







图像特征检测
一般我们看到一副图像进行识别,会想到这幅图像有什么特征,边缘特征,纹理特征等等,下面介绍几种常见的特征检测算法
1 harris角点检测
在图像上取一个W*W的“滑动窗口”,不断的移动这个窗口并检测窗口中的像素变化情况E。像素变化情况E可简单分为以下三种:A 如果在窗口中的图像是什么平坦的,那么E的变化不大。B 如果在窗口中的图像是一条边,那么在沿这条边滑动时E变化不大,而在沿垂直于这条边的方向滑动窗口时,E的变化会很大。 C 如果在窗口中的图像是一个角点时,窗口沿任何方向移动E的值都会发生很大变化。
算法基本思想是使用一个固定窗口在图像上进行任意方向上的滑动,比较滑动前与滑动后两种情况,窗口中的像素灰度变化程度,如果存在任意方向上的滑动,都有着较大灰度变化,那么我们可以认为该窗口中存在角点。
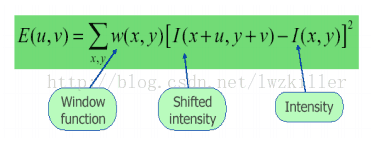
[u.v]是窗口偏移量,(x,y)是像素坐标位置。窗口有多大,就有多少个位置。opencv有自带API .
void cornerHarris(
InputArray src,//输入图像,单通道8位或浮点图像
OutputArray dst,//输出图像类型CV_32FC1,大小同原图像
int blockSize,//邻域的大小
int ksize,//Sobel算子的孔径大小
double k,//Harris参数
int borderType = BORDER_DEFAULT);//边界模式2 haar,lbp特征
在提取特征可以先用直方图均衡化提高下对比度,因为这两个特征就是利用差值。
其主要思想就是用haar模板在图像上滑动,模板中白色像素值减去黑色像素值,得到特征值,反应了图像的灰度变化,例如,眼睛的颜色要比脸颊颜色深,使用积分图可以快速计算特征值。一般结合adaboost构成级联分类器使用,步骤如下:
提取特征值--使用adaboost算法更好的选择矩形特征的组合组成分类器--以决策树的方式存储分类器-以级联的方式构造组成级联分类器
以上每一步骤,opencv都有自带的接口。还有训练好的分类器供用户使用。
3 hog特征
图像的的表象和形状能够被像素的梯度表示。主要用于行人检测。也有自带的API,一般结合SVM分类器使用。
图像的旋转
分为两种情况,第一种吧一副图片本来是正正方方的(从正上方拍摄),你想变正,可以使用透视,任意角度。其思路如下
二值化--形态学操作(更好的提取轮廓)--找轮廓--过滤轮廓--找直线(霍夫变换)--找到四条直线交叉点(利用y=kx+c)--以这四个点透视变化。
CvMat* cvGetPerspectiveTransform( const CvPoint2D32f*src, const CvPoint2D32f* dst, CvMat*map_matrix );
src 输入图像的四边形顶点坐标。
dst 输出图像的相应的四边形顶点坐标。
map_matrix 指向3×3输出矩阵的指针。
对图像进行透视变换
void cvWarpPerspective( const CvArr* src, CvArr* dst,const CvMat* map_matrix, int flags=CV_INTER_LINEAR+CV_WARP_FILL_OUTLIERS,CvScalar fillval=cvScalarAll(0) );
src 输入图像.
dst 输出图像.
map_matrix 3×3 变换矩阵
flags 插值方法和以下开关选项的组合: CV_WARP_FILL_OUTLIERS- 填充所有缩小图像的象素。如果部分象素落在输入图像的边界外,那么它们的值设定为 fillval.
CV_WARP_INVERSE_MAP- 指定 matrix 是输出图像到输入图像的反变换,因此可以直接用来做象素插值。否则, 函数从 map_matrix 得到反变换
//使用案例
vector<Point2f> src_corners(4);
src_corners[0] = p1;
src_corners[1] = p2;
src_corners[2] = p3;
src_corners[3] = p4;
vector<Point2f> dst_corners(4);
dst_corners[0] = Point(0, 0);
dst_corners[1] = Point(width, 0);
dst_corners[2] = Point(0, height);
dst_corners[3] = Point(width, height);
// 获取透视变换矩阵
Mat resultImage;
Mat warpmatrix = getPerspectiveTransform(src_corners, dst_corners);
warpPerspective(src, resultImage, warpmatrix, resultImage.size(), INTER_LINEAR);
namedWindow("Final Result", CV_WINDOW_AUTOSIZE);
imshow("Final Result", resultImage);还有一种图像是旋转的,可以利用一下连个API:
图像的角度src.angle
Mat getRotationMatrix2D(Point2f center, double angle, double scale)
参数详解:
Point2f center:表示旋转的中心点
double angle:表示旋转的角度
double scale:图像缩放因子
将刚刚求得的仿射变换应用到源图像
warpAffine( src, warp_dst, warp_mat, warp_dst.size() );
函数有以下参数:
src: 输入源图像
warp_dst: 输出图像
warp_mat: 仿射变换矩阵
warp_dst.size(): 输出图像的尺寸图像的分割
图像的分割就是把一副图像中不同种类的块区别来,

