以运行起来,GPU不够CPU来凑,Ollama会同时使用本机CPU内存分担,只是推理速度慢很多。

通过另一窗口执行 ollama ps 命令,可以看到当前正在运行的模型情况,

Ollama模型库中大部分常用的模型都是用 Q4_0 这种量化压缩级别进行模型压缩的,以节省GPU内存。模型消耗GPU的计算公式如下,
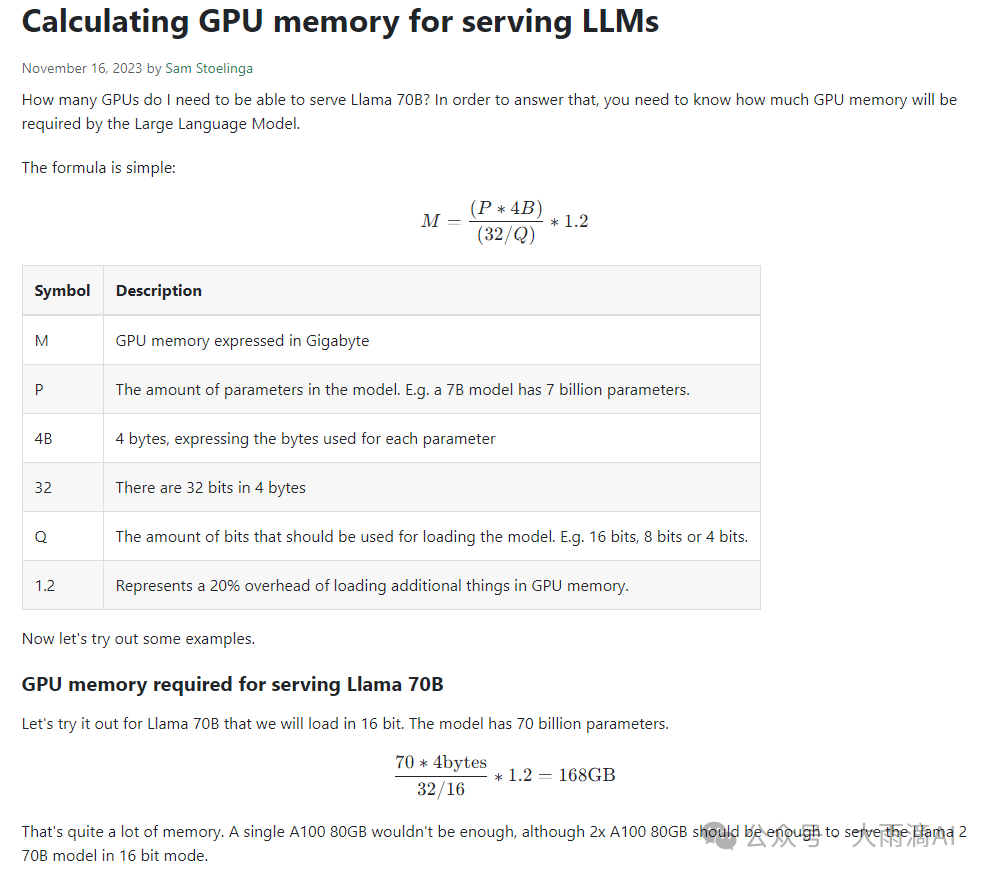
我前面示例中使用的 qwen2:72b Q4_0 压缩级别(Q 参数是 4bits) 计算GPU用量应该是,
72*4B / (32/4) * 1.2 = 43.2(GB)
和 ollama ps 命令显示的SIZE一致。关于模型的量化压缩级别,如 Q4_0, Q4_K_M, Q5_1等,道友感兴趣的话可以自行搜索相关的文章进一步了解。
当用户调用模型时,Ollama会自动装入该模型到GPU内存,并默认设置5分钟空闲切出,以节省GPU资源供其他请求使用。
3)装入HuggingFace模型
Ollama模型库未提供某款模型时,比如我想使用qwen2-7b Instruct模型,但是在Ollama模型库没有提供,那我们只能从HuggingFace下载,再装入Ollama。这里以 qwen2-7b-instruct:q5_k_m 模型为例来说明如何操作。
- Ollama可以直接装入 GGUF 格式的模型文件,因此优先选择下载这种模型文件。如果只有safetensors 格式的模型,需要先转换成 GGUF 格式,后面会介绍。在HF上搜索 “qwen2-7b-instruct",并筛选libraries标签为GGUF的模型,
