







目标检测 Faster R-CNN 论文笔记
论文名称:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks,点我下载
Faster R-CNN算法基于R-CNN和Fast R-CNN改进得来,如果你对它们尚不了解,可以看看 R-CNN 和 Fast R-CNN 的相关知识。
0. 摘要
- R-CNN的提出开创了目标检测新篇章,随后的SPPnet和Fast R-CNN明显减少了R-CNN的训练和测试时间。现在,减少时间的瓶颈就在于候选区域生成过程,生成候选区域的时间比检测网络要高出好几个数量级。
- 针对这个问题,作者提出了 RPN(Region Proposal Network) 代替之前的 Selective Search 算法。RPN与检测网络共享特征,因此在候选区域上几乎不耗费额外时间。并且由于RPN的fully-concolutional特征,它可以实现end-to-end训练,比之前的Selective Search要快了不少。
- 使用VGG-16模型时,GPU上实现了5fps的速度,且在VOC 2007的mAP达到73.2%,VOC 2012 的mAP达到70.4%,每张图片只用300个候选区域。
1. 简介和相关工作
- 这一块没有什么需要特别交代的,该说的在摘要里已经说过了,因此略去。对此有兴趣的可以翻翻原文。
2. Faster R-CNN分析
- RPN网络只是Faster R-CNN提取区域的部分。整个Faster R-CNN框架如下:
- 作为对比,Fast R-CNN框架如下,结构用框图不好描述,具体检测过程见http://blog.csdn.net/cyiano/article/details/70141957#t3:
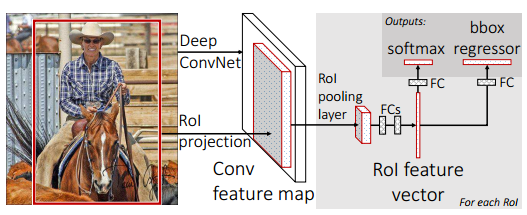
- 可以发现,候选区域的提取从预处理(SS)变成了后续处理(RPN)。RPN完全包含在整个卷积神经网络之中,模型大大得到了简化。

CNN部分
- CNN部分采用在分类方面效果良好的网络就足够了。作者选择了两种网络:ZF 和 VGG。前者有5层可以共享参数的卷积层,而后者有13层。CNN部分的输出应该是一个W*H*R的特征图。
RPN部分
RPN部分的工作原理用论文中的插图就可以说清楚了。RPN主要涉及到了两个重要的操作:Sliding Window 和 Translation-Invariant Anchors。:
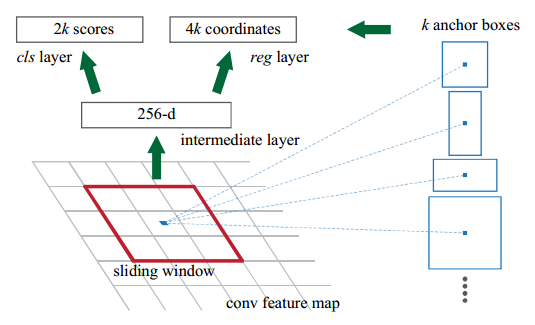
Sliding Window
- Sliding Window我们再熟悉不过了。早期的区域候选算法就是基于滑动窗,卷积神经网络的卷积层操作也多少有点滑动窗的影子。给定一定步长,让窗口(作者设其大小为3*3)遍历整个feature map,每个窗口都将被映射成低维的特征向量(256-d for ZF and 512-d for VGG)。
Translation-Invariant Anchors
- Translation-Invariant具体含义是什么本人不太清楚。。。我猜测意思可能是从候选区域转换到图片(边界框)的过程不变,也就是说每一个候选区域的转换过程都共享同一组参数。
- 对于每个sliding-window location,网络同时预测k个候选框(作者设K=9),它们的中心和滑动窗口中心是一样的,这9个候选框就是所谓的“Anchors”。既然如此,reg layer将生成4k个输出(k个框,每个框用4个参数描述),cls layer生成2k个输出(每个框有两个scores,分别描述是物体/不是物体的可能性,至于为什么要用两个分数来评判,不是很清楚)。
损失函数部分
- 训练时,有两类anchors被标记为1:与某个真实框IOU最大的和与某个真实框IOU大于0.7的;IOU小于0
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 496
496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









