







文字印刷媒介作为目前存贮、传播、交换信息和传播文化的主要途径之一,检测、控制和评价文字的印刷质量是企业生产和管理工作中重要的环节。影响文字印刷质量评价结果的因素很多,如墨色密度、反差清晰、有无断笔漏画等,且一直以来,对于这些指标的评价都是采用人眼视觉来进行的。这样的检测方式已经不能满足人们对效率及质量的要求,技术更新以待解决。在这种状况下,引进机器视觉技术、图像处理模式识别等手段,对文字印刷质量进行检测和评价,可以极大的解决这一问题。
基于机器视觉系统,可以对文字进行识别检测,例如文字印刷检测、字符检测、喷码文字缺陷检测等,Coovally针对文字检测做到了高精度和低成本,且仅需5步就可以完成一个模型!
下面就是Coovally文字检测的详细步骤:
说明:当前Coovally文字检测任务仅支持Icdar格式数据集,请提前按要求准备好数据集,具体数据集要求可参考Icdar格式数据集说明。
ICDAR数据集格式说明
ICDAR(International Conference on Document Analysis and Recognition)数据集官方地址,目前ICDAR包含的格式由ICDAR2013、ICDAR2015、ICDAR2017。
·ICDAR 2013 包含聚焦场景文本的229个训练图像和233个测试图像。它继承了ICDAR 2003数据集的大部分样本。他们都是真实世界的图像,显示标志牌、书籍、海报或其他物品上的文字。文字都是英文的且水平对齐。标注是轴对齐的边界框,共划分出1015个裁剪的单词图像。该数据集被广泛用于测试文本探测器的性能,通常被称为ICDAR 2013。
ICDAR 2013格式如下:

标注格式:xmin, ymin, xmax, ymax, text-
举例:38, 43, 920, 215, “Tiredness”
·ICDAR2015包含1,000个训练图像和500个测试图像。这些图像是使用谷歌眼镜获得的,没有考虑视角、位置或图像质量。文本实显示方向随意、也可能尺寸很小或低分辨率,使其比ICDAR 2013更加难以识别。完整的数据集有7,548个带有四边形形式标注的文本实例。它通常用于基准测试,现在称作ICDAR 2015。
ICDAR 2015格式如下:

