






Linux内核中定义了5个调度器类,分别对应5个调度器,调度优先级顺序由高到低依次为:stop_sched_class、dl_sched_class、rt_sched_class、fair_sched_class、idle_sched_class。
其中dl_sched_class和rt_sched_class分别对应dl调度器和rt调度器,为实时任务所采用的调度器。相对于rt_sched_class调度类,dl_sched_class调度类中的任务调度顺序更加优先,会抢占rt_sched_class调度类和fair_sched_class调度类的任务,更早的得到cpu调度。
本文介绍dl_sched_class调度类任务及其调度算法。
Deadline调度策略介绍
实时系统除了要求在确定的时间期限内做出响应外,还要求在确定的时间期限内完成任务,所谓的确定的时间期限,我们称之为deadline。在Linux内核中,rt调度器是根据任务优先级进行调度,dl调度器,顾名思义,是根据任务的deadline进行调度。
使用dl调度器的任务,我们将其抽象为三个元素:
- period:调度周期,即该任务需要被调度的周期时间;
- runtime:每周期内的运行时间,即该任务在该调度周期内的运行时间,其实多数任务在每周期内运行时间并不会完全相同,所以,在dl调度器的语境下,每周期内的运行时间,通常指的是最坏执行时间,即WCET(worst-case execution time);
- deadline:每周期的截止时间,即该任务在一个调度周期内,必须在截止时间之前完成任务,在dl调度器的开发中,deadline可以与period相同,在代码中称作“implicit deadline”,deadline也可以小于period,称作“constrained deadline”。
其中: runtime <= deadline <= period
这三个元素的具体关系可以见下图:
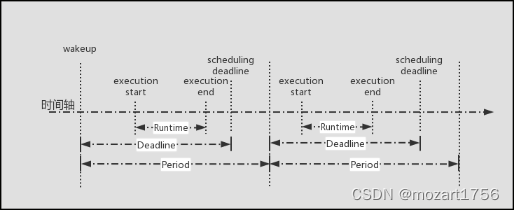
下面我们看一下dl调度器具体是如何工作的,我们假设一个场景,包括三个周期性的任务,其参数如下:
| Task | Runtime(WCET) | Period |
| T1 | 1 | 4 |
| T2 | 2 | 6 |
| T3 | 3 | 8 |
为了简单起见,本例中的任务为之前面提到过的“implicit deadline”,即deadline等于period。
那么该三个任务在dl调度器中的工作状态可以如下图所示:
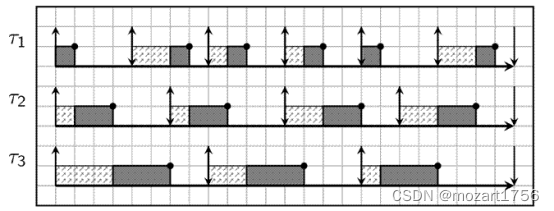
通过上图可知,三个任务都在deadline之前完成了各自的任务,周而复始,循环往复。从这点也可以看出,dl调度器更加兼顾了多个实时任务同时满足时间需求的场景,这点上是要优于rt调度器的。
这个例子中,如果三个任务都运行在同一个CPU上,那么CPU的利用率为:
U = 1/4 + 2/6 + 3/8 = 23/24
那么单核的CPU利用率的通用公式为:

从公式中可以看出,在单核系统中,当CPU利用率小于1(如果考虑到rt throttling,那么这个数值为95%),dl调度器可以满足要求,如果大于1(如果考虑到rt throttling,那么这个数值为95%)的情况下,dl调度器就不能满足如此多的任务同时运行了。
在多处理器的环境内进行dl的全局调度,事情会变得更加的复杂,一个申请dl调度器的任务的准入公式为:
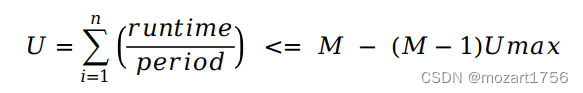
即每个任务的运行时间/周期的总和应该小于或等于处理器的数目M,减去最大的利用率Umax乘以(M-1)。
从上述介绍可知,deadline调度策略本质上是一个装箱问题(bin packing),即将若干个实时任务(小箱子)装到若干个大箱子(处理器)中,该问题到目前为止,只有近似解而没有精确解。
dl调度器所使用的数据结构
本节介绍dl调度器中最常用的几个变量,如下图所示,dl调度器中每一个任务被认为一个调度实体,由一个结构表示,即struct sched_dl_entity,如下图所示:
struct sched_dl_entity {
struct rb_node rb_node;
/*
* Original scheduling parameters. Copied here from sched_attr
* during sched_setattr(), they will remain the same until
* the next sched_setattr().
