









Druid数据连接池在Spring Boot中的配置与使用
Druid提供了一个高效、功能强大、可扩展性好的数据库连接池. 主要用来替换DBCP和c3p0,支持多数据源。下面是来自官方文档的介绍:
Druid连接池是阿里巴巴开源的数据库连接池项目。Druid连接池为监控而生,内置强大的监控功能,监控特性不影响性能。功能强大,能防SQL注入,内置Loging能诊断Hack应用行为。
本文主要介绍Druid在Spring Boot中的应用,目前有两种方法可以实现Druid的使用,第一种是直接引入Druid的maven依赖druid,第二种是引入Druid官方提供的Spring Boot启动器druid-spring-boot-starter。这两种方案都可以实现在Spring Boot应用使用Druid连接池,但是这两者之间是有区别的。第一种方式需要自己编写配置类来实现Druid的各种配置,而且在配置文件中也不会有关于Druid的配置提示,这种方法比较繁琐。第二种方法使用了 Spring Boot 启动器的方式实现,已经有了默认配置,并且修改配置文件时会有相应的提示。这种方法不需要手动编写配置类,大多数功能开始通过配置文件直接开始或者修改。本文将介绍第二种方法。
一、导入依赖
首先创建一个Spring Boot的Web工程,在工程中引入Druid官方的druid-spring-boot-starter依赖:
<!-- https://mvnrepository.com/artifact/com.alibaba/druid-spring-boot-starter -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.4</version>
</dependency>
二、对Druid进行配置
由于Druid Spring Boot Starter 配置属性的名称完全遵照 Druid,我们可以在Spring Boot配置文件中配置Druid数据库连接池和监控,如果没有配置则使用Druid的默认值。这里要强调的是在新版的druid-spring-boot-starter中,filter的开启方式有了变化。变得更加语义化,容易理解。
# SQL监控和SQL防火墙配置
filter:
# Sql统计相关的配置
stat:
# Sql统计功能开启
enabled: true
# 设置数据库类型
db-type: mysql
# 显示统计Sql的数量
slow-sql-millis: 5000
# Sql防火墙配置
wall:
# Sql防火墙功能开启
enabled: true
这里是Druid的配置文档有兴趣的同学可以参考。下面是在本项目中Druid的配置,下列各种配置的含义已经用注释解释,不在过多阐述。
server:
address: localhost
port: 8081
port: 8081
spring:
datasource:
username: root
password: root
