







目录
一、前言
特征工程作为机器学习数据准备的核心任务,我们应当重视这一部分的数据的处理工作,主要就是通过变换数据集的特征空间,从而提高数据集的预测模型性能。针对数据集的不同情况,我们可以有多种选择对数据集的特征工程进行处理,如:特征变换,特征构造,特征选择,特征提取或降维,又或者是数据平衡。那么接下来我们将对特征工程中的特征变换先做介绍。
二、正文
特征变化可以分为无量纲处理和数据特征变化等。
Ⅰ.无量纲处理
无量纲处理的方法通常包括:数据标准化、数据缩放,数据归一化。
①数据标准化
标准化(standardization)是一种特征缩放(feature scale)的方法,梯度下降是受益于特征缩放的算法之一。有一种特征缩放的方法叫标准化,标准化使得数据呈现正态分布,能够帮助梯度下降中学习进度收敛的更快。标准化移动特征的均值(期望),使得特征均值(期望)为0,每个特征的标准差为1。
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import preprocessing
#数据读取
Iris=pd.read_csv(r'C:\Users\asuspc\Desktop\program\data\chap2\Iris.csv')
Iris2=Iris.drop(['Id','Species'],axis=1)
#只减去均值
data_scale1=preprocessing.scale(Iris2,with_mean=True,with_std=False)
#减去均值后除以标准差
data_scale2=preprocessing.scale(Iris2,with_mean=True,with_std=True)
#另一种减去均值后除以标准差的方式
data_scale3=preprocessing.StandardScaler(with_mean=True,with_std=True).fit_transform(Iris2)
#可视化原始数据与变换后的数据分布
labs=Iris2.columns.values
plt.figure(figsize=(16,10))
plt.subplot(2,2,1)
plt.boxplot(Iris2.values,notch=True,labels=labs)
plt.grid()
plt.title('Original Data')
plt.subplot(2,2,2)
plt.boxplot(data_scale1,notch=True,labels=labs)
plt.grid()
plt.title('with_mean=True,with_std=False')
plt.subplot(2,2,3)
plt.boxplot(data_scale2,notch=True,labels=labs)
plt.grid()
plt.title('with_mean=True,with_std=True')
plt.subplot(2,2,4)
plt.boxplot(data_scale3,notch=True,labels=labs)
plt.grid()
plt.title('with_mean=True,with_std=True')
plt.subplot_adjust(wspace=0.1)
plt.show()
标准化公式为:
即每个数据值减去变量的均值均值之后除以该变量的标准差。以上是通过sklearn库中的preprocessing模块的scale()和StandardScaler()函数完成,其中通过with_mean和with_std的参数来取决于受否变量是否要操作减去均值和除以标准差。boxplot中的notch是表示:是否是凹口的形式展现箱线图,默认非凹口.
