







 本文为Java初学者提供了一套全面的Stream流学习指导,包括流的基本概念、Optional使用方法、流的创建方式及处理技巧等内容。通过实战案例演示流的过滤、排序、收集等操作。
本文为Java初学者提供了一套全面的Stream流学习指导,包括流的基本概念、Optional使用方法、流的创建方式及处理技巧等内容。通过实战案例演示流的过滤、排序、收集等操作。
本文是面向Java初学者的流(Stream)学习指导教程。文章内容偏向怎么用,而弱化其诞生背景、流的概念、内部原理等说明解释性的语段。
主要内容:
- Optional
- 创建流
- 操作流
- 收集流
目录
什么是流
背景:
- 在数组和集合中,许多操作(如遍历)依然十分复杂、代码量大。
- 为了更一步简化对集合元素的操作,引入流的概念。
Stream流能解决什么问题?
- JDK1.8中,可以解决已有集合类库或者数组API的弊端。例如,遍历迭代集合的操作很繁杂。
- Stream流简化集合和数组各种的操作!
- 需要掌握Lambda表达式的写法。
第一个Stream程序:
import java.util.List;
import java.util.ArrayList;
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
// 需求:从集合中筛选出所有姓张的人出来。然后再找出姓名长度是3的人。
// 原始实现
// a.先找出姓张的人。
//List<String> zhangLists = new ArrayList<>();
//for (String s : list) {
// if(s.startsWith("张")){
// zhangLists.add(s);
// }
//}
//System.out.println(zhangLists);
//
// b.张姓姓名长度为3的人
//List<String> zhangThreeLists = new ArrayList<>();
//for (String s : zhangLists){
// if(s.length() == 3){
// zhangThreeLists.add(s);
// }
//}
//System.out.println(zhangThreeLists);
// 流实现
list.stream().filter(s -> s.startsWith("张")).filter( s -> s.length()== 3 )
.forEach(System.out::println);
}
}
Optional
在流操作中,有些流操作后的返回值为Optional,所以这里先介绍这种类型。
对Optional的理解:
- 类似于一种数据类型,如Object、Integer、Double等。
- Optional类包装了许多用于解决null的各种方法,主要目的是解决臭名昭著的空指针异常(NullPointerException)问题。
- 它是一个可以为null的类型对象。
- Optional和流(Stream)搭配使用才能发挥它的最佳实力!
简单认识和理解Optional
问题:
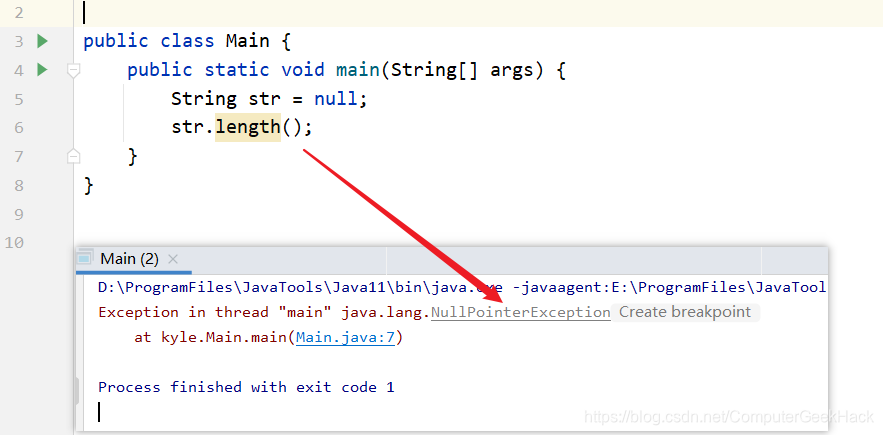
常规解决方案:
public class Main {
public static void main(String[] args) {
String str = null;
//空指针解决方案一:使用try块捕捉、处理
try {
str.length();
System.out.println("------待执行------");
} catch (NullPointerException e){
e.printStackTrace();
System.out.println("发生了空指针异常!");
}
//解决方案二:使用判断语句
if(str != null) {
str.length();
System.out.println("------待执行------");
} else {
System.out.println("str是null");
}
}
}
最佳解决方案:使用Optional申明一个可以为null的String变量
import java.util.Optional;
public class Main {
public static void main(String[] args) {
String str = null;
//Optional<String>: 一个String类型的Optional容器
Optional<String> strOpt = Optional.ofNullable(str); //把str赋值给strOpt,相当于这样:strOpt = str;
//如果strOpt不是null,则返回strOpt中的值
//如果strOpt是null,则返回orElse设置的默认值
System.out.println(strOpt.orElse("default")); //输出:default
}
}
Optional操作
创建:
- Optional<String> optStr = Optional.empty();//创建一个包装对象值为空的Optional对象
- Optional<String> optStr1 = Optional.of("值");//创建包装对象值非空的Optional对象
- Optional<String> optStr2 = Optional.ofNullable(null); //创建包装对象值允许为空的Optional对象
判断获取值:
- T get() 如果存在值,则返回该值,否则抛出 NoSuchElementException 。
- orElse 如果创建的Optional中有值存在,则返回此值,否则返回一个默认值
- orElseGet 如果创建的Optional中有值存在,则返回此值,否则返回一个由Supplier接口生成的值
- orElseThrow 如果创建的Optional中有值存在,则返回此值,否则抛出一个由指定的Supplier接口生成的异常
Optional实例:
import java.util.Optional;
public class MainTest {
public static void main(String[] args) throws Exception {
//Optional相当于是一种类型的申明器,可以申明多种类型,并且这种类型可以为null
Optional<String> op01 = Optional.empty();
Optional<String> op02 = Optional.of("aa");
Optional<String> op03 = Optional.ofNullable(null);
//get():该Optional变量存在值则返回该值,否则抛出 NoSuchElementException
System.out.println(op02.get()); //输出:aa
//orElse(other):如果创建的Optional中有值存在,则返回此值,否则返回other中的值
System.out.println(op01.orElse("默认值")); //输出:默认值
//orElseGet():如果创建的Optional中有值存在,则返回此值,否则返回一个由Supplier接口生成的值
