








目录
一、传统Q学习的局限性
1.1 维度灾难实例分析
# Ms. Pac-Man状态空间估算
num_pellets = 150
possible_states = 2 ** num_pellets # 约1.4e45
print(f"理论状态空间大小: {possible_states:.1e}")传统Q表存储需求
| 状态数 | 动作数 | 存储空间(32位浮点) |
|---|---|---|
| 1e6 | 4 | 16 MB |
| 1e45 | 4 | 3.6e39 TB |
二、深度Q网络(DQN)核心突破
2.1 神经网络架构设计
def build_dqn(input_shape, action_dim):
model = tf.keras.Sequential([
layers.Dense(64, activation='relu', input_shape=input_shape),
layers.LayerNormalization(),
layers.Dense(64, activation='relu'),
layers.Dropout(0.2),
layers.Dense(action_dim)
])
return model2.2 关键技术革新
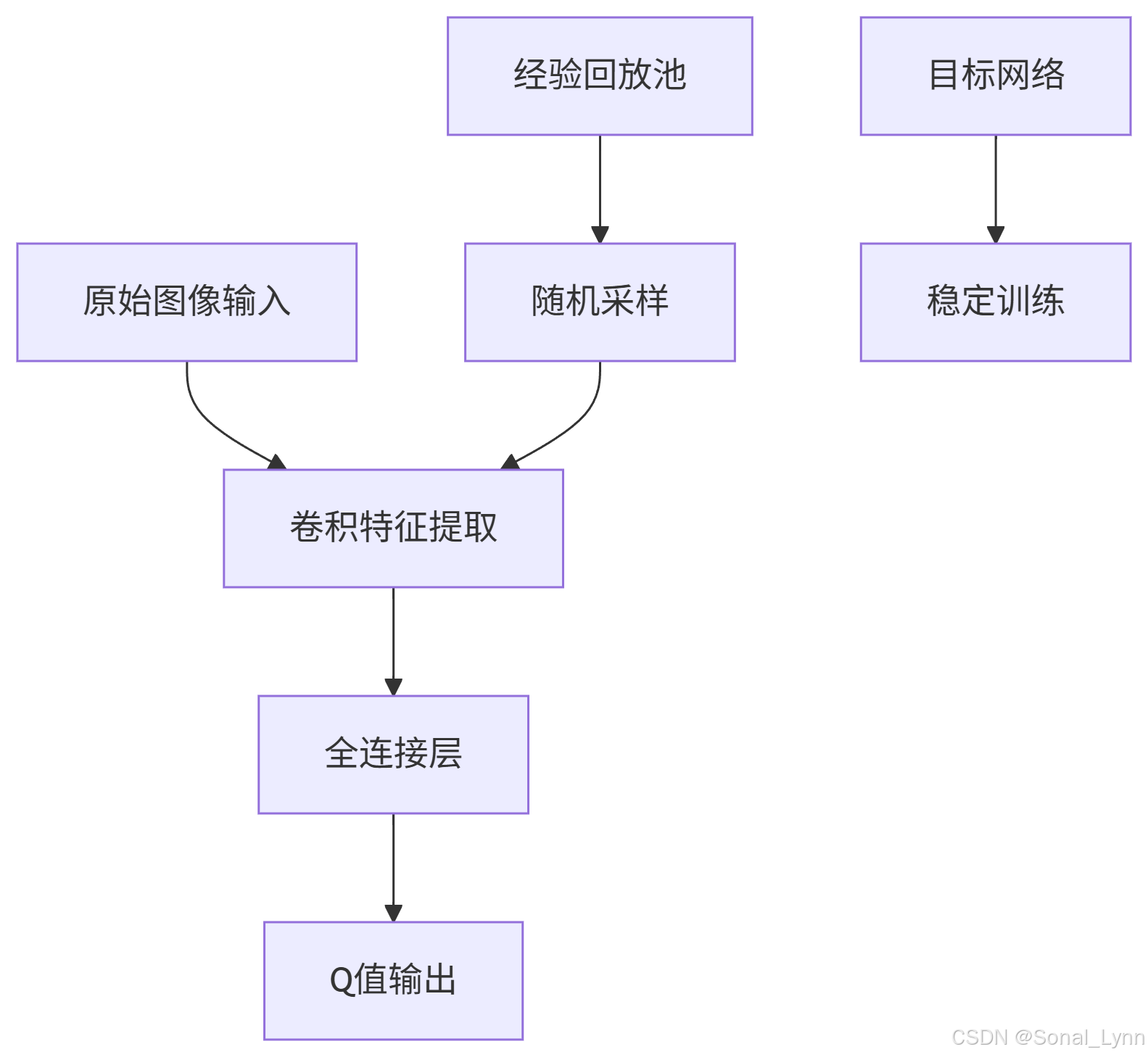
三、DQN核心组件实现
3.1 经验回放机制
class ReplayBuffer:
def __init__(self, capacity=10000):
self.buffer = deque(maxlen=capacity)
def add(self, state, action, reward, next_state, done):
self.buffer.append( (state, action, reward, next_state, done) )
def sample(self, batch_size):
indices = np.random.choice(len(self.buffer), batch_size)
return [self.buffer[i] for i in indices]3.2 目标网络更新策略
class DQNAgent:
def __init__(self, state_dim, action_dim):
self.model = build_dqn(state_dim, action_dim)
self.target_model = tf.keras.models.clone_model(self.model)
self.update_target_network()
def update_target_network(self):
self.target_model.set_weights(self.model.get_weights())四、CartPole环境训练实战
4.1 训练流程代码
def train_dqn(env, episodes=500, batch_size=64, gamma=0.95):
agent = DQNAgent(env.observation_space.shape[0], env.action_space.n)
buffer = ReplayBuffer()
epsilon = 1.0
rewards_history = []
for ep in range(episodes):
state = env.reset()
total_reward = 0
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