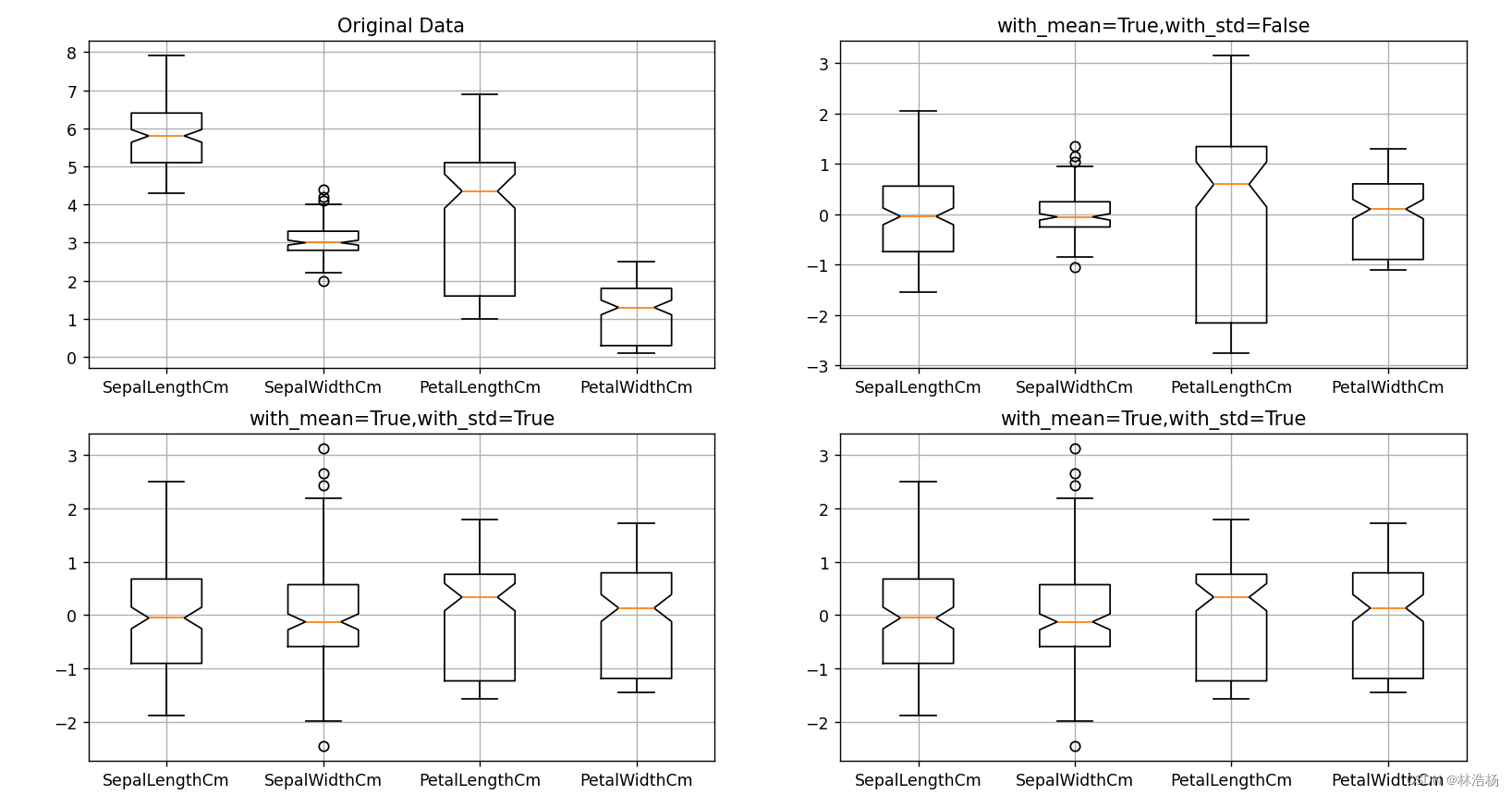
通过四幅图的对比我们可以发现只减去均值的数据分布与原始数据分布一致,只是取值范围发生了变化,而做了标准化的处理之后,不仅仅是取值范围的变化,每个数据的分布也发生了分布。
②数据归一化
把数转换为(0,1)之间的小数;把有量纲的表达式转换为无量纲的表达式;
归一化的好处在于:在多指标评价体系中,由于各个评价指标的性质,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱值水平低指标的作用。因此,为了保证结果的可靠性,需要对原始数据进行标准化处理。
1.min-max标准化
公式:
data_minmax1=preprocessing.MinMaxScaler(feature_range=(0,1)).fit_transform(Iris2)
data_minmax2=preprocessing.MinMaxScaler(feature_range=(1,10)).fit_transform(Iris2)
labs=Iris2.columns.values
plt.figure(figsize=(25,6))
plt.subplot(1,3,1)
plt.boxplot(Iris2.values,notch=True,labels=labs)
plt.grid()
plt.title('Original Data')
plt.subplot(1,3,2)
plt.boxplot(data_minmax1,notch=True,labels=labs)
plt.grid()
plt.title('MinMaxScaler(feature_range(0,1))')
plt.subplot(1,3,3)
plt.boxplot(data_minmax2,notch=True,labels=labs)
