







原班人马再度出手,用单一模型统一所有底层控制任务,把“画的饼”给实现了。
前言
上回咱们聊完何泰然那套开山之作(传送门),我还吐槽说OmniH2O那个“Omni”(全能)的前缀,有点画饼的意思。结果没过多久,原班人马就带着HOVER杀回来了。
这感觉,就像是来兑现当初吹过的牛。

(现在跟英伟达GEAR团队合作,连项目主页都炫酷了几个level)
今天,咱们就来深扒一下HOVER,看看它到底是如何进化的。
一、HOVER的核心哲学:别再切换模型了!给我一把“瑞士军刀”!
先聊聊这帮大佬想解决的痛点:控制器不统一。
在HOVER之前,我们是怎么让机器人干不同活的?答案通常是:“状态机 + 模型切换”。
- 想让机器人走路?加载一个吃
root_velocity的locomotion_policy.onnx。 - 想让它挥手操作?停下来,切换到
manipulation_policy.onnx。
这套逻辑,简单直接,但笨重得像上个世纪的软件。每种任务对应一个“专才”模型,机器人大脑里跟装了好几个虚拟机一样,用哪个就启动哪个。不仅资源占用高,而且模型间的切换往往会产生不连贯的“卡顿”,体验极差。
HOVER上来就掀了这张桌子。它的核心思想极其暴力:
只用一个模型,解决所有底层控制任务。
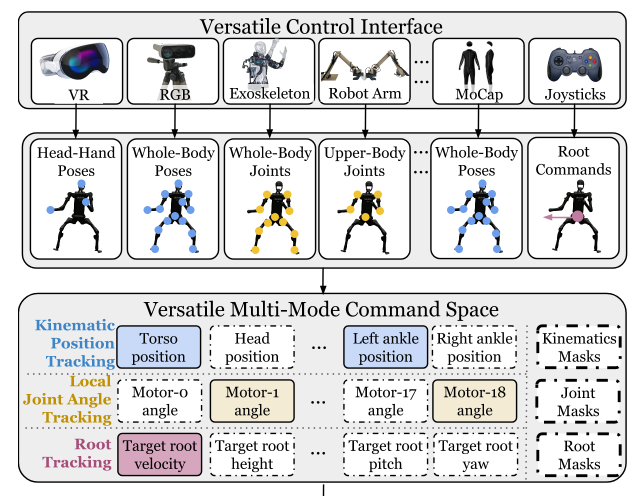
什么叫底层控制任务?简单说,就是人形机器人所有运动的“原子操作”。HOVER把它归纳为三大类:
- 运动学位置跟踪 (Kinematic Position Tracking):给个世界坐标,让手、脚、头移动到那里去。
- 局部关节角度跟踪 (Local Joint Angle Tracking):直接控制每个电机转多少度。
- 根部状态跟踪 (Root Tracking):控制躯干的移动速度、转向和高度。
HOVER的目标,就是让这一个神经网络,既能听懂“往前走,速度0.5m/s”,又能理解“左手移动到(x,y,z)”,甚至能同时执行“下半身按指定速度巡航,上半身模仿我做一套广播体操”。
这就是“瑞士军刀”HOVER,用一个“通才”模型,兼容多种控制模式。
二、随机掩码如何“倒逼”出全能选手?
HOVER的训练框架,基本就是OmniH2O那套成熟的“教师-学生”蒸馏范式,底子稳得一批。这里就不再赘述了,不熟悉的同学可以回头看我开头说的上一篇文章。作者在论文里也大方承认,很多设计都是follow前作,一脉相承的。
开始我就在想:一个神经网络,输入维度固定,怎么处理类型和数量都不同的指令?
第一步:构建一个“超集”指令空间
HOVER定义了一个大而全的指令向量 state_cmd,把前面说的三类原子操作全都塞了进去。大概长这样:
state_cmd = [
# --- Part 1: Kinematic Position Tracking ---
target_head_pos(x,y,z), target_l_hand_pos(x,y,z), ..., target_r_ankle_pos(x,y,z),
# --- Part 2: Local Joint Angle Tracking ---
target_joint_0_angle(rad), target_joint_1_angle(rad), ..., target_joint_18_angle(rad),
# --- Part 3: Root State Tracking ---
target_base_vel(vx, vy), target_base_yaw_rate(rad/s), target_base_height(m), ...
]
这个向量的维度是固定的。无论你用哪种控制模式,传给网络的都是这个“全家桶”。
这部分源码长这样,非常优雅:
observations = torch.cat(
[
kinematic_command,
joint_command,
root_command,
mask,
],
dim=1,
)
第二步:引入“双层掩码”机制
这才是点睛之笔,在训练的每一步,系统都会随机生成一个热独编码的二进制Mask向量,维度和 state_cmd 一样。用这个Mask去处理教师给出的完整指令,再喂给学生。
核心公式大概为:
student_goal = SparsityMask ⊙ (ModeMask ⊙ g-upper, ModeMask ⊙ g-lower)

