






1.进入需要爬取的网页
首先我们进入某耀的官方网站,点英雄资料进入界面
然后按F12按键进入页面的代码页数
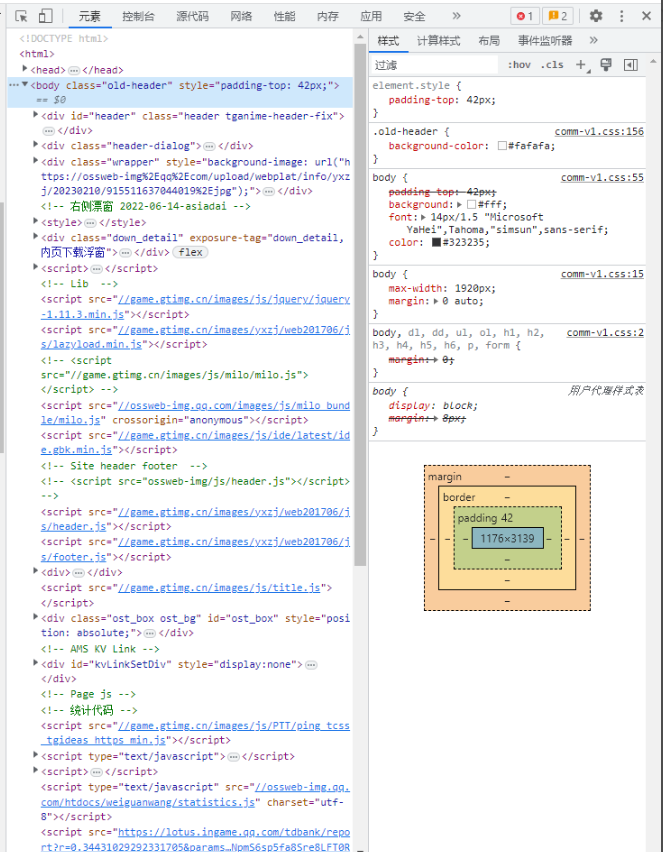
2.获取url
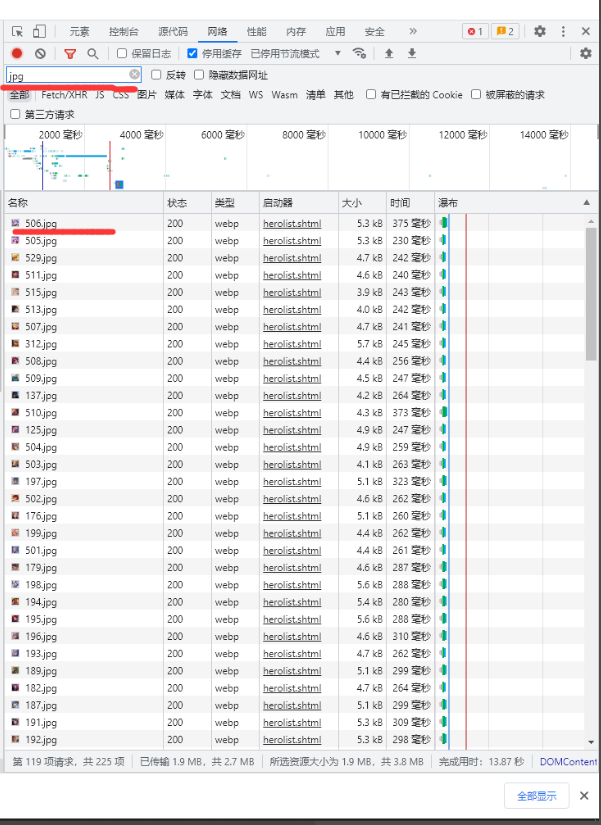
进入后我们点击网络,然后勾选停用缓存,清除一下,然后按F5刷新就会出来数据
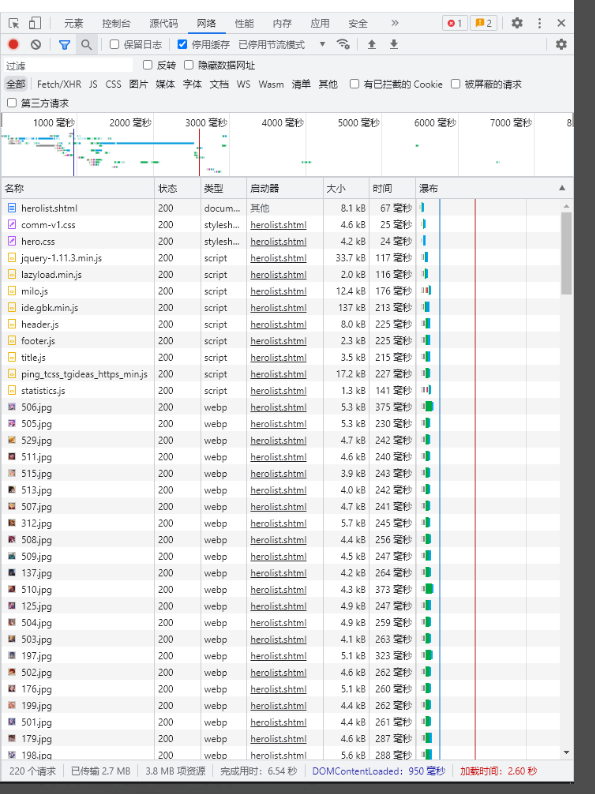
原本需要双击后点击响应,一个个翻找,这里我们节省时间,直接搜索框搜索json,herolist.json即为我们需要找到的英雄名字存在的地方