plt.grid()
plt.title('MinMaxScaler(feature_range(1,10))')
plt.subplots_adjust(wspace=0.1)
plt.show()
还是preprocessing模块来完成,使用MinMaxScaler()方法来完成,通过feature_range我们可以指定缩放的范围。
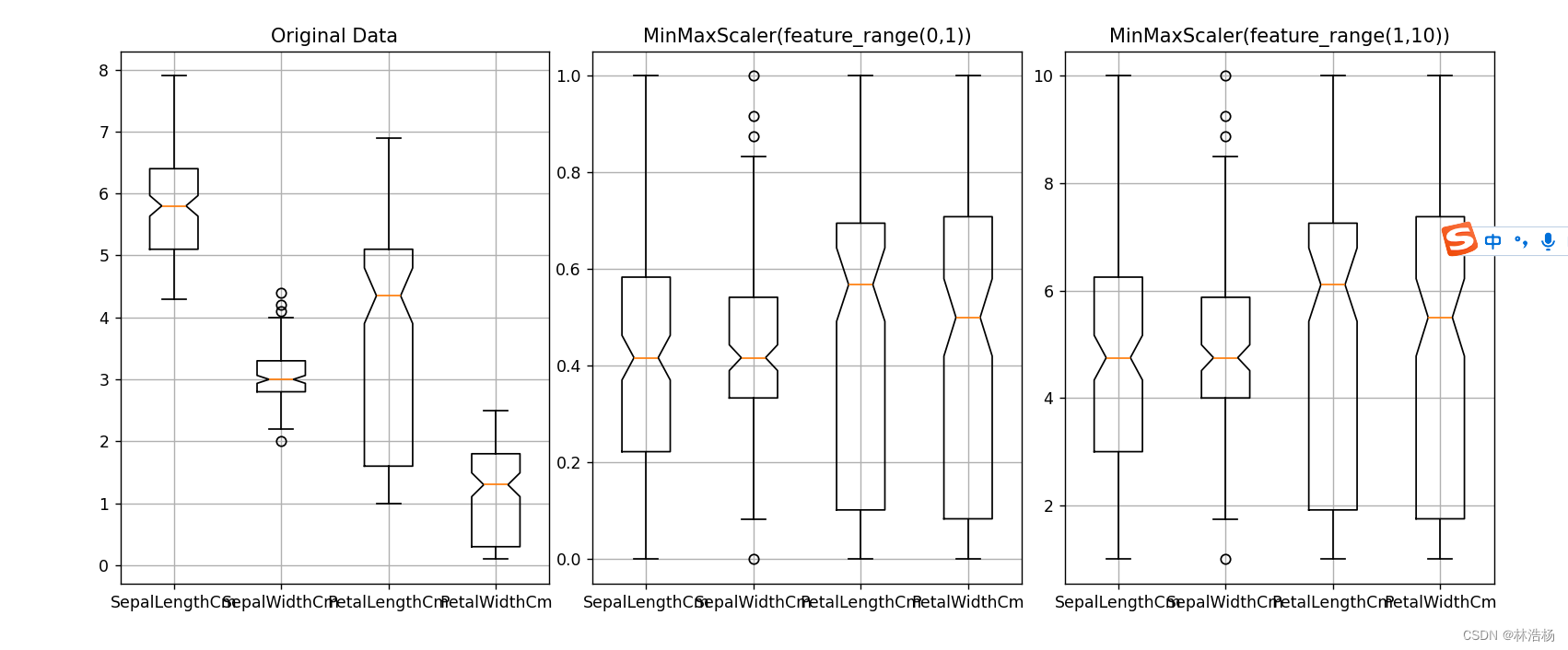
可以看到分布的趋势没有发生改变,但是范围却有所不同。
2.MaxAbsScaler缩放
data_maxabs=preprocessing.MaxAbsScaler().fit_transform(Iris2)
plt.figure(figsize=(16,6))
plt.subplot(1,2,1)
plt.boxplot(Iris2.values,notch=True,labels=labs)
plt.title('Original Data')
plt.subplot(1,2,2)
plt.boxplot(data_maxabs,notch=True,labels=labs)
plt.title('MaxAbsScaler')
plt.show()

变换后的数据范围位0~1,但是变换后的整体取值大小的分布情况与原始特征空间分布比较大。
3.RobustScaler缩放
如果数据存在异常值,我们可以使用鲁棒标准化变换。
data_robs=preprocessing.RobustScaler(with_centering=True,with_scaling=True).fit_transform(Iris2)
labs=Iris2.columns.values
plt.figure(figsize=(25,6))