论文里把Mask分成了两层:
- 模式掩码 (Mode Mask):在“位置跟踪”、“角度跟踪”、“根部跟踪”这三大类模式中选择一个或多个激活。比如,这次只练“根部跟踪”。
- 稀疏掩码 (Sparsity Mask):在选定的模式内部,再随机选择具体跟踪哪个部位。比如,在“位置跟踪”模式下,这次可能只激活左手和右脚的跟踪指令。
Mask里的 1 代表“这部分指令可见”,0 则代表“这部分指令抹掉,你自己看着办”。
三、怎么训练?“填空题”大师的诞生!
训练过程就非常有意思了。
教师(Oracle Policy)是个全知全能的神,它能看到完整的“指令全家桶”。但它教给学生的方式,不是把标准答案直接塞过去,而是玩起了“完形填空”。
在每一轮训练(episode)开始时,系统会随机生成模式掩码和稀疏掩码。这意味着,学生策略在这一轮可能只收到了“左手位置”和“前进速度”这两个指令,其他所有目标都被掩码置零,对它来说是不可见的。
这就像什么呢?一个驾校教练在教你开车。
这位教练能看到仪表盘上所有的信息:时速、转速、油量等等,但他不会让你一直盯着看。他会随机地把速度表给你遮住,让你凭感觉和窗外参照物来判断车速;或者把转速表遮住,让你用耳朵听引擎声来换挡。
通过这种“信息残缺”的极限拉扯,学生策略被迫学会了在任何“指令组合”下都能做出最优的全身协调动作。它不再依赖于某一种特定的指令,而是真正理解了运动的本质。最终,它成了一个能应对各种“填空题”的大师。
这套机制其实有点像RL学步态那个味道了,机器人只知道一个速度跟踪,但却需要自己探索出完整的步态动作,在HOVER就是机器人只知道一部分跟踪信息,要在保证姿态良好的情况下,模仿出整个教师的动作。
最终得到的模型强大之处在于:你可以任意组合控制模式!
- 想只控制上半身?屏蔽下半身指令,让机器人自主维持平衡。
- 想边走路边挥手?同时发送速度指令和手部轨迹指令。
- 想精确控制步态?激活下半身关节角跟踪模式。
四、通才 vs 专才:一个意外又情理之中的发现
最让我觉得有点反直觉的是实验结果。按理说,一个为特定任务训练的专才模型,在它的主场应该表现最好。但HOVER这个“通才”模型,在切换到特定模式(比如只做OmniH2O的动作跟踪)时,其性能指标居然比专门训练的OmniH2O专才模型还要好!
但细想又在情理之中。
专才模型,比如一个纯粹的步态控制器,它的眼里只有“走路”这一件事。它的学习过程可能会过拟合到与走路强相关的特征上,对于一些更普适的物理规律(比如意外扰动下的平衡恢复)可能学得不够好。
而HOVER这个“通才”,在训练中见识了太多妖魔鬼怪的指令组合,饱受算法工程师的毒打,被迫学习了如何在各种极端、不协调的任务要求下,依然维持身体的稳定和运动的流畅。这种从海量多样化任务中提炼出的“通用运动基础”,反而让它在执行任何单一任务时都显得游刃有余,鲁棒性更强。
五、总结一下
聊到这里,HOVER的影响力已经超越了一篇学术论文。它实际上是在探索人形机器人的生态问题。
一个强大的、统一的、接口灵活的底层控制器,就像是机器人的Linux内核。上层的应用开发者(比如做遥操作的、做自主导航的、做人机交互的)再也无需关心底层的动力学细节,他们只需要根据自己的需求,组合模式掩码和稀疏掩码,调用标准接口,就能让机器人动起来。
这无疑会极大地降低开发门槛,促进应用生态。难怪英伟达的Isaac Lab直接把HOVER作为模仿学习的标杆案例。这影响力,已经超越了学术圈的范畴。
最后再聊点代码上的发现吧
先看官方Demo的配置:
# "omnih2o":
# {"upper_body": [".*hand.*link.*", ".*head.*link.*"]}, # 注意:没有包含速度和下半身跟踪!
distill_mask_sparsity_randomization_enabled = False # 关闭稀疏随机化!
distill_mask_modes = {"omnih2o": DISTILL_MASK_MODES_ALL["omnih2o"]}
等一下…这操作意味着什么?
关闭稀疏掩码随机化,并且只固定一种模式(比如OmniH2O模式,它只包含手和头的跟踪,没有任何根速度或关节角度指令),所有其他的指令项在训练中将永远被mask为0,虽然最后跑下来效果ok,但这…这不就等于把HOVER又退化成一个纯纯的OmniH2O了吗?
再看README也是建议关闭稀疏掩码随机化(说“开启后动作会怪异”)。
理论中的情况应该是这样:
distill_mask_sparsity_randomization_enabled = True
distill_mask_modes = DISTILL_MASK_MODES_ALL
所以这是为了保证Demo的稳定性而做的简化?还是说,在实际工程中,完全的随机化训练仍然存在一些尚未解决的挑战?这里面的坑,恐怕还得我们自己在实践中慢慢踩了。
虽然代码实现上似乎留了一些待解的谜题,但代码的完整性、可读性比前作可强太多了(泪目),真的让你一键跑起来,而且不难切换到自己的模型上。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









