






学习目标:
- 朴素贝叶斯算法
- 决策树算法
- 随机森林算法
学习内容:
- 朴素贝叶斯算法:导入预估器
from sklearn.naive_bayes import MultinomialNBdef nb_news(): #朴素贝叶斯算法:优点:有稳定的分类效率;对数据不敏感,常用于文本分类。缺点:由于使用了样本独立的假设,所以当特征有关联时效果不好 news = fetch_20newsgroups(subset="all") x_train, x_text, y_train, y_text = train_test_split(news.data, news.target) transfer = TfidfVectorizer() x_train = transfer.fit_transform(x_train) x_text = transfer.transform(x_text) estimator = MultinomialNB() estimator.fit(x_train, y_train) # 模型评估 y_predict = estimator.predict(x_text) print("y_predict:\n", y_predict) print("直接比对真实值和预测值:\n", y_text == y_predict) score = estimator.score(x_text, y_text) print("准确率为:\n", score)朴素:表示特征值之间相互独立。贝叶斯:概率计算公式。
优点:有稳定的分类效率;对数据不敏感,常用于文本分类。缺点:由于使用了样本独立的假设,所以当特征有关联时效果不好
- 决策树算法:
from sklearn.tree import DecisionTreeClassifier,export_graphvizdef tree():#决策树:优点:简单的理解,可视化好。缺点:过于复杂的树会发生过拟合。改进:随机森林 iris = datasets.load_iris() x = iris.data y = iris.target x_train, x_text, y_train, y_test = train_test_split(x, y, random_state=22) # 标准化,决策树不需要标准化 estimator = DecisionTreeClassifier(criterion="entropy") estimator.fit(x_train, y_train) # 模型评估 y_predict = estimator.predict(x_text) print("y_predict:\n", y_predict) print("直接比对真实值和预测值:\n", y_test == y_predict) score = estimator.score(x_text, y_test) print("准确率为:\n", score) # 决策树可视化 export_graphviz(estimator, out_file="iris_tree.dot", feature_names=iris.feature_names)决策树:通过计算信息熵,信息增量。找到具有影响因素最高的特征,并由影响因素从高到低建立树型模型。决策树可视化能够形象的展示出树
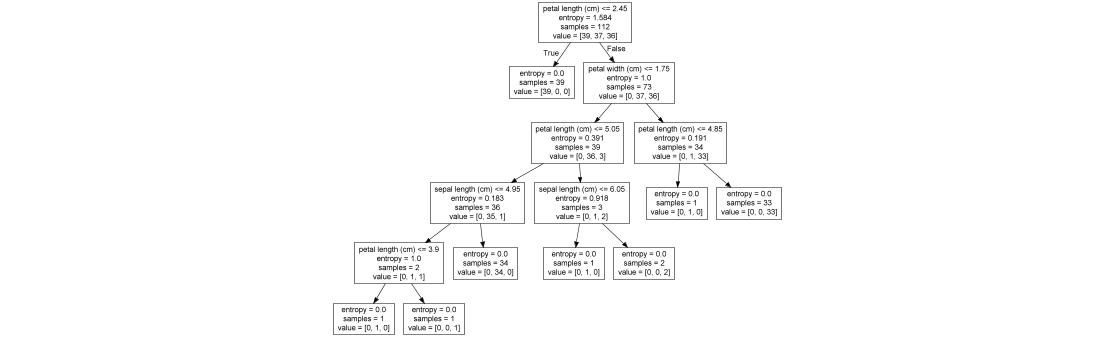
- 随机森林:引入预估器
from sklearn.ensemble import RandomForestClassifier随机:表示特征选取是随机的,树的棵数是可以选择的
森林:很多棵决策树,
随机森林算法是在众多多棵决策树当中找到最“聪明”的一棵。所以优点是准确率很高,并且处理高维样本不需要降维。同时缺点是运行时间长,因为是多棵决策树。
def random_forset(): #随机森林算法:具有极好的准确率,处理高维的样本,且不需要降维
iris = datasets.load_iris()
x = iris.data
y = iris.target
x_train, x_text, y_train, y_test = train_test_split(x, y, random_state=22)
estimator = RandomForestClassifier(n_estimators=4)#n_estimators=4,树的棵树
estimator.fit(x_train, y_train)
# 模型评估
y_predict = estimator.predict(x_text)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
score = estimator.score(x_text, y_test)
print("准确率为:\n", score)















 9898
9898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











