







Lecture 2 Image Classification pipeline
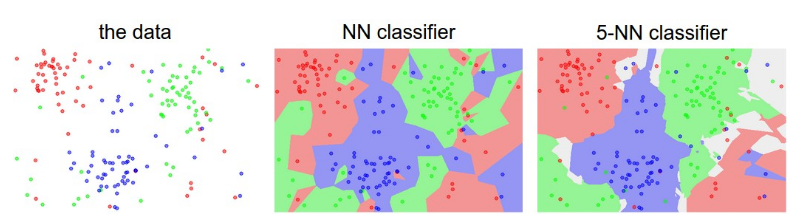
Nearest Neighbor Classifier
load the dataset: CIFAR-10
将60000个数据分为两组,一组为训练数据,一组为测试数据
demo.py
import numpy as np from NearestNeighbor import NearestNeighbor from LoadFile import load_CIFAR10 # a magic function we provide datatr, labeltr, datate, labelte = load_CIFAR10('D:\\data\\cifar-10-batches-py') #print "Xte:%d" %(len(dataTest)) #print "Yte:%d" %(len(labelTest)) Xtr = np.asarray(datatr) Xte = np.asarray(datate) Ytr = np.asarray(labeltr) Yte = np.asarray(labelte) # flatten out all images to be one-dimensional Xtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 * 3) # Xtr_rows becomes 50000 x 3072 Xte_rows = Xte.reshape(Xte.shape[0], 32 * 32 * 3) # Xte_rows becomes 10000 x 3072 dataTr = np.asarray(Xtr) dataTs = np.asarray(Xte) labelTr = np.asarray(Ytr) labelTs = np.asarray(Yte) nn = NearestNeighbor() # create a Nearest Neighbor classifier class nn.train(Xtr_rows, Ytr) # train the classifier on the training images and labels Yte_predict = nn.predict(Xte_rows) # predict labels on the test images and now print the classification accuracy, which is the average number of examples that are correctly predicted (i.e. label matches) print('accuracy: %f' % (np.mean(Yte_predict == Yte)))loadfile.py
import numpy as np import os def unpickle(file): import pickle with open(file, 'rb') as fo: dict = pickle.load(fo, encoding='bytes') return dict def load_CIFAR10(file): # get the training data dataTrain = [] labelTrain = [] for i in range(1, 6): dic = unpickle(os.path.join(file, "data_batch_" + str(i))) for item in dic[b"data"]: dataTrain.append(item) for item in dic[b"labels"]: labelTrain.append(item) # get test data dataTest = [] labelTest = [] dic = unpickle(os.path.join(file, "test_batch")) for item in dic[b"data"]: dataTest.append(item) for item in dic[b"labels"]: labelTest.append(item) return (dataTrain, labelTrain, dataTest, labelTest)NearestNeighbor.py
import numpy as np class NearestNeighbor(object): def __init__(self): pass def train(self, X, y): self.Xtr = X self.ytr = y def predict(self, X): num_test = X.shape[0] # lets make sure that the output type matches the input type Ypred = np.zeros(num_test, dtype = self.ytr.dtype) # loop over all test rows for i in range(num_test): # find the nearest training image to the i'th test image # using the L1 distance (sum of absolute value differences) distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1) min_index = np.argmin(distances) # get the index with smallest distance Ypred[i] = self.ytr[min_index] # predict the label of the nearest example return Ypred
首先通过d1公式来计算误差:
d1(I1,I2)=∑p|Ip1−Ip2|
经过测试正确率为38.6%
距离d2公式为:
d2(I1,I2)=∑p(Ip1−Ip2)2‾‾‾‾‾‾‾‾‾‾‾‾√
经测试正确率为35.4%
由此可以看出在进行数据训练和测试的时候,求证误差的公式是根据具体情况来调整的,而不是唯一的。
### K-Nearest Neighbor Classifier
通过上面的测试,我们可以看出,只用标签来预测图片可能还不是 很准确
这个方法不是找最近的图片,而是找最高的k值
“`
Xval_rows = Xtr_rows[:1000, :] # take first 1000 for validation
Yval = Ytr[:1000]
Xtr_rows = Xtr_rows[1000:, :] # keep last 49,000 for train
Ytr = Ytr[1000:]
find hyperparameters that work best on the validation set
validation_accuracies = []
for k in [1, 3, 5, 10, 20, 50, 100]:
use a particular value of k and evaluation on validation data
nn = NearestNeighbor()
nn.train(Xtr_rows, Ytr)
here we assume a modified NearestNeighbor class that can take a k as input
Yval_predict = nn.predict(Xval_rows, k = k)
acc = np.mean(Yval_predict == Yval)
print 'accuracy: %f' % (acc,)
keep track of what works on the validation set
validation_accuracies.append((k, acc))
“`
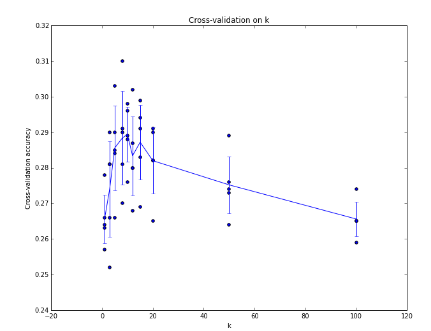
将得到的所有数据画在图上后的得到的结果,可以看出当k=7时为最高值















 1088
1088

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