plt.subplot(1,3,1)
plt.boxplot(Iris2.values,notch=True,labels=labs)
plt.grid()
plt.title('Original Data')
plt.subplot(1,3,2)
plt.boxplot(data_scale2,notch=True,labels=labs)
plt.grid()
plt.title('Stdscaler')
plt.subplot(1,3,3)
plt.boxplot(data_robs,notch=True,labels=labs)
plt.grid()
plt.title('RobustScaler(with_centering=True,with_scaling=True)')
plt.subplots_adjust(wspace=0.07)
plt.show()
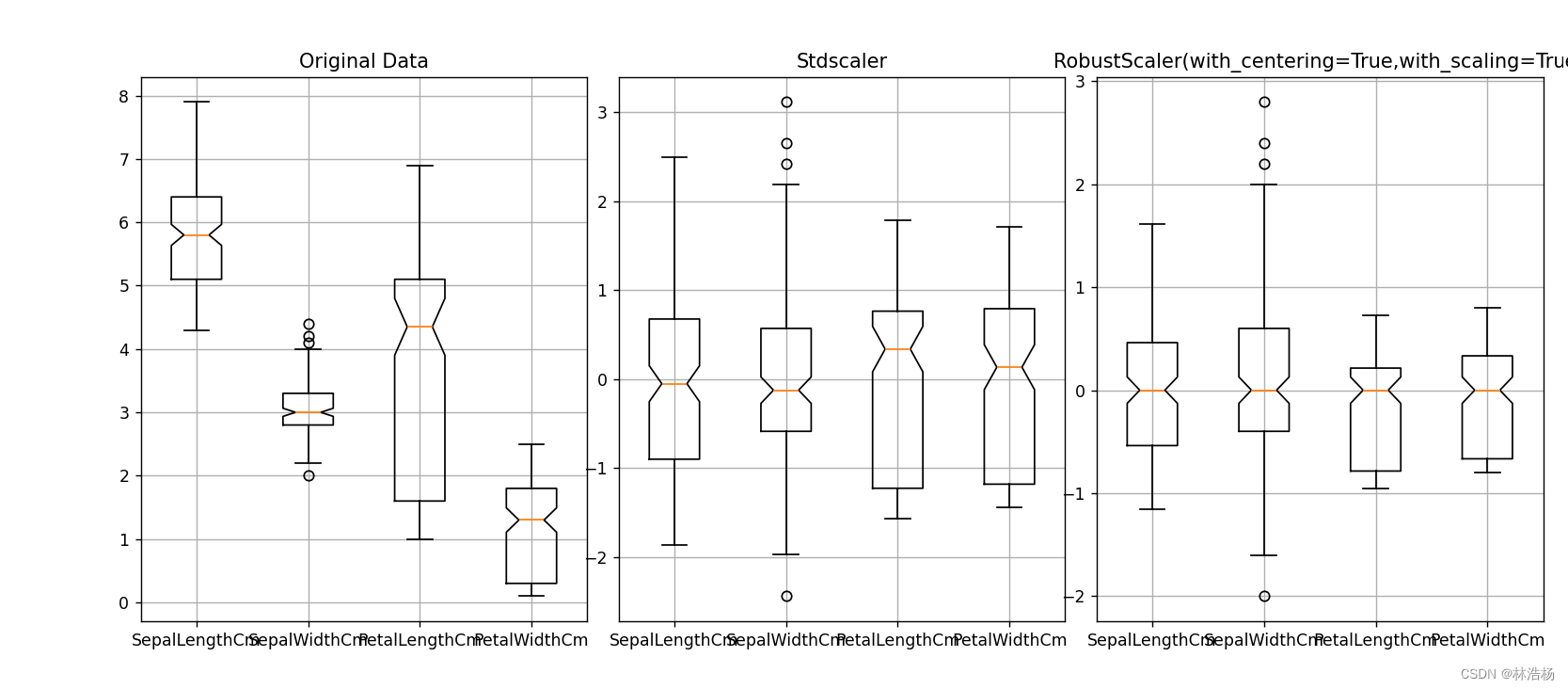
通过观察图中我们就可以发现差异:鲁棒标准化的每个特征的取值范围比数据标准化的每个特征的取值范围更小一些。
4.正则化归一化
data_normL1=preprocessing.normalize(Iris2,norm='l1',axis=0)
data_normL2=preprocessing.normalize(Iris2,norm='l2',axis=0)
plt.figure(figsize=(15,6))
plt.subplot(1,2,1)
plt.boxplot(data_normL1,notch=True,labels=labs)
plt.title('data_normL1')
plt.subplot(1,2,2)
plt.boxplot(data_normL2,notch=True,labels=labs)
plt.title('data_normL2')