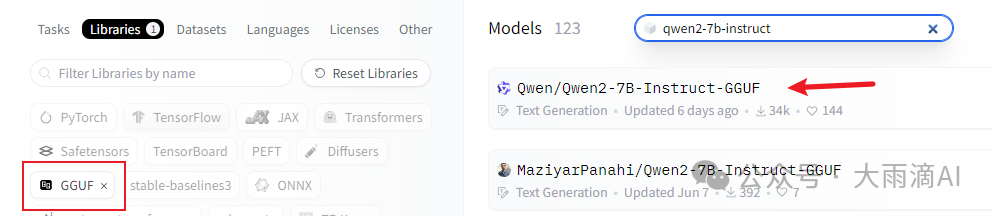
- 进入模型的 “Files and Version” 页面,选择 q5_k_m 模型文件下载,
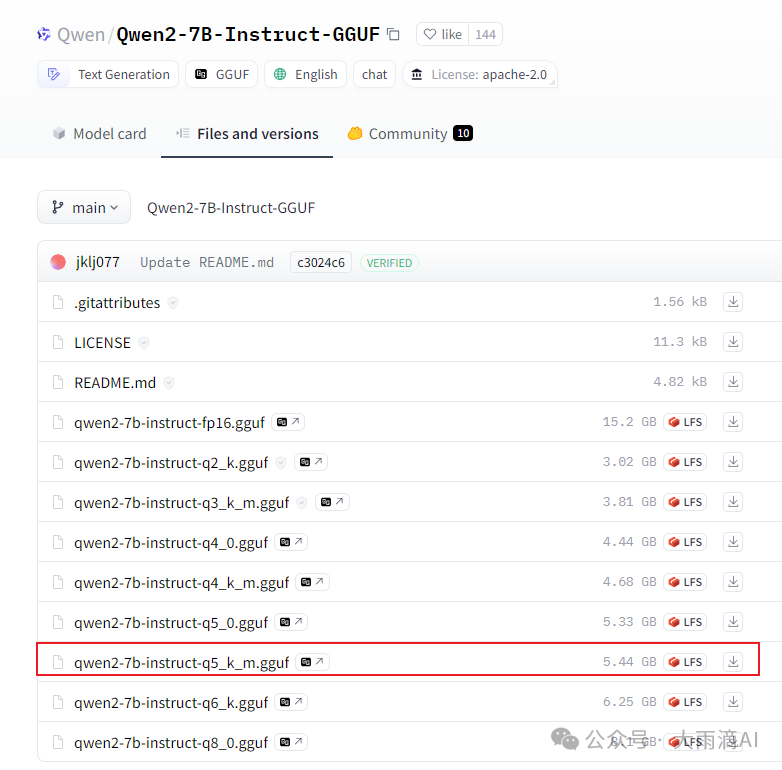
- 下载模型文件到本地服务器目录后,准备一个Modelfile,参考如下内容,
FROM "./qwen2-7b-instruct-q5_k_m.gguf"
TEMPLATE "{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
{{ .Response }}<|im_end|>
"
PARAMETER stop <|im_start|>
PARAMETER stop <|im_end|>
PARAMETER num_ctx 16384
Modelfile的内容中有几个主要参数如下:
● FROM - 指定前面下载的模型文件路径,可以用相对路径或绝对路径;
● PARAMETER - 定义一些模型参数,比如推理终止符,上下文长度等;
● TEMPLATE - 这个很重要,通常HuggingFace的Model Card详情里面有相关信息,如果没有,则可以到 Ollama主页找相同的base模型,比如qwen2的标准模型的详情页面会提供。