*/
u64 dl_runtime; /* Maximum runtime for each instance */ --- (1)
u64 dl_deadline; /* Relative deadline of each instance */ --- (2)
u64 dl_period; /* Separation of two instances (period) */ --- (3)
u64 dl_bw; /* dl_runtime / dl_period */
u64 dl_density; /* dl_runtime / dl_deadline */
/*
* Actual scheduling parameters. Initialized with the values above,
* they are continuously updated during task execution. Note that
* the remaining runtime could be < 0 in case we are in overrun.
*/每周期的截止时间
s64 runtime; /* Remaining runtime for this instance */ --- (4)
u64 deadline; /* Absolute deadline for this instance */ --- (5)
...
struct hrtimer dl_timer; ---(6)
...
}
- dl_runtime,每周期内的运行时间,即该任务在该调度周期内的运行时间,其实多数任务在每周期内运行时
- 的截止时间,dl_deadline的数值为从运行周期开始的相对时间。
- dl_period,调度周期,即该任务需要被调度的周期时间。
- runtime,剩余运行时间,每个任务在每个周期内的运行时间的总量为dl_runtime,runtime为dl_runtime减去该任务已经运行的时间。
- deadline,每周期的截止时间的绝对时间。
- dl_timer,每个调度实体都包含一个timer,时间为dl_period。
此外,每个CPU的dl调度队列(runqueue)使用红黑树来管理这些调度实体(sched_dl_entity),该红黑树使用deadline作为索引,最左面的调度实体的deadline最小,即应该被最先调度。
dl调度器的代码实现
dl调度器实现了两个算法来管理调度队列中的任务:
- EDF,Early deadline first。
- CBS,Constant bindwidth server。
下面我们逐一做代码分析:
所谓EDF,即最早的deadline的任务优先得到调度,在dl调度器算法中,主要依靠每个CPU调度队列的红黑树来实现,首先我们来看一下调度器的入队函数,即enqueue_task:
static void __enqueue_dl_entity(struct sched_dl_entity *dl_se)
{
struct dl_rq *dl_rq = dl_rq_of_se(dl_se);
struct rb_node **link = &dl_rq->root.rb_root.rb_node;
struct rb_node *parent = NULL;
struct sched_dl_entity *entry;
int leftmost = 1;
BUG_ON(!RB_EMPTY_NODE(&dl_se->rb_node));
while (*link) {
parent = *link;
entry = rb_entry(parent, struct sched_dl_entity, rb_node);
if (dl_time_before(dl_se->deadline, entry->deadline))
link = &parent->rb_left;
else {
link = &parent->rb_right;
leftmost = 0;
}
}
rb_link_node(&dl_se->rb_node, parent, link);
rb_insert_color_cached(&dl_se->rb_node, &dl_rq->root, leftmost);
inc_dl_tasks(dl_se, dl_rq);
}
可以看到,当把一个任务的调度实体放置到红黑树中的时候,是根据该任务的deadline,把该调度实体放到红黑树的相应位置,也就是左面的节点都小于该调度实体的deadline,右面的节点都大于该调度实体的deadline。
在入队操作中,dl调度器还要调用函数replenish_dl_entity,在一个新的调度周期内重新设置调度实体的runtime和deadline,代码如下:
static void replenish_dl_entity(struct sched_dl_entity *dl_se,
struct sched_dl_entity *pi_se)
{
...
while (dl_se->runtime <= 0) {
dl_se->deadline += pi_se->dl_period;
dl_se->runtime += pi_se->dl_runtime;
}
...