System.out.println(op01.orElseGet(() -> "这是由Supplier生成的值"));
//如果创建的Optional中有值存在,则返回此值,否则抛出一个由指定的Supplier接口生成的异常
System.out.println(op01.orElseThrow(TempRuntime::new));
//输出:
//Exception in thread "main" kyle.TempRuntime: 自定义TempRuntime异常
//at java.base/java.util.Optional.orElseThrow(Optional.java:408)
//at kyle.MainTest.main(MainTest.java:22)
}
}
class TempRuntime extends RuntimeException {
public TempRuntime() {
super("自定义TempRuntime异常");
}
}
进行处理:
- filter 如果创建的Optional中的值满足filter中的条件,则返回包含该值的Optional对象,否则返回一个空的Optional对象
- map 如果创建的Optional中的值存在,对该值执行提供的Function函数调用
- boolean isParent 判断该Optional是否存在值
流获取(创建)
流创建的三种主要方式:
- 通过 java.util.Collection.stream() 方法用集合创建流
- 使用java.util.Arrays.stream(T[] array)方法用数组创建流
- 使用Stream的静态方法:of()、iterate()、generate()
空流
public static <T> Stream<T> empty() 空流
- java.util.Stream类
- 产生一个空的流
功能:在创建流时使用empty()方法来避免对没有元素的流返回null。
public Stream<String> streamOf(List<String> list) {
return list == null || list.isEmpty() ? Stream.empty() : list.stream();
}
集合、数组流
创建流的几种方式:
- 集合 Collection.stream()
- 静态方法 Stream.of(元素1,元素2,,,)
- 数组 Arrays.stream
基础的流获取(创建)
import java.util.Collection;
import java.util.ArrayList;
import java.util.Map;
import java.util.HashMap;
import java.util.Arrays;
import java.util.stream.Stream;
public class Main {
/*
集合获取流:集合对象.stream();
数组获取流:Arrays.stream(数组) / Stream.of(数组);
*/
public static void main(String[] args) {
/** --------------------Collection集合获取流------------------------------- */
// Collection集合如何获取Stream流。
Collection<String> c = new ArrayList<>();
Stream<String> ss = c.stream();
/** --------------------Map集合获取流------------------------------- */
Map<String, Integer> map = new HashMap<>();
// 先获取键的Stream流。
Stream<String> keyss = map.keySet().stream();
// 在获取值的Stream流
Stream<Integer> valuess = map.values().stream();
// 获取键值对的Stream流(key=value: Map.Entry<String,Integer>)
Stream<Map.Entry<String,Integer>> keyAndValues = map.entrySet().stream();
/** ---------------------数组获取流------------------------------ */
// 数组也有Stream流。
String[] arrs = new String[]{"Java", "JavaEE" ,"Spring Boot"};
Stream<String> arrsSS1 = Arrays.stream(arrs);
Stream<String> arrsSS2 = Stream.of(arrs);
}
}
生成流
- static<T> Builder<T> builder() 根据元素构建一个流
- static <T> Stream<T> generate (Supplier<? extends T> s) 生成无限流
import java.util.stream.Stream;
public class Main {
public static void main(String[] args) {
//构建流
Stream<String> streamBuilder = Stream.<String>builder().add("a").add("b").add("c").build();
//无限流
Stream<String> echo = Stream.generate(() -> "hello, kyle.");
Stream<Double> randNum = Stream.generate(Math::random).limit(10); //生成10个
streamBuilder.forEach(e -> System.out.print(e + " ")); //输出:a b c
}
}
序列流
- static <T> Stream<T> iterate(T seed, UnaryOperator<T> f) 生成序列流:接收一个种子值和一个函数。第一个值是种子的值,第二个值为f(seed),第三个值为f(f(seed)),以此类推。
- static <T> Stream<T> iterate(T seed, Predicate<? super T> hasNext, UnaryOperator<T> next) 有限序列流:参数一为种子值,参数二为生成的条件值,参数三为递增值。
import java.math.BigInteger;
import java.util.stream.Stream;
public class Main {
public static void main(String[] args) {
//序列流
Stream<BigInteger> integerStream = Stream.iterate(BigInteger.ZERO, n->n.add(BigInteger.ONE)); //无限
var limit = new BigInteger("1000");
Stream<BigInteger> integerStream1 = Stream.iterate(BigInteger.ZERO,