如果已经下载过Ollama提供的qwen2 base模型,也可以直接通过 ollama show 命令找到相关的信息,然后复制出来。

有关Modelfile的编写格式,参数设置我目前也了解不多,道友可以自行搜索更多有用的信息。
- 通过以下命令来装载GGUF模型文件到Ollama
ollama create qwen2-7b-instruct:q5_k_m -f Modefile
通过这个命令,Ollama会自动创建模型需要的多个Layers(跟Docker相似),成功后就和从Ollama模型库直接拉取的模型一样使用了。

- 如果HuggingFace上也没有GGUF类型的模型文件,那么下载safetensors文件,然后使用Ollama提供的quantize container转换成GGUF格式模型文件也ok。
docker run --rm -v .:/model ollama/quantize -q q5_K_M /model
转换完成后在当前目录生成一个 f16.bin文件(原始大小的gguf格式模型文件),和一个q5_K_M.bin文件,这个文件就是我们需要的,可以通过前面的步骤装载进Ollama平台的GGUF格式的模型文件。
3、LocalAI
因为Ollama目前不支持Reranker模型,只得再引入一个支持的框架,LocalAI就是其中一款。使用LocalAI部署大模型也比较方便,它支持Reranker模型的方法实际是集成了Rerankers这个Python项目(github上可以找到这个项目)。只是相关文档偏少,学习搞懂如何使用还颇费了一番功夫。
LocalAI资源
https://localai.io/ - LocalAI 官方站点
https://github.com/mudler/LocalAI - LocalAI的Github站点
https://github.com/AnswerDotAI/rerankers - Rerankers项目的GitHub站点
1)部署LocalAI
LocalAI官网有较为详细的安装介绍,其中推荐的也最简单的方式就是使用Docker部署。根据本地服务器上Nvidia显卡驱动和安装的CUDA版本,选择合适的Docker镜像。LocalAI是通过给不同类型的模型提供不同的后端支持模块 - Backend -来运行不同类型的大模型提供服务。为了简单,我选用了AIO(All-In-One)类型的Docker镜像,直接预安装了全部Backend模块,包括Rerankers.