}当进行任务切换的时候,调度器选择红黑树最左面的节点进行调度,见代码:
static struct sched_dl_entity *pick_next_dl_entity(struct rq *rq,
struct dl_rq *dl_rq)
{
struct rb_node *left = rb_first_cached(&dl_rq->root);
if (!left)
return NULL;
return rb_entry(left, struct sched_dl_entity, rb_node); --- (1)
}
static struct task_struct *
pick_next_task_dl(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
struct sched_dl_entity *dl_se;
struct dl_rq *dl_rq = &rq->dl;
struct task_struct *p;
WARN_ON_ONCE(prev || rf);
if (!sched_dl_runnable(rq))
return NULL;
dl_se = pick_next_dl_entity(rq, dl_rq); --- (2)
BUG_ON(!dl_se);
p = dl_task_of(dl_se); --- (3)
set_next_task_dl(rq, p, true);
return p;
}- 取得红黑树的最左面的节点,并获取该节点上的调度实体。
- 返回该调度实体。
- 通过调度实体获取该任务的task_struct,该任务即即将取得CPU的任务。
通过上述操作,dl调度器实现了early deadline first,即EDF。那么调度器在什么时机进行任务的调度呢,还记得sched_dl_entity中的dl_timer么,这个timer以period为周期,定期触发,在该timer触发之后,说明其所属的调度实体的新的一个周期开始了。该timer的回调函数实现如下:
static enum hrtimer_restart dl_task_timer(struct hrtimer *timer)
{
struct sched_dl_entity *dl_se = container_of(timer,
struct sched_dl_entity,
dl_timer);
struct task_struct *p = dl_task_of(dl_se);
...
enqueue_task_dl(rq, p, ENQUEUE_REPLENISH); --- (1)
if (dl_task(rq->curr))
check_preempt_curr_dl(rq, p, 0);
else
resched_curr(rq); --- (2)
...
}- 将该调度实体插入到调度队列的红黑树中,在入队操作中,还要重新设置该调度实体的runtime和deadline。
- 设置标志,在中断返回时进行上下文的切换。
dl_timer的设置函数为start_dl_timer:
static int start_dl_timer(struct task_struct *p)
{
struct sched_dl_entity *dl_se = &p->dl;
struct hrtimer *timer = &dl_se->dl_timer;
struct rq *rq = task_rq(p);
ktime_t now, act;
s64 delta;
...
act = ns_to_ktime(dl_next_period(dl_se)); --- (1)
now = hrtimer_cb_get_time(timer);
delta = ktime_to_ns(now) - rq_clock(rq);
act = ktime_add_ns(act, delta); --- (2)
...
if (!hrtimer_is_queued(timer)) {
get_task_struct(p);
hrtimer_start(timer, act, HRTIMER_MODE_ABS_HARD); ---(3)
}
return 1;
}- 获取该任务调度实体的运行周期。
- 计算下一次周期开始的时间。
- 启动dl_timer。
该函数会在两个时间被调用,一个是该任务用完了所有的运行时间,即task_tick_dl中调用,另外一个是在该任务在runtime之内就完成了工作,主动调用sched_yield放弃CPU时调用,其中task_tick_dl和sched_yield涉及到CBS的内容,会在接下来的内容具体分析。
当实时应用在runtime耗尽之前就完成了工作,需要调用sched_yield函数来告诉调度器这个情况,调度器会将当前任务调离调度队列,同时,为该任务设置下一个运行周期的timer,代码如下:
static void yield_task_dl(struct rq *rq)
{
/*
* We make the task go to sleep until its current deadline by
* forcing its runtime to zero. This way, update_curr_dl() stops
* it and the bandwidth timer will wake it up and will give it
* new scheduling parameters (thanks to dl_yielded=1).
*/
rq->curr->dl.dl_yielded = 1; ---(1)
update_rq_clock(rq);
update_curr_dl(rq); ---(2)
/*
* Tell update_rq_clock() that we've just updated,
* so we don't do microscopic update in schedule()
* and double the fastpath cost.