n->n.compareTo(limit)<0,
n->n.add(BigInteger.ONE)); //有限
integerStream1.forEach(System.out::println);
Stream<Integer> integerStream2 = Stream.iterate(40, n -> n + 2).limit(20); //有限
}
}
基本数据类型流
对于八种基本数据类型
- boolean、byte、char、short、int、String对应IntStream;
- long对应LongStream;
- float、double对应DoubleStream;
import java.util.Random;
import java.util.regex.Pattern;
import java.util.stream.DoubleStream;
import java.util.stream.IntStream;
import java.util.stream.LongStream;
import java.util.stream.Stream;
public class Main {
public static void main(String[] args) {
IntStream intStream = IntStream.range(1, 3); //以区间[参数1,参数2)构建序列流
LongStream longStream = LongStream.rangeClosed(1, 3); //以区间[参数1,参数2]构建序列流
Random random = new Random();
DoubleStream doubleStream = random.doubles(3); //构建三个元素的流
intStream.forEach(System.out::println); //输出:1 2
longStream.forEach(System.out::println); //输出:1,2,3
doubleStream.forEach(System.out::println); //输出:三个随机double数
//串与流
IntStream streamOfChars = "abc".chars();
Stream<String> streamOfString = Pattern.compile(", ").splitAsStream("a, b, c");
streamOfChars.forEach(System.out::println); //输出:97,98,99
streamOfString.forEach(System.out::println); //输出:a b c
}
}
流处理
流处理主要是对流中的元素进行一些列的操作,例如条件过滤、数据转换、去重、排序等操作。
过滤 filter
Stream<T> filter(Predicate<? super T> predicate)
- Predicate是函数式接口,可以直接用lambda代替;
- 如果有复杂的过滤逻辑,则用or、and、negate方法组合
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Stream;
public class MainTest {
public static void main(String[] args) throws Exception {
List<Integer> list = new ArrayList<>();
list.add(10);list.add(22);list.add(33);list.add(456);list.add(99);
Stream<Integer> stream = list.stream();
stream.filter(e -> e>100).forEach(e -> System.out.print(e+" ")); //筛选出ArrayList中大于100的元素
}
}
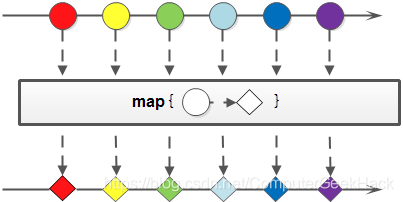
- <R> Stream<R> map(Function<? super T, ? extends R> mapper)
- IntStream mapToInt(ToIntFunction<? super T> mapper);
- LongStream mapToLong(ToLongFunction<? super T> mapper);
- DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper);
import java.util.HashSet;
import java.util.Set;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class MainTest {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("aa"); set.add("ee");
set.add("bb"); set.add("ff");
Stream<String> stream = set.stream();
Set<String> newSet = stream.map(str -> str.toUpperCase()).collect(Collectors.toSet()); //将set中的元素全部转换为大写,再回写到set中
newSet.stream().forEach(e -> System.out.print(e + " ")); //输出:AA EE BB FF
}
}
去重 distinct
Stream<T> distinct();
import java.util.Arrays;
import java.util.List;
public class MainTest {
public static void main(String[] args) {
List<Integer> demo = Arrays.asList(1, 1, 2);
demo.stream().distinct().forEach(System.out::println); //输出:1 2
}
}
排序 sorted
Stream<T> sorted();
Stream<T> sorted(Comparator<? super T> comparator);
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import java.util.stream.Collectors;
public class MainTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<>();
personList.add(new Person("aa", "woman", 22, "Shanghai",588D));
personList.add(new Person("bb", "man", 23, "Zhejiang",8820D));
personList.add(new Person("cc", "woman", 42, "Shanghai", 8889D));
personList.add(new Person("dd", "woman", 21, "Kunming", 8778D));