这个docker镜像比较大,是一个独立完整的LocalAI工作空间。通过Docker方式部署后,运行LocalAI官网提供的各种示例命令都需要在container环境中执行,比如用local-ai工具下载和运行大模型。
# 先创建一个docker volume local-ai-data2
docker run -p 8080:8080 -d --gpus all --name local-ai-2 -v local-ai-data2:/build/models -ti localai/localai:latest-aio-gpu-nvidia-cuda-12
# 如果需要拉取模型,可以进入docker环境
docker exec -ti local-ai-2 bash
Container启动时会自动运行LocalAI服务,并把服务映射到主机8080端口。之后可以通过http://localhost:8080/v1/rerank地址调用。
2)Rerankers介绍
Rerankers是Github上支持rerank模型本地化的一个开源项目,支持不同类型的rerank模型,比如transformer-based, API-based,RankGTP等。我理解transformer-based cross-encoder类型的模型是主流,所以后续采用的也是这种。我了解有限,建议参考github项目文档了解更全面的信息。
基于Embedding模型的向量库检索和基于RRF(倒数排序融合)等排序算法的BM25文本检索都可以提供文档相似度或相关性打分排序,为何还要使用reranker模型?前一篇文章中已有说明,这里不再赘述。
3)安装Reranker模型
LocalAI可以通过其Model Gallery的web portal (http://localhost:8080)安装模型。不过Gallery只提供了一个Reranker示例供安装测试,
# name 是LocalAI对外提供模型服务的模型名称
name: jina-reranker-v1-base-en
# backend 是LocalAI提供模型服务的后端模块名,必须是合法的后端模块名称
backend: rerankers
# model是真正的模型名称,LocalAI模型库中的模型名称
parameters:
model: cross-encoder
# optionally:
# type: flashrank
# diffusers:
# pipeline_type: en # to specify the english language
可以手工从LocalAI模型库下载模型,
local-ai run hermes-2-theta-llama-3-8b
# or
local-ai models install hermes-2-theta-llama-3-8b
LocalAI支持从其他模型库下载模型,比如HuggingFace,Ollama等,
# Start LocalAI with the phi-2 model
local-ai run huggingface://TheBloke/phi-2-GGUF/phi-2.Q8_0.gguf
# Install and run a model from the Ollama OCI registry
local-ai run ollama://gemma:2b
# Run a model from a configuration file
local-ai run https://gist.githubusercontent.com/.../phi-2.yaml
# Install and run a model from a standard OCI registry (e.g., Docker Hub)
local-ai run oci://localai/phi-2:latest
除了以上模型安装方式,还可以使用 Yaml配置文件安装方式,这也是推荐的方式。进入container的/build/modles/ 目录,创建一个yaml文件,如下内容,
name: bge-reranker-large
backend: rerankers
parameters:
model: BAAI/bge-reranker-large
重启container,就会自动从模型库下载 BAAI/bge-reranker-large模型,并通过LocalAI的rerankers后端模块运行起来,并对外提供模型名为 bge-reranker-large的排序模型服务。
通过RestAPI的方式调用该服务示例如下,
curl http://localhost:8080/v1/rerank \
-H "Content-Type: application/json" \
-d '{
"model": "bge-reranker-large",
"query": "Organic skincare products for sensitive skin",
"documents": [
"Eco-friendly kitchenware for modern homes",
"Biodegradable cleaning supplies for eco-conscious consumers",
"Organic cotton baby clothes for sensitive skin",
"Natural organic skincare range for sensitive skin",
"Tech gadgets for smart homes: 2024 edition",
"Sustainable gardening tools and compost solutions",
"Sensitive skin-friendly facial cleansers and toners",
"Organic food wraps and storage solutions",
"All-natural pet food for dogs with allergies",
"Yoga mats made from recycled materials"
],
"top_n": 3
}'
API调用需要提供模型名称,查询,文档列表和需要返回的得分最高的top_n(有些Reranker模型会给出所有文档的得分并排序输出全部文档)给到API接口;后续在Llamaindex或者Langchain中远程调用也是基于这个API接口。
调用API接口输出如下,可以在python中通过json反序列化之后以字典对象的方式使用,

