







 一 重要的数据结构1 每一种具体的调度算法主要工作是实现这些接口2 该结构抽象了每种具体调度算法,最重要的成员是ops,实现了上面定义的接口3 对应于deadline调度算法的结构为4 电梯调度队列,存储了具体调度类型以及该类型用到的存储结构.具体调度算法用到的存储结构,因调度算法而异, 因此是void *5 deadline调度算法的存储结构,初始化时被存储在elevator_queue->elevator_data中可以看到这有4个队列struct rb_root sor
一 重要的数据结构1 每一种具体的调度算法主要工作是实现这些接口2 该结构抽象了每种具体调度算法,最重要的成员是ops,实现了上面定义的接口3 对应于deadline调度算法的结构为4 电梯调度队列,存储了具体调度类型以及该类型用到的存储结构.具体调度算法用到的存储结构,因调度算法而异, 因此是void *5 deadline调度算法的存储结构,初始化时被存储在elevator_queue->elevator_data中可以看到这有4个队列struct rb_root sor
一 重要的数据结构
1 每一种具体的调度算法主要工作是实现这些接口
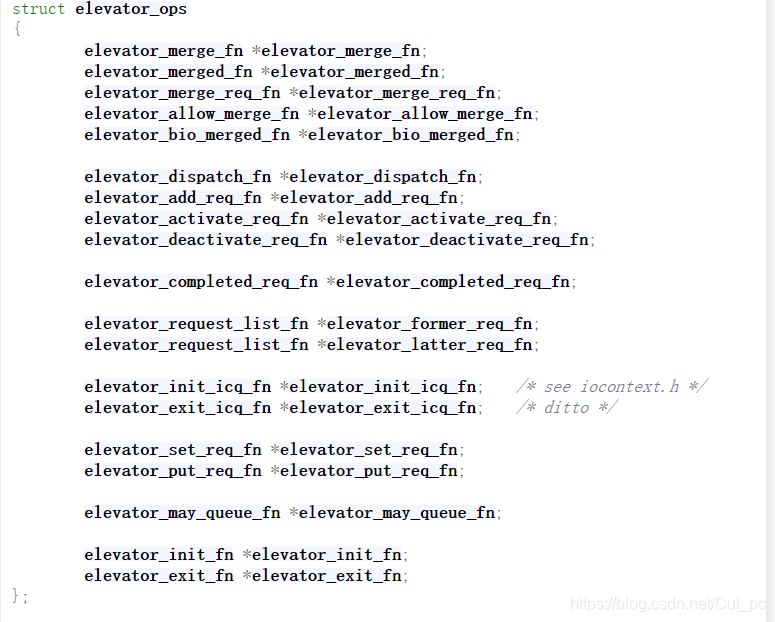
2 该结构抽象了每种具体调度算法,最重要的成员是ops,实现了上面定义的接口

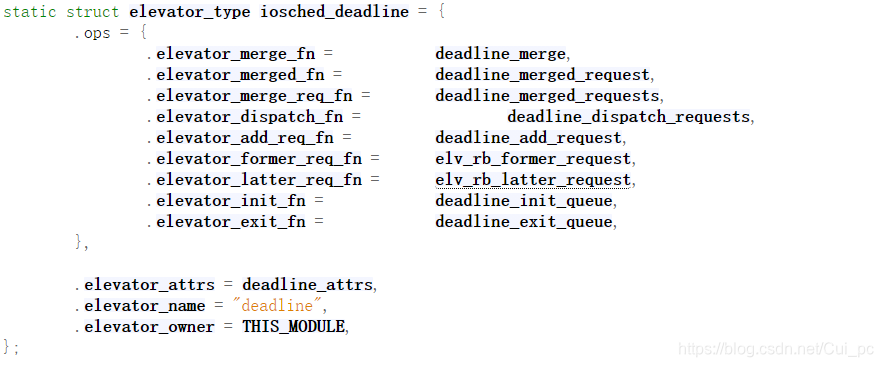
3 对应于deadline调度算法的结构为
4 电梯调度队列,存储了具体调度类型以及该类型用到的存储结构.具体调度算法用到的存储结构,因调度算法而异, 因此是void *

5 deadline调度算法的存储结构,初始化时被存储在elevator_queue->elevator_data中

可以看到这有4个队列
struct rb_root sort_list[2];
struct list_head fifo_list[2];
sort_list是红黑树的根,用于对io请求按起始扇区编号进行排序,这里有两颗树,一颗读请求树,一颗写请求树。
fifo_list:存储request的FIFO队列,为了解决request饿死问题,每个request也按照读写方向被分别存放在两个FIFO链表中;
二 deadline初始化
与调度算法相关的结构是伴随着请求队列request_queue的初始化而被设置的。
--->blk_init_queue()
-- 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 350
350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