# 这里数据库使用的是MYSQL8
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/blog?serverTimezone=UTC
type: com.alibaba.druid.pool.DruidDataSource
druid:
# 初始化连接池的连接数量
initial-size: 5
# 最小连接池数量
min-idle: 5
# 最大连接池数量
max-active: 20
# 配置获取连接等待超时的时间
max-wait: 60000
# 检测间隔时间,检测需要关闭的空闲连接,单位是毫秒
time-between-eviction-runs-millis: 60000
# 单个连接在连接时间,单位是毫秒
min-evictable-idle-time-millis: 30000
# 用来检测连接是否有效的sql,要求是一个查询语句
validation-query: SELECT 1 FROM DUAL
# 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
test-while-idle: true
# 是否缓存preparedStatement,也就是PSCache。官方建议MySQL下建议关闭,如果想用SQL防火墙建议打开。
pool-prepared-statements: false
max-pool-prepared-statement-per-connection-size: 20
# 监控配置相关
stat-view-servlet:
# 监控页面是否开启
enabled: true
# 对监控页面进行拦截
url-pattern: /druid/*
# 禁用监控页面中 重置 按钮的功能是否开启
reset-enable: false
#设置监控页面的登录名和密码
login-username: admin
login-password: admin
# 允许访问的地址
allow: 127.0.0.1
# SQL监控和SQL防火墙配置
filter:
# Sql统计相关的配置
stat:
# Sql统计功能开启
enabled: true
# 设置数据库类型
db-type: mysql
# 显示统计Sql的数量
slow-sql-millis: 5000
# Sql防火墙配置
wall:
# Sql防火墙功能开启
enabled: true
# 配置URI监控和Session监控 这两个是一起的
web-stat-filter:
# 是否开启
enabled: true
# 拦截请求的范围
url-pattern: /*
#设置不统计哪些URL,根据自己业务修改。
exclusions: "*.ico,/druid/*,/swagger/*,/swagger-*,/v2/*,/webjars/*"
# 是否开启session监控
session-stat-enable: true
# 统计的数量
session-stat-max-count: 100