// 按工资升序排序(自然排序)
List<String> newList = personList.stream().sorted(Comparator.comparing(Person::getSalary)).map(Person::getName)
.collect(Collectors.toList());
// 按工资倒序排序
List<String> newList2 = personList.stream().sorted(Comparator.comparing(Person::getSalary).reversed())
.map(Person::getName).collect(Collectors.toList());
// 先按工资再按年龄升序排序
List<String> newList3 = personList.stream()
.sorted(Comparator.comparing(Person::getSalary).thenComparing(Person::getAge)).map(Person::getName)
.collect(Collectors.toList());
// 先按工资再按年龄自定义排序(降序)
List<String> newList4 = personList.stream().sorted((p1, p2) -> {
if (p1.getSalary() == p2.getSalary()) {
return p2.getAge() - p1.getAge();
} else {
double tmp = p2.getSalary() - p1.getSalary();
if(tmp>0D) {
return 1;
} else if(tmp<0D) {
return -1;
} else {
return 0;
}
}
}).map(Person::getName).collect(Collectors.toList());
System.out.println("按工资升序排序:" + newList);
System.out.println("按工资降序排序:" + newList2);
System.out.println("先按工资再按年龄升序排序:" + newList3);
System.out.println("先按工资再按年龄自定义降序排序:" + newList4);
//输出:
//按工资升序排序:[aa, dd, bb, cc]
//按工资降序排序:[cc, bb, dd, aa]
//先按工资再按年龄升序排序:[aa, dd, bb, cc]
//先按工资再按年龄自定义降序排序:[cc, bb, dd, aa]
}
}
class Person {
private String name;
private String gander;
private Integer age;
private String address;
private Double salary;
public Person(String name, String gander, Integer age, String address, Double salary) {
this.name = name;
this.gander = gander;
this.age = age;
this.address = address;
this.salary = salary;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getGander() {
return gander;
}
public void setGander(String gander) {
this.gander = gander;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public Double getSalary() {
return salary;
}
public void setSalary(Double salary) {
this.salary = salary;
}
@Override
public String toString() {
return name;
}
}
流收集
把Stream流的数据转回成集合。
Stream的作用是:把集合转换成一根传送带,借用Stream流的强大功能进行的操作。但是实际开发中数据最终的形式还是应该是集合,最终Stream流操作完毕以后还是要转换成集合。这就是收集Stream流。
Stream流:手段。
集合:才是目的。
Collectors 具体方法
- toList List 把流中元素收集到List
- toSet Set 把流中元素收集到Set
- toCollection Coolection 把流中元素收集到Collection中
- groupingBy Map<K,List> 根据K属性对流进行分组
- partitioningBy Map<boolean, List> 根据boolean值进行分组
收集到容器中
全部由Collectors工具类调用:
- public static <T> Collector<T, ?, Collection<T>> toCollection() 收集到一个集合中
- public static <T> Collector<T, ?, List<T>> toList() 流转化成List
- public static <T> Collector<T, ?, Set<T>> toSet() 流转化成Set
- public static <T> Collector<T, ?, Map<T>> toMap () 流转化成Map
- Object[] toArray(); 流转成Object数组
- <A> A[] toArray(IntFunction<A[]> generator) 流转成A[]数组,指定类型A
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Set;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
list.add("张三丰");
// 把stream流转换成Set集合。
Stream<String> zhangLists = list.stream().filter(s -> s.startsWith("张"));
Set<String> sets = zhangLists.collect(Collectors.toSet());
System.out.println(sets);
// 把stream流转换成List集合。
Stream<String> zhangLists1 = list.stream().filter(s -> s.startsWith("张"));
List<String> lists= zhangLists1.collect(Collectors.toList());
System.out.println(lists);
// 把stream流转换成数组。
Stream<String> zhangLists2 = list.stream().filter(s -> s.startsWith("张"));
Object[] arrs = zhangLists2.toArray();
// 可以借用构造器引用申明转换成的数组类型!!!