plt.show()
l1范数与l2范数约束正则化归一化的对比。
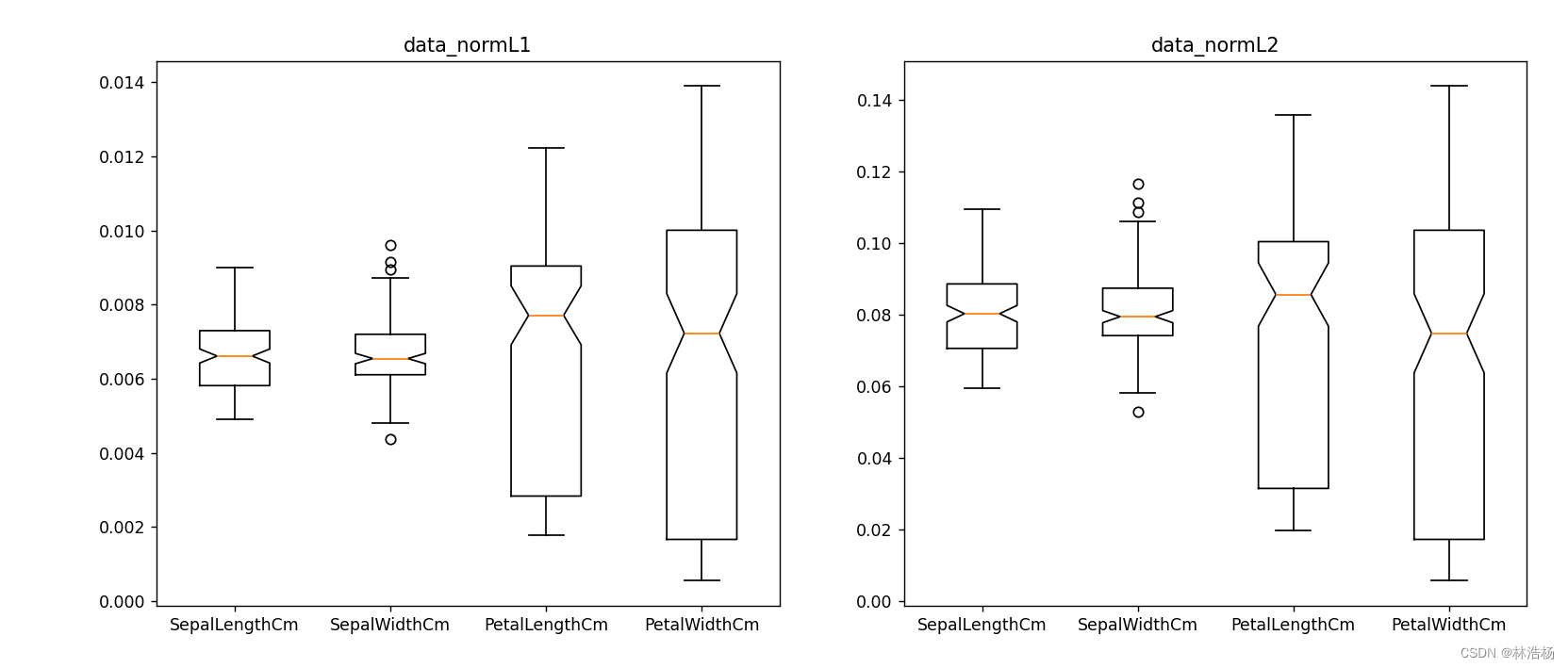
可以发现某些特征的取值范围有明显的差异,第一幅图前两个箱线图取值范围较小。
data_normL1=preprocessing.normalize(Iris2,norm='l1',axis=1)
data_normL2=preprocessing.normalize(Iris2,norm='l2',axis=1)
plt.figure(figsize=(15,6))
plt.subplot(1,2,1)
plt.boxplot(data_normL1,notch=True,labels=labs)
plt.title('data_normL1')
plt.subplot(1,2,2)
plt.boxplot(data_normL2,notch=True,labels=labs)
plt.title('data_normL2')
plt.show()我们改变axis的参数来进行观察。

总结这些方法可以发现,可以发现整体上是对数据的取值范围进行缩放,但是对数据的分布情况影响不大。
Ⅱ.数据特征变化
①对数变换
很多时候数据的分布是一种拖尾id偏态分布,例如商品的价格,少量的高价商品造成其分布是左偏的,此时选择对数变化是个不错的选择。
np.random.seed(12)
x=1+np.random.poisson(lam=1.5,size=5000)+np.random.rand(5000)
#对x进行对数变化
lnx=np.log(x)
#可视化变化前后的数据分布
plt.figure(figsize=(12,5))
plt.subplot(1,2,1)
plt.hist(x,bins=50,edgecolor='k')