标注格式:x1,y1,x2,y2,x3,y3,x4,y4,text 其中,x1,y1为左上角坐标,x2,y2为右上角坐标,x3,y3为右下角坐标,x4,y4为左下角坐标。
举例:(### 表示文字无法辨认)
377,117,463,117,465,130,378,130,Genaxis Theatre
374,155,409,155,409,170,374,170,###
ICDAR 当有字符但是模糊看不到时标签为###,ICDAR2013的标签中包含5列,前4列为矩形的左上和右下坐标,第5列为字符的内容。ICDAR2015用了平行四边形表示,因此包含了4个点的坐标,按顺时针方向摆放,第9列为字符内容。
·ICDAR 2017 MLT5旨在对多语言场景下的文本检测和识别任务进行基准测试。它包含7,200个训练自然场景图像、1,800个验证自然场景图像和9,000个测试自然场景图像,包含6种不同语言的文本(拉丁语、阿拉伯语、孟加拉语、韩语、平假名、片假名和符号)。标注以四边形、语言类别和转录(UTF-8文本)的形式提供。
Coovally当前支持ICDAR2015格式的数据集,但在模型训练时需要先将ICDAR2015转成COCO格式。
1. 数据上传
1.1 图片上传
图片数据准备
目前Coovally支持单独上传zip格式图片文件,待数据集创建成功之后,在数据集详情页再单独上传zip格式标签文件。
图片数据上传
登录Coovally点击侧边导航栏并下拉菜单点击【创建数据集】。
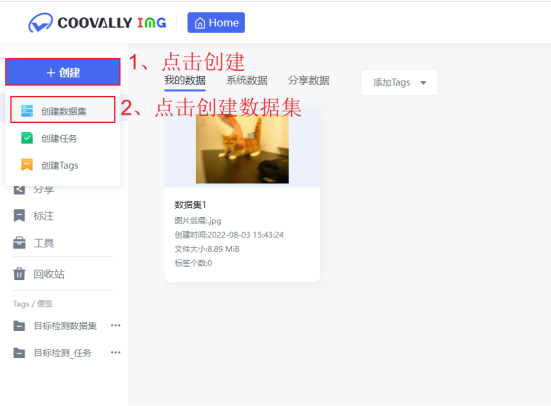
点击【创建数据集】,按要求填写参数,并将此前准备好的图片压缩包拖至文件上传区域,点击【确定】,等待图片数据上传并解析完成即可;
注意:需记住所填写的数据集名称,在创建标签时,根据数据集名称找到对应的数据集。
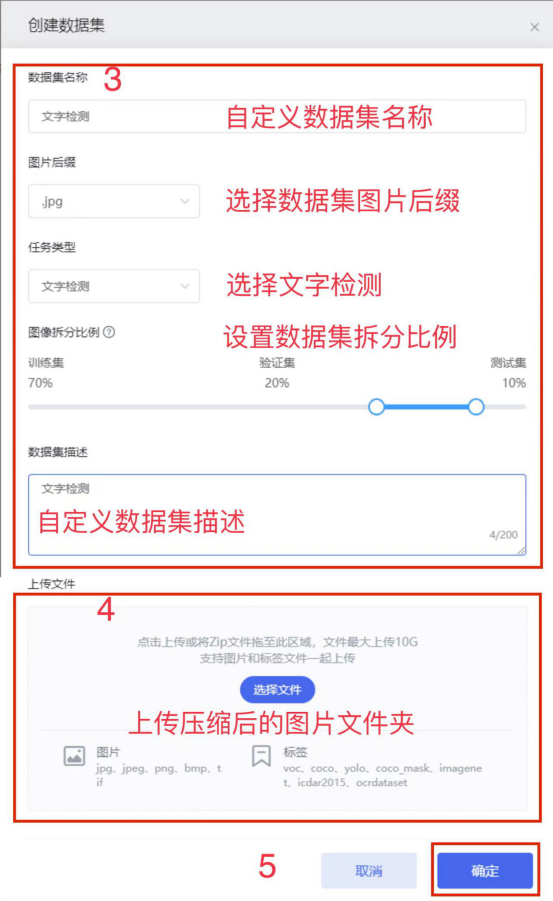
1.2 标签上传
标签数据准备
将数据中的标签文件所在文件夹压缩为zip格式的压缩包。
标签数据上传
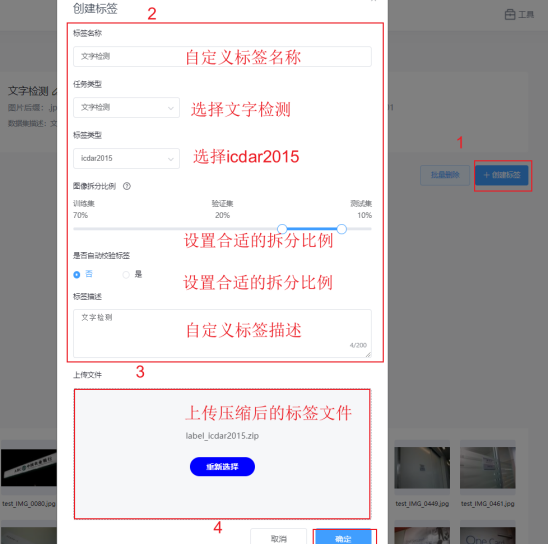
在【我的数据】标签页,找到刚刚上传的图片数据;点击图标进入数据集信息页,点击【创建标签】,再按要求填写参数,将标签压缩包拖到文件上传区域,最后点击【确定】,等待完成解析即可。