完善相关代码添加好相关的配置后,启动应用访问 http://localhost:8081/druid/sql.html页面就可以看到Druid监控页面。使用配置的用户名和密码登录后就可以看到如下页面。这就显示配置成功。
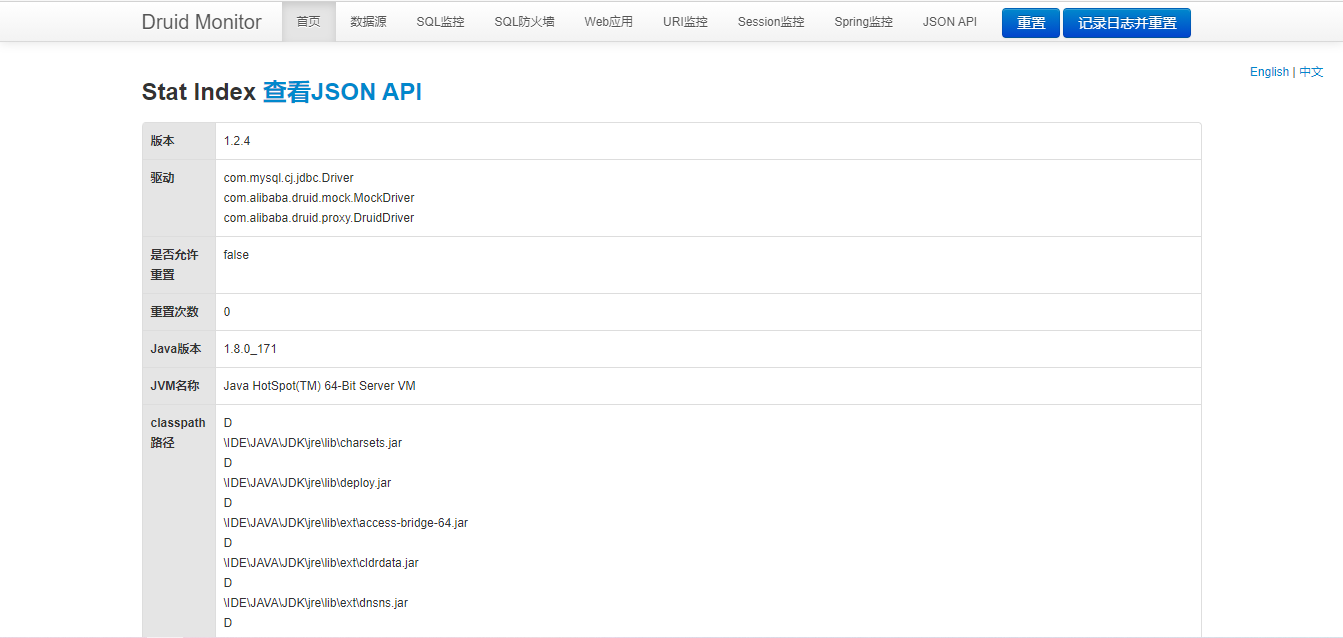
此时,如果有请求访问该应用就可以在SQL监控、URI监控、Web应用、Session监控中看到相关信息。但是在Spring监控无法正常运行,这里要说明的是Spring监控可以显示Spring应用中那个方法的调用产生了SQL的执行,相当好用。如果需要配置Spring监控,就需要使用配置类来实现。
三、通过配置类实现Druid的Spring监控
Druid实现Spring监控的原理是切面来实现的。所以在编写配置类实现配置相关功能。
@Configuration
public class DruidConfiguration {
@Bean
public DruidStatInterceptor druidStatInterceptor() {
DruidStatInterceptor dsInterceptor = new DruidStatInterceptor();
return dsInterceptor;
}
@Bean
@Scope("prototype")
public JdkRegexpMethodPointcut druidStatPointcut() {
JdkRegexpMethodPointcut pointcut = new JdkRegexpMethodPointcut();
// 根据自己工程中Dao层的包名修改
pointcut.setPattern("com.huanlis.blog.dao.*");
return pointcut;
}
@Bean
public DefaultPointcutAdvisor druidStatAdvisor(DruidStatInterceptor druidStatInterceptor, JdkRegexpMethodPointcut druidStatPointcut) {
DefaultPointcutAdvisor defaultPointAdvisor = new DefaultPointcutAdvisor();
defaultPointAdvisor.setPointcut(druidStatPointcut);
defaultPointAdvisor.setAdvice(druidStatInterceptor);
return defaultPointAdvisor;
}
}
再次运行项目就可以在Druid的Spring监控界面中看到相关数据。如下图:
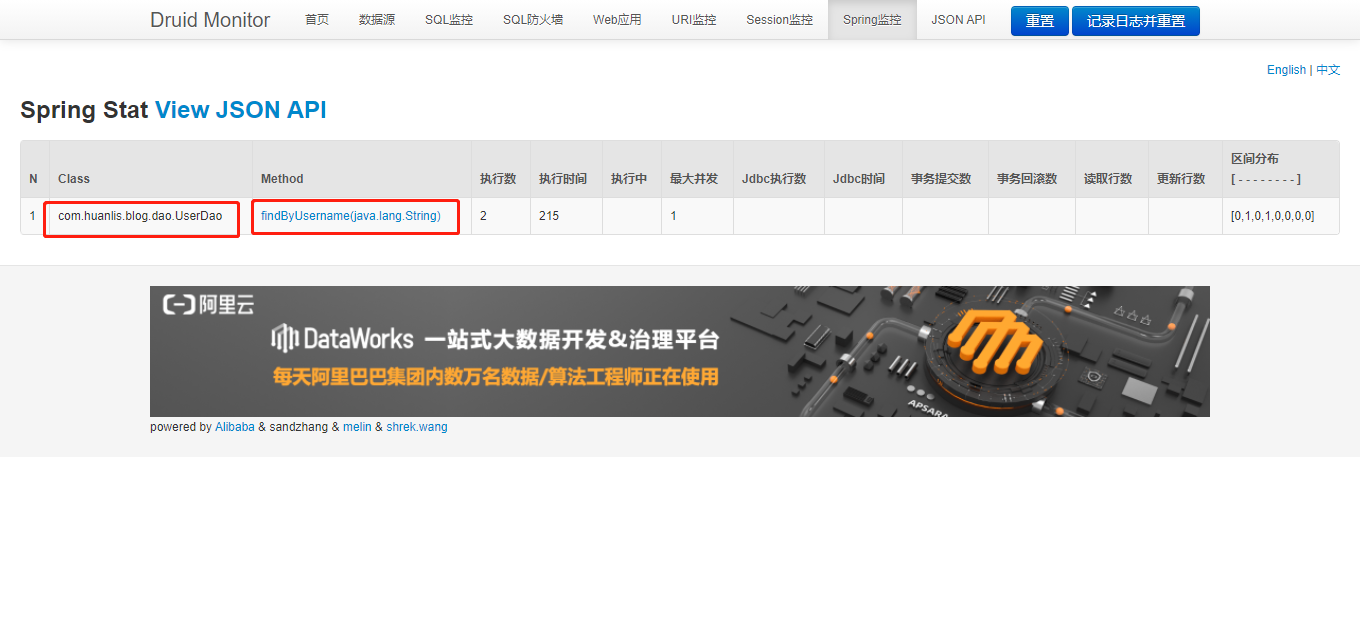
这就表示Druid配置成功。关于Druid的多数据源配置挖个坑以后再填。















 338
338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