就是类似这种效果,分割后可以把人像抠出来,使用的算法聚类算法Kmeans聚类算法,其原理是,确定好分类数目,为每个类初始化一个中心点,对数据集合计算到中心点的距离,然后对分类好的数据集合重新计算(取均值)中心位置。在重新分类,知道达到阈值。
该算法应用到RGB图像中需要先将图像数据转到样本数据,代码如下:
//图像数据转到样本数据
int index = 0;
for (int row = 0; row < h; row++) {
for (int col = 0; col < w; col++) {
index = row*w + col;
Vec3b bgr = image.at<Vec3b>(row, col);
points.at<float>(index, 0) = static_cast<int>(bgr[0]);
points.at<float>(index, 1) = static_cast<int>(bgr[1]);
points.at<float>(index, 2) = static_cast<int>(bgr[2]);
}
}
// 运行KMeans
int numCluster = 4;
Mat labels;
Mat centers;
TermCriteria criteria = TermCriteria(TermCriteria::EPS + TermCriteria::COUNT, 10, 0.1);
kmeans(points, numCluster, labels, criteria, 3, KMEANS_PP_CENTERS, centers);
//对分类好的数据,就任你处置了,你可以替换背景,把背景变成黑色,图像变成白色
//
// 去背景+遮罩生成
Mat mask=Mat::zeros(src.size(), CV_8UC1);
int index = src.rows*2 + 2;
int cindex = labels.at<int>(index, 0);
int height = src.rows;
int width = src.cols;
//Mat dst;
//src.copyTo(dst);
for (int row = 0; row < height; row++) {
for (int col = 0; col < width; col++) {
index = row*width + col;
int label = labels.at<int>(index, 0);
if (label == cindex) { // 背景
//dst.at<Vec3b>(row, col)[0] = 0;
//dst.at<Vec3b>(row, col)[1] = 0;
//dst.at<Vec3b>(row, col)[2] = 0;
mask.at<uchar>(row, col) = 0;
} else {
mask.at<uchar>(row, col) = 255;
}
}
}
//imshow("mask", mask);关键是对图像的像素极操作要熟记。
二:图像的分割
图像分割是一种把图像中数据分类的一种办法,例如证件照,你的背景和前景颜色不一样,根据数据可以分类出来。
opencv带有三种API分割方法:Kmean,GMM,基于距离变换的分水岭,效果因图像而异,因算法而异
三:图像的跟踪
图像的跟踪也有很多方法,基于颜色,基于光流,CAMshift等等,图像跟踪的大体步骤其实不难,首先要明确被跟踪的物体具有什么特征,然后怎么去表示它,比如基于稀疏光流的方法,是要先计算图像中的上一帧harris角点特征,然后根据光流,输出图像中运动物体的角点特征。达到跟踪的目的。
其实不管分割,跟踪,都涉及到一个重要的核心,就是图像的“表示”,就是说怎么让计算机认识这个东西,肯定是用几组向量来表示,向量就是图像的特征,然后看接下来的图像是否匹配这些向量,所以关键是这个图像抽象成向量的过程需要好好钻研。















 3390
3390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