*/
rq_clock_skip_update(rq);
static void update_curr_dl(struct rq *rq)
{
struct task_struct *curr = rq->curr;
struct sched_dl_entity *dl_se = &curr->dl;
...
throttle:
if (dl_runtime_exceeded(dl_se) || dl_se->dl_yielded) {
dl_se->dl_throttled = 1;
/* If requested, inform the user about runtime overruns. */
if (timerdl_runtime_exceeded(dl_se) &&
(dl_se->flags & SCHED_FLAG_DL_OVERRUN))
dl_se->dl_overrun = 1;
__dequeue_task_dl(rq, curr, 0); ---(3)
if (unlikely(dl_se->dl_boosted || !start_dl_timer(curr))) ---(4)
enqueue_task_dl(rq, curr, ENQUEUE_REPLENISH);
if (!is_leftmost(curr, &rq->dl))
resched_curr(rq);
}
...
}- 设置dl_yield标志位,表示任务在耗尽runtime之前主动放弃了CPU。
- 调用update_curr_dl。
- 将当前任务调离调度队列。
- 为当前任务设置下一个运行周期的timer。
另一种情况,在实时任务耗尽runtime之后,仍然没有完成任务,继续使用CPU,如果不加以制止,会引起多米诺效应,导致调度队列中其他的实时任务也相继无法满足deadline的时间要求。所以,在dl调度器中,开发了CBS协议,在任务耗尽了其声明的runtime之后,强制将其调离调度队列,将CPU交给其他的任务。
调度器在上下文切换之前,会启动一个hrtick,设置该任务的最坏情况运行时间:
pick_next_task_dl
--> set_next_task_dl
--> start_hrtick_dl
static void start_hrtick_dl(struct rq *rq, struct task_struct *p)
{
hrtick_start(rq, p->dl.runtime);
}可以看到,tick的设定时间为runtime。
dl调度器响应hrtick的回调函数是task_tick_dl,当tick到时之后,dl调度器同样的,将当前任务调离调度队列,同时,为该任务设置下一个运行周期的timer。
此外,还有两个问题需要我们思考一下,一个是任务调用sched_yield释放CPU,那么,整个调度器的带宽就不像声明的那样紧张了,是不是可以把这些带宽留给那些runtime不够用的任务。社区正在计划开发GRUB(Greedy Reclaim of Unused Bandwidth)协议,这个GRUB跟boot loader不是一码事儿。
另一个是CPU Frequency的变化,当CPU主频改变的时候,实时任务在同样的runtime中所计算的效率就不一样了,所以在dl调度器中,根据CPU主频的变化,任务的runtime会进行调整,具体的代码这里就不分析了,感兴趣的读者可以自行阅读代码分析。
dl调度器任务的设置和部署
实时任务的三个元素period,runtime和deadline需要在任务创建的时候使用系统调用sched_setattr声明,代码示例如下:
struct sched_attr attr;
attr.sched_policy = SCHED_DEADLINE;
attr.sched_runtime = 100;
attr.sched_deadline = 800;
attr.sched_period = 1000;
sched_setattr(0, &attr, 0);此外,还可以通过chrt命令设置实时任务的参数,如:
chrt -d --sched-runtime 5000000 --sched-deadline 10000000 --sched-period 15000000 0 ./dl_task内核调用__sched_setscheduler将sched_attr中的参数设置到实时任务的sched_dl_entity中:
static int __sched_setscheduler(struct task_struct *p,
const struct sched_attr *attr,
bool user, bool pi)
{
...
if ((dl_policy(policy) || dl_task(p)) && sched_dl_overflow(p, policy, attr)) { --- (1)
retval = -EBUSY;
goto unlock;
}
...
__setscheduler(rq, p, attr, pi); --- (2)
...
}
static void __setscheduler(struct rq *rq, struct task_struct *p,
const struct sched_attr *attr, bool keep_boost)
{
__setscheduler_params(p, attr); --- (3)
if (dl_prio(p->prio))
p->sched_class = &dl_sched_class; --- (4)
...