String[] arrs1 = zhangLists2.toArray(String[]::new);
// 把Stream流转换为LinkedList
List<String> resultLinkedList = list.stream()
.collect(Collectors.toCollection(LinkedList::new));
//IDEA代码优化提示:
// Can be replaced with 'java.util.LinkedList' constructor
// 优化后:List<String> resultLinkedList = new LinkedList<>(list);
}
}
收集时统计
- 计数:count
- 平均值:averagingInt、averagingLong、averagingDouble
- 最值:maxBy、minBy
- 求和:summingInt、summingLong、summingDouble
- 统计以上所有:summarizingInt、summarizingLong、summarizingDouble
import java.util.ArrayList;
import java.util.DoubleSummaryStatistics;
import java.util.List;
import java.util.Optional;
import java.util.stream.Collectors;
public class MainTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<>();
personList.add(new Person("aa","woman",22,588D));
personList.add(new Person("bb","man",23,8820D));
personList.add(new Person("cc","woman",42,8889D));
personList.add(new Person("dd","woman",21,8778D));
//计数
Long count = personList.stream().collect(Collectors.counting());
//求Person类salary属性的平均值
Double avg = personList.stream().collect(Collectors.averagingDouble(Person::getSalary));
//根据age求最小值
Optional<Integer> minAge = personList.stream().map(Person::getAge).collect(Collectors.minBy(Integer::compare));
//求age的和
Long sum = personList.stream().collect(Collectors.summingLong(Person::getAge));
//求和所有数据为double
DoubleSummaryStatistics collect = personList.stream().collect(Collectors.summarizingDouble(Person::getSalary));
System.out.println(count); //输出:4
System.out.println(avg); //输出:6768.75
System.out.println(minAge); //输出;Optional[21]
System.out.println(sum); //输出:108
System.out.println(collect); //输出:DoubleSummaryStatistics{count=4, sum=27075.000000, min=588.000000, average=6768.750000, max=8889.000000}
}
}
class Person {
private String name;
private String gander;
private Integer age;
private Double salary;
public Person(String name, String gander, Integer age, Double salary) {
this.name = name;
this.gander = gander;
this.age = age;
this.salary = salary;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getGander() {
return gander;
}
public void setGander(String gander) {
this.gander = gander;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Double getSalary() {
return salary;
}
public void setSalary(Double salary) {
this.salary = salary;
}
}
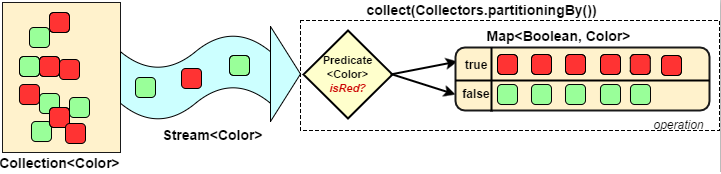
收集时分区、分组
- 分区:将stream按条件分为两个Map,比如员工按薪资是否高于8000分为两部分。
- 分组:将集合分为多个Map,比如员工按性别分组。有单级分组和多级分组。
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class MainTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<>();
personList.add(new Person("aa", "woman", 22, "Shanghai",588D));
personList.add(new Person("bb", "man", 23, "Zhejiang",8820D));
personList.add(new Person("cc", "woman", 42, "Shanghai", 8889D));
personList.add(new Person("dd", "woman", 21, "Kunming", 8778D));
// 将员工按薪资是否高于8000分组
Map<Boolean, List<Person>> part = personList.stream().collect(Collectors.partitioningBy(x -> x.getSalary() > 8000));
// 将员工按性别分组
Map<String, List<Person>> group = personList.stream().collect(Collectors.groupingBy(Person::getGander));
// 将员工先按性别分组,再按地区分组
Map<String, Map<String, List<Person>>> group2 = personList.stream().collect(Collectors.groupingBy(Person::getGander, Collectors.groupingBy(Person::getAddress)));
System.out.println("员工按薪资是否大于8000分组情况:" + part);
System.out.println("员工按性别分组情况:" + group);
System.out.println("员工按性别、地区:" + group2);
//输出:
//员工按薪资是否大于8000分组情况:{false=[aa], true=[bb, cc, dd]}
//员工按性别分组情况:{woman=[aa, cc, dd], man=[bb]}
