







1、间隔与支持向量
(1)分类学习的最基本思想就是:基于训练集D在样本空间中找到一个划分超平面,将不同类别的样本分开。
(2)在样本空间中,用线性方程来表示划分超平面:ωTx + b = 0 ;其中ω = (ω1;ω2; … ; ωd)为法向量,决定超平面内的方向;b为位移项,决定超平面与原点之间的距离。
则样本空间中任意点x到超平面的距离为:
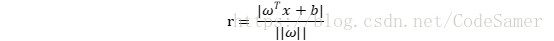
假设超平面(ω, b)能够正确分类样本,即对(xi , yi) ∈D,若yi = +1,有ωTxi + b >0 ;若 yi = -1,有ωTxi+ b < 0. 令:
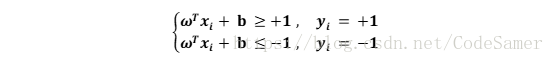
距离超平面最近的几个训练样本点使上式成立,它们被称为支持向量(support vector),两个异类支持向量到超平面的距离之和(也成为间隔 margin)为:
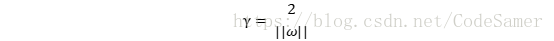
想要找到最大间隔(maximum margin)的划分超平面,也就是找使γ最大时满足的约束参数ω和b;也就是要最大化 ‖ω‖-1,等价于最小化‖ω‖2 。
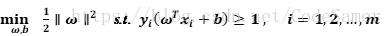
这就是支持向量机(Support VectorMachine,简称SVM)的基本型。
【注:这里是因为yi和 (ωTxi + b) 始终是同号的,且|ωTxi+ b|≥1】
2、对偶问题(dual problem)
(1)使用拉格朗日乘子法得到SVM的对偶问题,对式中每条约束添加拉格朗日乘子αi ≥0,则拉格朗日函数为:
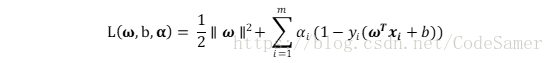
对变量ω和b求偏导得:

代入L(ω, b, α) 得:
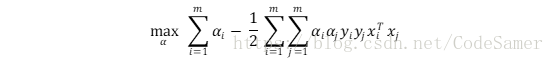

解出α后代入求出ω, b得:
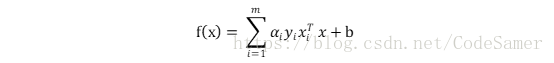
上式需满足KKT条件,即:

若αi = 0,则样本不会对f(x)产生影响;若αi>0,则必有yif(xi) = 1,对应的样本点位于最大间隔边界,是一个支持向量;这表明SVM的一个重要性质:训练完成后,大部分训练样本不需要保留,最终模型仅与支持向量有关。
(2)SMO算法:先固定αi之外的所有参数,然后求αi上的极值。SMO每次选取两个变量αi和αj ,不断执行如下两个步骤直至收敛:
① 选取一对需更新的变量αi和αj ;
② 固定αi和αj以外的参数,求解化简式获得更新后的αi和αj。
SMO先选取违背KKT条件程度最大的变量,在选取第二个变量时,使选取的两变量所对应样本之间的间隔最大。
3、核函数
(1)如果不存在可以正确划分两类样本的超平面,我们可将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。
【注:如果原始空间是有限维,即属性数有限,那么一定存在一个高位特征空间使样本可分。】
(2)令φ(x)表示将x映射后的特征向量,则之前的式子可等价为:
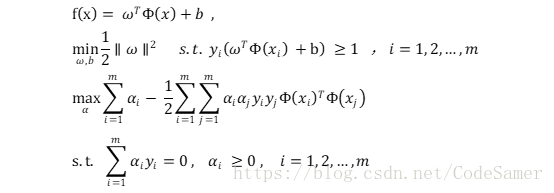
此时涉及到计算φ(xi)Tφ(xj) 较为复杂,需要用到核函数(kernelfunction) —k( , ):
k(xi, xj) = <φ(xi), φ(xj)> = φ(xi)Tφ(xj)
(3)只要一个对称函数所对应的核矩阵是半正定的,它就能作为核函数使用;常用的核函数有:

(4)正则化可理解为一种“罚函数法”,即对不希望得到的结果施以惩罚,从而使得优化过程趋向于希望的目标。
4、软间隔与正则化
(1)现实中由于大多数样本不是线性可分的,所以引入软间隔(softmargin),也就是允许支持向量机在一些样本上出错。
(2)此时优化目标可写为:
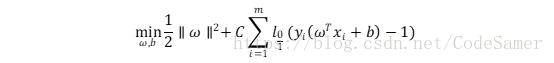
l0/1表示“0/1损失函数”:
由于l0/1的数学特性不太好,常用一些函数替代l0/1,称为替代函数;通常是凸函数且是l0/1的上届,常见的有hinge损失、指数损失、对率损失。
(3)支持向量机和对率回归的优化目标接近:
①对率回归的优势在于其输出具有自然的概率意义,即在给出预测标记的同时也给出了概率;而支持向量机的输出不具有概率意义。
② 对率回归能直接用于多分类任务,支持向量机需要推广。
5、支持向量回归(Support Vector Regression)
(1)SVR假设我们能容忍f(x)与y之间最多有ε的偏差,即晋档f(x)与y之间的差别绝对值大于ε时才计算损失;相当于以f(x)为中心构建一个宽度为2ε的间隔带。
(2)SVR问题形式化为:
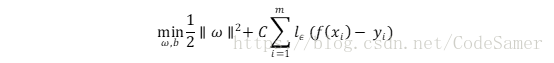
其中C为正则化常数,lε是ε-不敏感损失函数:
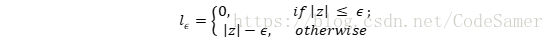
最终SVR的解为:
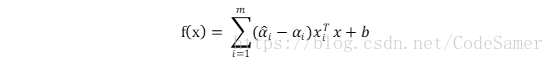
能使上式中(αi’- αi)≠0的样本记为SVR的支持向量。
6、核方法(kernel method)
(1)表示定理(representer theorem)
(2)现实中,常通过“核化”(即引入核函数)来将线性学习器拓展为非线性学习器。
(3)支持向量机是针对二分类任务设计的,其求解通常是借助于凸优化技术,核函数直接决定了支持向量机与核方法的最终性能,替代损失函数在机器学习中被广泛应用。















 893
893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