plt.title('Original')
plt.subplot(1,2,2)
plt.hist(lnx,bins=50,edgecolor='k')
plt.title('lnx')
plt.show()播下种子随机种子然后用到了泊松回归,对一个偏态的x进行对数的简单处理,然后我们就可以对比数据前后的分布情况了。

可以看到对于原数据的左偏情况,在对数据进行对数处理之后我们可以看到会情况更滑=加接近正态分布的数据分布图。
②Box-Cox
Box-Cox是一种自动寻找最佳正态分布变换函数的方法,其数据的计算公式为:
from scipy.stats import boxcox
np.random.seed(12)
x=1+np.random.poisson(lam=1.5,size=5000)+np.random.rand(5000)
bcx1=boxcox(x,lmbda=0)
bcx2=boxcox(x,lmbda=0.5)
bcx3=boxcox(x,lmbda=2)
bcx4=boxcox(x,lmbda=-1)
plt.subplot(2,2,1)
plt.hist(bcx1,bins=50,edgecolor='k')
plt.title('lnx')
plt.subplot(2,2,2)
plt.hist(bcx2,bins=50,edgecolor='k')
plt.title('$\sqrt{x}$')
plt.subplot(2,2,3)
plt.hist(bcx3,bins=50,edgecolor='k')
plt.title('$x^2$')
plt.subplot(2,2,4)
plt.hist(bcx4,bins=50,edgecolor='k')
plt.title('$1/x$')
plt.show()
通过修改参数lmbda能够对不同的取值变化进行一个调整并画出具体的数据变换后对应的图像。