//员工按性别、地区:{woman={Kunming=[dd], Shanghai=[aa, cc]}, man={Zhejiang=[bb]}}
}
}
class Person {
private String name;
private String gander;
private Integer age;
private String address;
private Double salary;
public Person(String name, String gander, Integer age, String address, Double salary) {
this.name = name;
this.gander = gander;
this.age = age;
this.address = address;
this.salary = salary;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getGander() {
return gander;
}
public void setGander(String gander) {
this.gander = gander;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public Double getSalary() {
return salary;
}
public void setSalary(Double salary) {
this.salary = salary;
}
@Override
public String toString() {
return name;
}
}
收集时接合
joining可以将stream中的元素用特定的连接符(没有的话,则直接连接)连接成一个字符串
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
public class MainTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<>();
personList.add(new Person("aa", "woman", 22, "Shanghai",588D));
personList.add(new Person("bb", "man", 23, "Zhejiang",8820D));
personList.add(new Person("cc", "woman", 42, "Shanghai", 8889D));
personList.add(new Person("dd", "woman", 21, "Kunming", 8778D));
String names = personList.stream().map(person -> person.getName()).collect(Collectors.joining(", "));
System.out.println(names); //输出:aa, bb, cc, dd
}
}
class Person {
private String name;
private String gander;
private Integer age;
private String address;
private Double salary;
public Person(String name, String gander, Integer age, String address, Double salary) {
this.name = name;
this.gander = gander;
this.age = age;
this.address = address;
this.salary = salary;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getGander() {
return gander;
}
public void setGander(String gander) {
this.gander = gander;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public Double getSalary() {
return salary;
}
public void setSalary(Double salary) {
this.salary = salary;
}
@Override
public String toString() {
return name;
}
}
收集时归约(reducing)
Collectors类提供的reducing方法,相比于stream本身的reduce方法,增加了对自定义归约的支持。
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
public class MainTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<>();
personList.add(new Person("aa", "woman", 22, "Shanghai",588D));
personList.add(new Person("bb", "man", 23, "Zhejiang",8820D));
personList.add(new Person("cc", "woman", 42, "Shanghai", 8889D));
personList.add(new Person("dd", "woman", 21, "Kunming", 8778D));
Optional<Double> sum2 = personList.stream().map(person -> person.getSalary()).reduce(Double::sum);
System.out.println("员工薪资总和:" + sum2.get()); //输出:员工薪资总和:27075.0
}
}
class Person {
private String name;
private String gander;
private Integer age;
private String address;
private Double salary;
public Person(String name, String gander, Integer age, String address, Double salary) {
this.name = name;
this.gander = gander;
this.age = age;
this.address = address;
this.salary = salary;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getGander() {
return gander;
}
public void setGander(String gander) {
this.gander = gander;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public Double getSalary() {
return salary;
}
public void setSalary(Double salary) {
this.salary = salary;
}
@Override
public String toString() {
return name;
}
}
流终止
什么是流终止:
- 就像是一根水管一样,流获取对应水管的开头,流处理在水管的中间段,流终止在水管的结尾处。
- 流终止一般的操作有:遍历、聚合、查找、匹配、规约。
一旦Stream调用了终结方法,流的操作就全部终结了,不能继续使用,只能创建新的Stream操作。
遍历forEach
- void forEach(Consumer<? super T> action); 顺序遍历