LocalAI支持的reranker模型有英文,中英文和多语言的,比如前述示例中的 bge-reranker-large就是支持中英文的模型。Rerankers支持不同类型的排序模型,包括Jina cloud。之前有尝试部署 jina-reranker-v2-base-multilingual 本地模型,但发现Rerankers默认总是调用Jina Cloud模型,需要适当的定制化修改,才可以让它调用本地部署的多语言排序模型。因为bge也提供本地部署的多语言模型,改动rerankers源码使其支持本地Jina模型意义不大,这里不过多介绍。
4、模型远程调用
无论Ollama还是LocalAI本地化部署的大模型服务都需要考虑远程访问能力,毕竟我们不大会把所有AI应用都和本地化部署的大模型放在同一台服务器上。
通过Docker 部署的LocalAI服务,在运行时要把container的服务端口映射到主机,AI应用服务器通过该主机的主机名或IP地址访问映射端口即可访问LocalAI提供的大模型服务。
如果需要在大模型开发框架比如LlamaIndex或Langchain中调用LocalAI服务,可以直接使用框架提供的能力调用 文本生成和嵌入类型的模型服务,但是却没有找到调用Reranker服务的接口或示例。经过一点儿研究,发现可以参考JinaRerank接口,做适当修改即可(前一篇文章中copy错了代码,这里提供一下)。示例如下,
# LocalAI 本地化部署的URL, 例如: http://172.16.100.100:8080/v1/rerank/
API_URL = settings.RERANKER_HOST_URL
# 可以修改代码直接从传输到服务的数据中去掉也可以,简单点儿使用一个fake Key
API_KEY = "sk_test_1234567890"
dispatcher = get_dispatcher(__name__)
class LocalAIRerank(BaseNodePostprocessor):
api_url: str = Field(default=API_URL, description="The URL to call for reranking.")
api_key: str = Field(
default=None, description="Copied from Jina class. Will be ignored here."
)
model: str = Field(
default=RerankLocalModels.BGE_RERANKER_LARGE,
description="The model to use when calling Local AI Reranking API",
)
top_n: int = Field(description="Top N nodes to return.")
# 这里增加一个得分阈值,可以去掉相关性得分低于阈值的文档记录,在 _postprocess_nodes 函数中用一个列表推导式进行过滤即可
score_threshold: float = Field(description="The score threshold to filter nodes")
_session: Any = PrivateAttr()
def __init__(
self,
top_n: int = 4,
model: str = RerankLocalModels.BGE_RERANKER_LARGE,
api_url: Optional[str] = API_URL,
api_key: Optional[str] = None,
score_threshold: float = 0.0,
):
super().__init__(top_n=top_n, model=model, score_threshold=score_threshold)
self.api_url = api_url or API_URL
self.api_key = api_key or API_KEY
self.model = model
self.score_threshold = score_threshold
self._session = requests.Session()
self._session.headers.update(
{
"Authorization": f"Bearer {self.api_key}",
"Accept-Encoding": "identity",
"Content-Type": "application/json",
}
)
# _postprocess_nodes 方法处理从LocalAI服务返回的数据,直接抄JinaRerank类的代码即可
# 全部代码较多,这里就只提供增加的得分过滤部分
def _postprocess_nodes(
self,
nodes: List[NodeWithScore],
query_bundle: Optional[QueryBundle] = None,
) -> List[NodeWithScore]:
...
new_nodes = [
node for node in new_nodes if node.score > self.score_threshold
]
new_nodes = new_nodes[: self.top_n]
...
Ollama默认通过 11434端口提供服务,比如本地访问http://localhost:11434。对于Ollama提供的文本生成或Embedding嵌入模型,Llamaindex和Langchain开发框架都提供完备的调用方法,比如Llamaindex中,
from llama_index.llms.ollama import Ollama
from llama_index.embeddings.ollama import OllamaEmbedding
llm = Ollama(
base_url=settings.OLLAMA_HOST_URL,
model=LLMLocalModels.QWEN2_7B,
temperature=self.temperature,
)
embed_model = OllamaEmbedding(
base_url=settings.OLLAMA_HOST_URL,
model_name=EmbedLocalModels.GTE_QWEN2_1D5B,
)
这里需要说明一点儿,Ollama的Daemon服务安装到系统后,默认只允许通过localhost/127.0.0.1回环地址访问。配置远程服务能力,需要增加一个OLLAMA_HOST的环境变量,设置为0.0.0.0:11434,使主机上所有IP地址的11434端口都可以响应请求,提供服务。
另外,如果在Ollama运行的主机上用Docker方式部署了Dify或者OpenWebUI等大模型应用框架,需要连接本机部署的Ollama服务时,不能使用http://localhost:11434这个地址。因为这里localhost会被当成Dify/OpenWebUI的container自身,而不是Ollama所在的主机。因此这里需要使用http://host.docker.internal:11434,其中host.docker.internal DNS名是docker新版本好像0.22之后增加的一个特性,该特性默认在创建的container中添加本地DNS解析(/etc/hosts)并指向Docker网络的网关地址,这个网关地址在主机和container层面都是可见的,用来桥接主机和container;或者也可以在Dify/OpenWebUI的portal中直接配置Ollama所在主机的主机名或网络地址URL,比如http://<hostname/IP>:11434。
如何学习大模型?
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

5. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方CSDN官方认证二维码,免费领取【
保证100%免费】
















 5861
5861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