2 模型训练
2.1 数据建模
基于此前已完成上传的数据集,进行数据建模,点击【数据建模】图标,进入数据建模详情页面。

2.2 模型选择&配置参数
按要求选择模型填写模型参数;并设置训练运行参数。
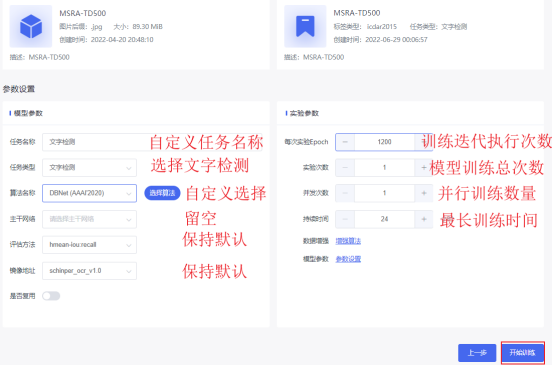
参数设置(非必须步骤)
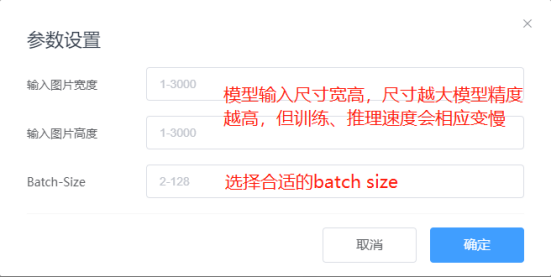
点击【参数设置】进入超参数设置页面,设置合适的超参数值,以提高模型精度或训练模型的速度。
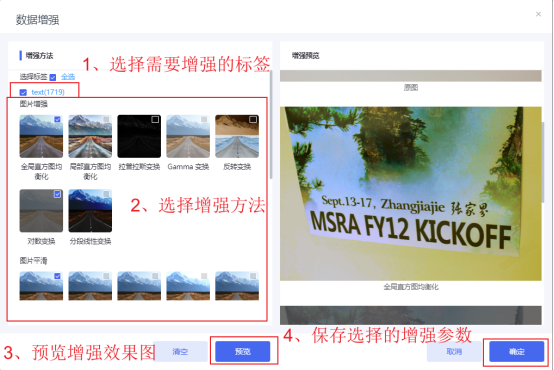
点击【增强算法】进入算法增强页面,筛选所需要增强的标签类型及数据增强方法,进行数据增强,此操作非必选操作,但当数据量较少或数据不均衡时可尝试进行数据增强,以提高模型精度。
2.3 模型训练
点击【开始训练】,即可开始模型训练,待模型训练结束即可开始此后的模型转换、部署、预测等操作。
3 模型转换
说明:此处仅为模型转化步骤示例,详细信息可参考Coovally官网文档。
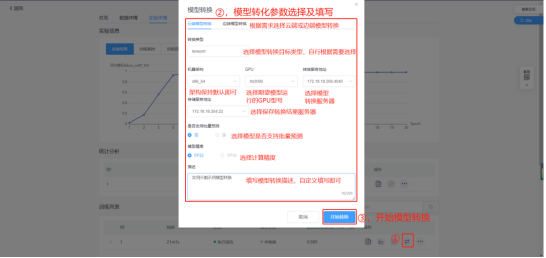
点击【模型转换】,进入模型转换页面,按要求选择及填写参数,点击开始转换即可开始进行模型转化,等待模型转化完成即可。
注意:等待模型转换期间,切勿刷新页面!
4 模型部署
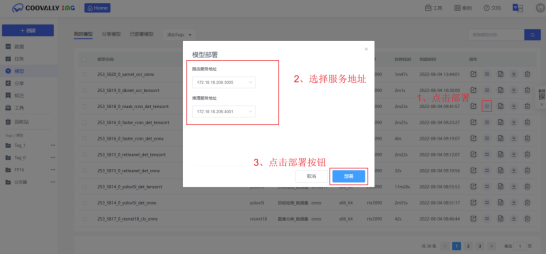
在模型转化完成后转跳的界面点击点击【模型部署】,开始模型部署。按要求选择服务地址,再点击部署按钮,等待部署完成。
5 模型预测
在模型部署完成后转跳的界面,点击【上传图片】按要求上传图片,系统即可对此图片进行模型预测,预测结果会直接显示在右侧的识别结果栏内。
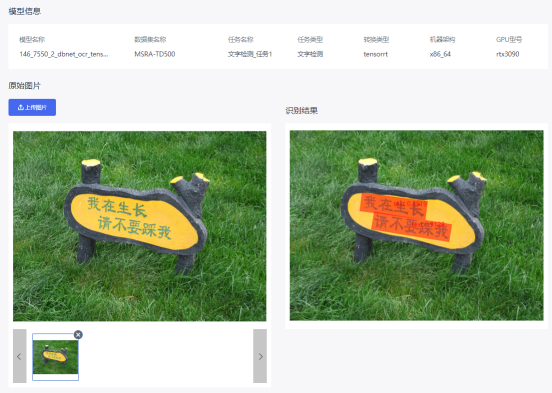
以上就是Coovally文字检测任务的详细步骤。目前,机器视觉文字检测技术广泛应用于工厂产品检测,大大提高了尺寸测量、外观缺陷检测、字符识别和定位等生产的自动化程度,有需要的小伙伴们快来试试吧~
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