boxcox函数的帮助下调整参数才能够完成我们的数据变换,注意导包。
可以看出这些函数对偏态的修订有所不同对数以及开根虽是都是解决左偏但他们之间的程度都不一样,而平方把左偏的程度给加剧了,倒数变化则是从另一个另一个极端的变化。有了可视化,我们能够清晰的看出数据变换后的具体情况和作用。
③正态变化
from sklearn import preprocessing
QTn=preprocessing.QuantileTransformer(output_distribution='normal',random_state=0)
QTnx=QTn.fit_transform(x.reshape(5000,1))
#可视化变化前后的数据分布
plt.figure(figsize=(12,5))
plt.subplot(1,2,1)
plt.hist(x,bins=50,edgecolor='k')
plt.title('Original')
plt.subplot(1,2,2)
plt.hist(QTnx,bins=50,edgecolor='k')
plt.title('QTnx')
plt.show()preprocessing模块中QuantileTransformer方法是利用数据的分位数信息进行数据特征变换的方法。
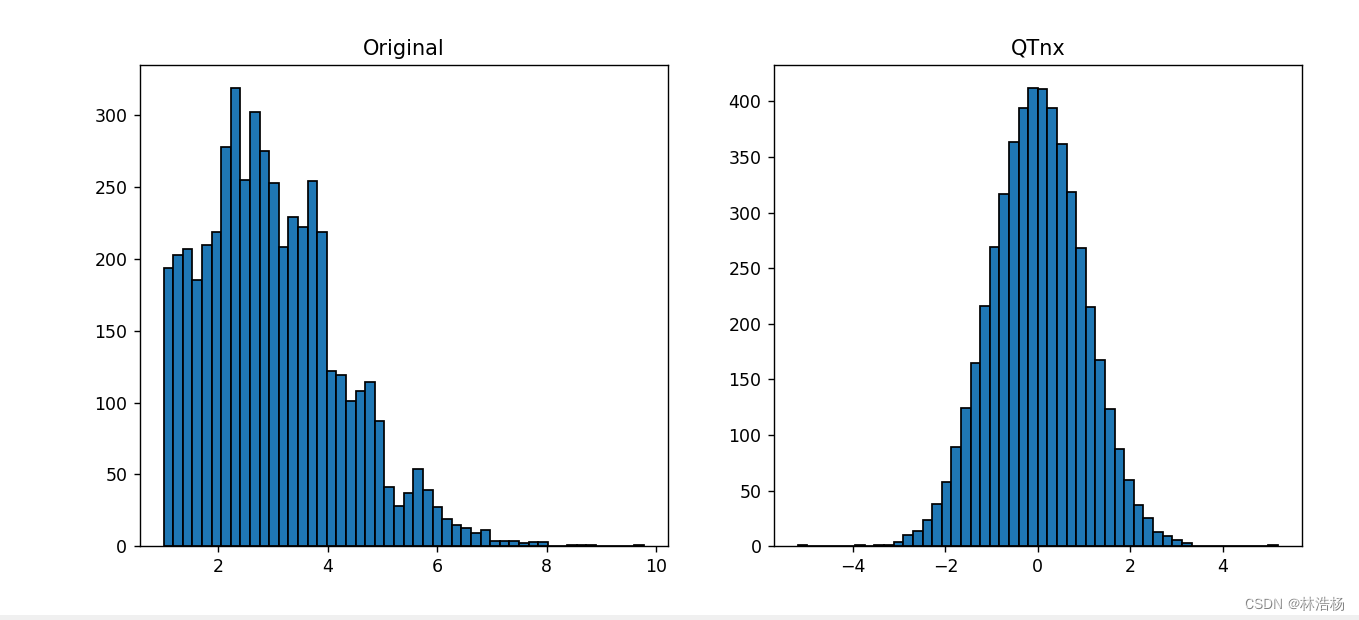
原始数据已经被转化为标准型的正态分布,通过直方图我们能够清晰的看出。
三、结语
特征变换讲到这里就结束了,希望能够对你有帮助。喜欢就点赞收藏并转发给你的小伙伴一起了解吧,感谢您的阅读。
















 609
609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