- void forEachOrdered(Consumer<? super T> action); 遍历,和forEach的区别是forEachOrdered在多线程parallelStream执行,其顺序也不会乱
import java.util.Arrays;
import java.util.List;
public class MainTest {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 1, 2);
list.stream().forEach(e -> System.out.print(e+" ")); //输出:1 1 2
}
}
聚合min/max/count
- Optional<T> min(Comparator<? super T> comparator) 获取最小值,Comparator用于指定比较器
- Optional<T> max(Comparator<? super T> comparator) 获取最大值
- long count() 返回流中的数量
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import java.util.Optional;
public class MainTest {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(100);list.add(222);list.add(35432);
list.add(234);list.add(34);list.add(89);
//传入比较器的原始写法
Optional<Integer> max = list.stream().max(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1.compareTo(o2);
}
});
System.out.println(max);
//传入比较器的简化写法
Optional<Integer> min01 = list.stream().min(Comparator.reverseOrder());
//Optional<Integer> min01 = list.stream().min((Integer a, Integer b) -> b.compareTo(a)); //传入比较器的Lambda写法
Optional<Integer> min02 = list.stream().min(Integer::compareTo); //自然排序、字典排序(Lambda写法)
System.out.println(min01+" "+min02);
long count = list.stream().count(); //返回数量
System.out.println(count);
}
}
查找匹配find/match
匹配:
- boolean anyMatch(Predicate<? super T> predicate) 任意一个匹配
- boolean allMatch(Predicate<? super T> predicate) 全部匹配
- boolean noneMatch(Predicate<? super T> predicate) 不匹配
搜索查找:
- 在集合中的搜索意味着根据一个条件查找元素或验证元素的存在性,这个条件也叫做谓词或断言。搜索元素可能有返回值,也可能没有,所以接口返回的是一个Optional;验证元素存在性时返回是的一个布尔值。
- Optional<T> findFirst(); 查找第一个
- Optional<T> findAny(); 任意一个
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
public class MainTest {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
list.add("张三丰");
Optional<String> op01 = list.stream().findFirst(); //获取第一个数
Optional<String> op02 = list.parallelStream().findAny(); //获取任意一个数
System.out.println(op01);
System.out.println(op02);
//常规迭代、判断
//for (String string : list) {
// if (string.contains("a")) {
// System.out.println("YES");
// }
//}
boolean isExist = list.stream().anyMatch(element -> element.contains("赵敏")); //流判断
System.out.println("是否包含:"+isExist);
//输出:
//Optional[张无忌]
//Optional[张强]
//是否包含:true
}
}
规约reduce
归约,也称缩减,顾名思义,是把一个流缩减成一个值,能实现对集合求和、求乘积和求最值操作。

操作API:
- Optional<T> reduce(BinaryOperator<T> accumulator) 两两合并
- T reduce(T identity, BinaryOperator<T> accumulator) 两两合并,带初始值的
- <U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner) 先转化元素类型再两两合并,带初始值的
import java.util.Arrays;
import java.util.List;
import java.util.Optional;
public class MainTest {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 3, 2, 8, 11, 4);
Optional<Integer> sum = list.stream().reduce((x, y) -> x + y); // 求和方式1
Optional<Integer> sum2 = list.stream().reduce(Integer::sum); // 求和方式2
Integer sum3 = list.stream().reduce(0, Integer::sum);// 求和方式3
Optional<Integer> product = list.stream().reduce((x, y) -> x * y);// 求乘积
Optional<Integer> max = list.stream().reduce((x, y) -> x > y ? x : y);// 求最大值方式1
Integer max2 = list.stream().reduce(1, Integer::max);// 求最大值写法2
System.out.println("list求和:" + sum.get() + "," + sum2.get() + "," + sum3);
System.out.println("list求积:" + product.get());
System.out.println("list求和:" + max.get() + "," + max2);
}
}
总结:
- 流的基本概念
- Optional
- 获取流:空流、从集合与数组中获取流、生成流、序列流、基本数据类型流
- 流处理:过滤、元素变换、去重、排序等
- 流收集:收集到不同类型的容器中,收集时统计、分组、接合、规约
- 流终止:遍历、聚合、查找、匹配、规约

















 660
660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









