







逻辑回归的分类预测
此笔记为阿里云天池机器学习训练营笔记,学习地址:https://tianchi.aliyun.com/specials/promotion/aicampml
感谢老师教程及阿里云提供平台
学习内容
1.理解逻辑回归理论
2.掌握 逻辑回归 的 sklearn 函数调用使用并将其运用到鸢尾花数据集预测
3.巩固python可视化描述操作
逻辑回归理论
逻辑回归 原理简介:
Logistic回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别,对于多分类而言,将多个二分类的逻辑回归组合),所以利用了Logistic函数(或称为Sigmoid函数),函数形式为:
l
o
g
i
(
z
)
=
1
1
+
e
−
z
logi(z)=\frac{1}{1+e^{-z}}
logi(z)=1+e−z1
其对应的函数图像可以表示如下: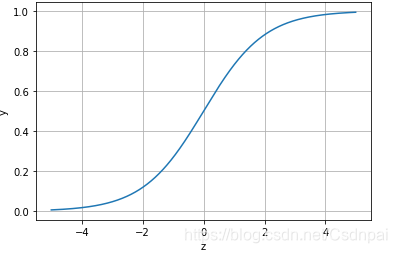
逻辑回归其实是实现了一个决策边界:对于函数
y
=
1
1
+
e
−
z
y=\frac{1}{1+e^{-z}}
y=1+e−z1,当
z
=
>
0
z=>0
z=>0时,
y
=
>
0.5
y=>0.5
y=>0.5,分类为1,当
z
<
0
z<0
z<0时,
y
<
0.5
y<0.5
y<0.5,分类为0,其对应的
y
y
y值我们可以视为类别1的概率预测值。
sklearn 函数调用
## 导入逻辑回归模型函数
from sklearn.linear_model import LogisticRegression
再导入iris数据集进行训练
##Demo演示LogisticRegression分类
## 构造数据集
x_fearures = np.array([[-1, -2], [-2, -1], [-3, -2], [1, 3], [2, 1], [3, 2]])
y_label = np.array([0, 0, 0, 1, 1, 1])
## 调用逻辑回归模型
lr_clf = LogisticRegression()
## 用逻辑回归模型拟合构造的数据集
lr_clf = lr_clf.fit(x_fearures, y_label) #其拟合方程为 y=w0+w1*x1+w2*x2
## 查看其对应模型的w
print('the weight of Logistic Regression:',lr_clf.coef_)
## 查看其对应模型的w0
print('the intercept(w0) of Logistic Regression:',lr_clf.intercept_)
可视化描述操作
使用matplotlib的pyplot包画图使实验结果得以展示
## 可视化构造的数据样本点
plt.figure()
plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap='viridis')
plt.title('Dataset')
plt.show()
## 绘图函数库
import matplotlib.pyplot as plt
import seaborn as sns
`## 我们利用 sklearn 中自带的 iris 数据作为数据载入,并利用Pandas转化为DataFrame格式
from sklearn.datasets import load_iris
data = load_iris() #得到数据特征
iris_target = data.target #得到数据对应的标签
iris_features = pd.DataFrame(data=data.data, columns=data.feature_names) #利用Pandas转化为DataFrame格式
##进行浅拷贝,防止对于原始数据的修改
iris_all['target'] = iris_target
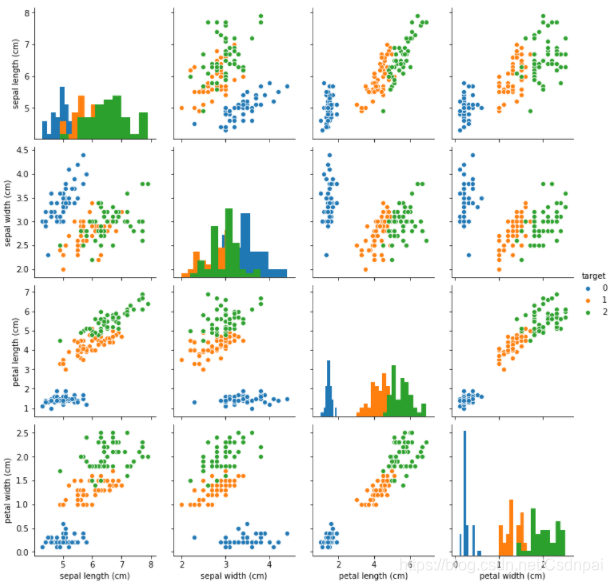
不同特征鸢尾花的品种分布:可看出特征是否独立,如果相关性大可能后期处理的时候可以剔除一个参数(比如下图花瓣长宽变量相关性较大,可以选其中一个参数来分类)
##特征与标签组合的散点可视化
sns.pairplot(data=iris_all,diag_kind='hist', hue= 'target')
plt.show()
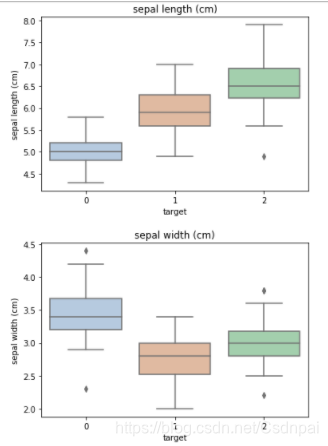
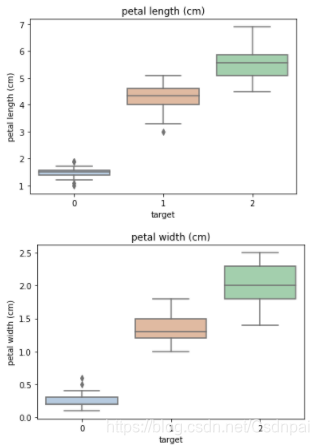
箱式图:显示数据分布,可看出数据最大最小及中位数(判断数据有没有异常,有异常的数据需要踢掉,这是训练之前所需要的一些准备)
for col in iris_features.columns:
sns.boxplot(x='target', y=col, saturation=0.5,palette='pastel', data=iris_all)
plt.title(col)
plt.show()















 240
240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