}
static void __setscheduler_params(struct task_struct *p,
const struct sched_attr *attr)
{
if (dl_policy(policy))
__setparam_dl(p, attr); --- (5)
}
void __setparam_dl(struct task_struct *p, const struct sched_attr *attr)
{
struct sched_dl_entity *dl_se = &p->dl;
dl_se->dl_runtime = attr->sched_runtime; --- (6)
dl_se->dl_deadline = attr->sched_deadline;
dl_se->dl_period = attr->sched_period ?: dl_se->dl_deadline;
dl_se->flags = attr->sched_flags;
dl_se->dl_bw = to_ratio(dl_se->dl_period, dl_se->dl_runtime);
dl_se->dl_density = to_ratio(dl_se->dl_deadline, dl_se->dl_runtime);
}- 首先调用sched_dl_overflow检查dl调度器是否有足够带宽接受新任务,如果带宽不足则返回EBUSY。
- 调用__setscheduler。
- 继续调用__setscheduler_params。
- 设置任务所述的sched class为dl_sched_class。
- 调用 __setparam_dl。
- 在 __setparam_dl中,设置sched_dl_entity的内容。
至此,一个能满足实时需求,且系统带宽可以支持的任务就创建好了。
在实际工程中,有工作很繁重的任务,比如ratio=runtime/period接近为1,也有工作很轻松的任务,ratio=runtime/period远远小于1,在这种情况下,我们通常会使用cgroup将这样的大小任务分别运行在不同的CPU核上,以达到最好的带宽利用:
# cd /sys/fs/cgroup/cpuset/
# mkdir partition
# cd partition/
# echo 1 > cpuset.cpu_exclusive
# echo 0 > cpuset.mems
# echo 0 > cpuset.cpus
# echo $$ > tasks 完成上面的准备工作之后,最后一步就是在shell中启动deadline任务。
注意,使用dl调度器的任务不支持CPU Affinity,所以绑定CPU的话,只能使用cgroup。
dl调度器的运行日志分析
最后,我们使用社区的测试工具cyclicdeadline,结合ftrace log,来看一下dl调度器具体的运行状况,cyclicdeadline和ftrace具体的原理和操作将在后面的章节进行讲述,本节只讲述本节使用的命令和日志分析。
为简便起见,我们只在CPU3上创建一个dl实时任务,具体信息如下:
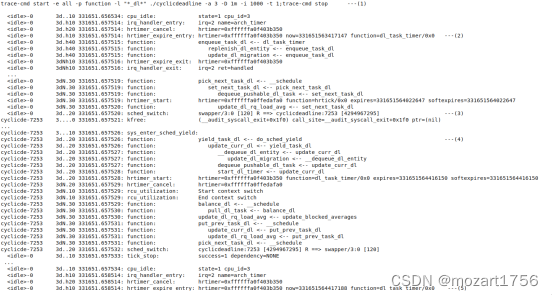
- 首先我们使用cyclicdeadline创建了一个实时任务,该任务的period和deadline为1000us,runtime为600us,同时使用trace-cmd来打开ftrace做日志记录。
- 在331651.657514,dl_timer到时,触发dl_task_timer,开始一个新的周期。
- dl_task_timer将该实时任务入队,然后dl调度器在中断返回是进行上下文切换,该实时任务开始运行。
- 该实时任务完成工作,调用sched_yield放弃CPU。
- 上一个中断的1000us之后,也就是331651.658514,下一个周期开始。
这种情况是实时任务调用sched_yield主动放弃CPU,如果出现任务超出runtime,调度器如何处理呢,我们将cyclicdeadline代码中的sched_yield注释掉,看看dl调度器如何工作:
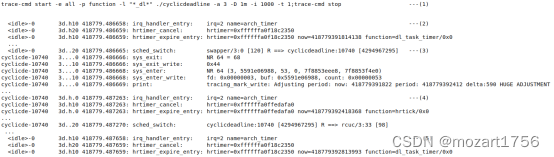
- 我们仍然使用cyclicdeadline创建了一个实时任务,该任务的period和deadline为1000us,runtime为600us,但这次我们模仿一个工作繁重的任务,cyclicdeadline不会调用sched_yield来主动放弃CPU,同时使用trace-cmd来打开ftrace做日志记录。
- 在418779.486658,dl_timer到时,触发dl_task_timer,开始一个新的周期。
- dl_task_timer将该实时任务入队,然后dl调度器在中断返回是进行上下文切换,该实时任务开始运行,该任务在418779.486666开始运行。
- 600us以后,也就是418779.487263,hrtick到时,dl调度器调用task_tick_dl,将该任务调离调度队列。
- 在418779.487658,也就是上一个周期的1000us之后,新的周期开始。

















 887
887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