点击标头,网址即为我们需要爬取的英雄名字包urlhttps://pvp.qq.com/web201605/js/herolist.json
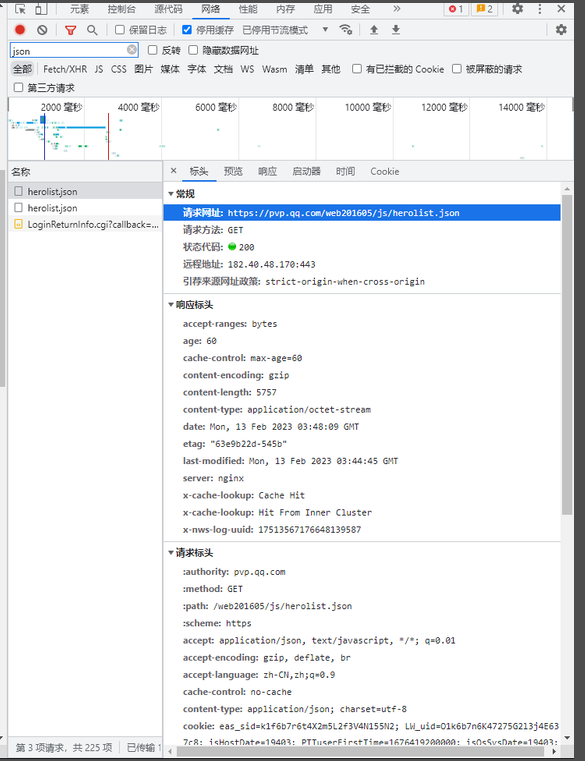
同理,搜索框搜索jpg,点击出来的即为头像网址,任意双击一个即可进入复制,https://game.gtimg.cn/images/yxzj/img201606/heroimg/506/506.jpg

3.使用pycharm进行爬虫操作
我先给源码放入,然后依次讲解
import requests,json
发起请求 获取王者荣耀
res = requests.get('https://pvp.qq.com/web201605/js/herolist.json')
for role in res.json():
cname = role['cname']
ename = role['ename']
# 发起请求 获取角色头像
res2 = requests.get(f'https://game.gtimg.cn/images/yxzj/img201606/heroimg/{ename}/{ename}.jpg')
# 将请求到的图片存到本地磁盘
with open(f'{cname}.jpg','wb') as f:
f.write(res2.content)(1)这里我们需要导入requests,json包,然后请求获取英雄信息
import requests,json
# 发起请求 获取王者荣耀英雄信息
res = requests.get('https://pvp.qq.com/web201605/js/herolist.json')
#这里我们可以打印看一下是否请求成功
print(res.text)如图输出结果没问题

因为我们需要爬取角色头像,所以这里我们只需要英雄名字和序号即可,即ename和cname(因为cname和图片序号对应)
(2)这里运用for循环和json函数,json将数据转换成字典的形式,然后用for循环可以一次输出英雄名字和对应的序号,输出如下
for role in res.json():
cname = role['cname']
ename = role['ename']
#这里可以打印一下看是否正确
print(cname,ename)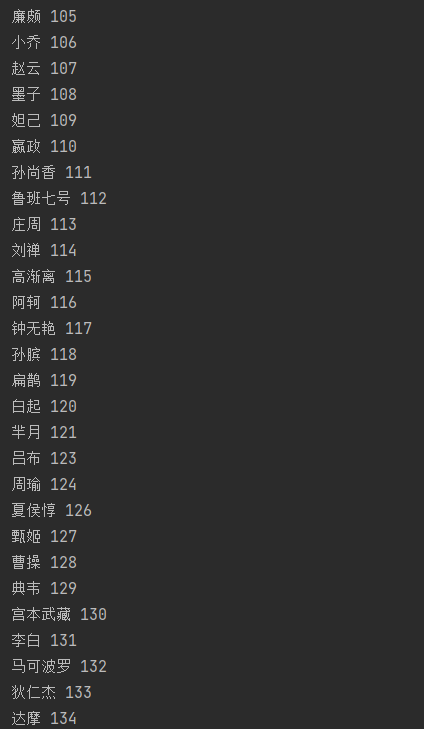
(3)获取英雄头像
这里我们定义一个res2来接受头像信息,注意上面我们已经获取头像地址,https://game.gtimg.cn/images/yxzj/img201606/heroimg/506/506.jpg,这里我们将序号换成{ename},这样循环时可以根据我们的英雄名字所对应的序号来获取对应的图片
# 发起请求 获取角色头像
res2 = requests.get(f'https://game.gtimg.cn/images/yxzj/img201606/heroimg/{ename}/{ename}.jpg')(4)请求把图片保存到本地磁盘
#将请求到的图片存到本地磁盘
with open(f'{cname}.jpg','wb') as f:
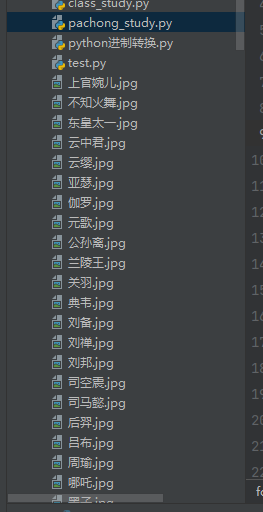
f.write(res2.content)最后运行程序,即可在对应的文件夹下看到英雄和头像信息
二.lol同上
import requests,json
res = requests.get('https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?v=31')
for role in res.json()['hero']:
heroId = role['heroId']
name= role['name']
res2 = requests.get(f'https://game.gtimg.cn/images/lol/act/img/skinloading/{heroId}000.jpg')
with open(f'{name}.jpg', 'wb') as f:
f.write(res2.content)














 1884
1884











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









