







 本文实现并测试了PCA和LDA两种降维方法,结合KNN分类器评估降维后的鸢尾花数据集分类效果。通过比较自定义实现与sklearn库的PCA和LDA,展示了不同维度下KNN分类的准确率变化。实验结果显示,降维有助于提升分类效率,同时验证了降维方法的有效性。
本文实现并测试了PCA和LDA两种降维方法,结合KNN分类器评估降维后的鸢尾花数据集分类效果。通过比较自定义实现与sklearn库的PCA和LDA,展示了不同维度下KNN分类的准确率变化。实验结果显示,降维有助于提升分类效率,同时验证了降维方法的有效性。
1.pca.py
import numpy as np
from matplotlib import pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
class pca(object):
def __init__(self, x, components=0.9):
"""
输入要降维的矩阵x
矩阵大小m*n,m为样本个数,n为特征维度
proportion:如果小于1 为保留的特征占比
如果大于1 为保留的特征维度
"""
self.x = x
self.components = components
self.m, self.n = np.shape(x) # 记下降维矩阵的样本数和特征维度
self.pcaData = None
def get_average(self):
average = np.mean(self.x, axis=0) # 对数组第0个维度求均值,就是求每列的均值 得到每个特征的平均 1*n
# average = np.tile(average, (self.m, 1)) # 得到均值矩阵 m*n
return average
def zero_mean(self, ave):
"""
零均值化特征矩阵m*n,m为样本个数,n为特征维度
:return: zero_mean 0均值矩阵
"""
zero_mean = self.x - ave
return zero_mean
def start_pca(self):
"""
进行PCA降维
:return:
finalData_, reconMat_:降维后的数据和重构的数据
"""
ave = self.get_average()
zero_m = self.zero_mean(ave)
covX = np.cov(zero_m, rowvar=False) # 计算零均值化后的协方差矩阵(一行为一个样本),得到n*n协方差矩阵(即特征之间的相关度)
eigVals, eigVects = np.linalg.eig(covX) # 求解协方差矩阵的特征值和特征向量
index = np.argsort(-eigVals) # 按照特征值进行从大到小排序
eigVals_ = eigVals[index] # 得到重新排序的特征值
eigVals_ = np.asarray(eigVals_).astype(float)
featSum = np.sum(eigVals_)
featSum_ = 0.0
k = 0
if 0 < self.components < 1: # 如果传进来的参数是特征占比(默认0.9),计算所需要保留的维度,直到保留特征占比到设定值为止
for i in range(self.n):
featSum_ = featSum_ + eigVals_[i]
k = k + 1
if featSum_ / featSum > self.components:
break
print('保留的特征占比为', self.components)
print('保留了前%d个维度' % k)
if self.components >= 1:
assert self.components % 1 == 0, "if proportion≥1,it equals to your target dimension! It must be integer!"
featSum_ = 0.0
k = self.components
for i in range(k):
featSum_ = featSum_ + eigVals_[i]
proportion = featSum_ / featSum * 100
print('保留的特征占比为', proportion)
print('保留了前%d个维度' % k)
selectVec = np.mat(eigVects[:, index[:k]]) # 选出前k个特征向量,保存为矩阵
final_data = zero_m * selectVec # 低维特征空间的数据
reconData = (final_data * selectVec.T) + ave # 重构数据
finalData_ = np.asarray(final_data).astype(float)
reconMat_ = np.asarray(reconData).astype(float) # 重构了的数据,先不返回
self.pcaData = finalData_
# return finalData_, reconMat_ # 返回降维以后的数据、重构以后的数据
return finalData_
def plot_2D_feat(self, label):
"""
绘制前两个维度的图像,并和sklearn中的pca方法进行对比
:param label: 标签
:return:
"""
assert self.pcaData is not None, "please start pca before plot" # 抛出异常
assert len(self.pcaData) == len(label), "the length of label must be equal to your data"
plt.figure(figsize=(8, 4))
plt.subplot(121)
plt.title("my PCA")
plt.scatter(self.pcaData[:, 0], self.pcaData[:, 1], c=label)
plt.xlabel('x1')
plt.ylabel('x2')
# 绘制sklearn的pca图像
skl_pca = PCA(n_components=self.components).fit_transform(self.x)
plt.subplot(122)
plt.title("sklearn_PCA")
plt.scatter(skl_pca[:, 0], skl_pca[:, 1], c=label)
plt.savefig("PCA.png", dpi=600)
plt.xlabel('x1')
plt.ylabel('x2')
plt.show()
# # 用鸢尾花数据集测试pca
# iris_data = datasets.load_iris()
# all_data = iris_data['data']
# all_label = iris_data['target']
# flower_name = iris_data['target_names']
#
# pca_data = pca(all_data, 2)
# finalData = pca_data.start_pca()
#
# # print(finalData[0])
# # print(reconData[0])
# # print(val_data[0])
# pca_data.plot_2D_feat(all_label)
2.lda.py
import numpy as np
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
class lda(object):
def __init__(self, data, label, n_dim):
"""
初始化lda
:param data: 要降维的数据
:param label: 数据标签
:param n_dim: 保留的维度
"""
self.X = data
self.y = label
self.n_dim = n_dim
self.clusters = np.unique(label)
self.lda_data = None
assert n_dim < len(self.clusters), "your target dimension is too big!"
assert len(self.X) == len(self.y), "the length of label must be equal to your data"
def zero_mean(self, x):
"""
零均值化特征矩阵m*n,m为样本个数,n为特征维度
:return: zero_mean 0均值矩阵
"""
average = np.mean(x, axis=0) # 对数组第0个维度求均值,就是求每列的均值 得到每个特征的平均 1*n
zero_mean = x - average
return zero_mean
def get_Sw(self): # 求类内散度矩阵
Sw = np.zeros((self.X.shape[1], self.X.shape[1])) # 初始化散度矩阵
for i in self.clusters: # 对每个类别分别求类内散度后相加
data_i = self.X[self.y == i]
Swi = np.mat(self.zero_mean(data_i)).T * np.mat(self.zero_mean(data_i))
Sw += Swi
return Sw
def get_Sb(self): # 求类间散度矩阵,即全局散度-类内散度
temp = np.mat(self.zero_mean(self.X))
St = temp.T * temp
Sb = St - self.get_Sw()
return Sb
def start_lda(self):
"""
开始lda降维, 并记录保留的特征占比
:return:
data_ndim:降维后的数据
"""
Sb = self.get_Sb()
Sw = self.get_Sw()
S = np.linalg.inv(Sw) * Sb # 计算矩阵Sw^-1*Sb
eigVals, eigVects = np.linalg.eig(S) # 求S的特征值,特征向量
index = np.argsort(-eigVals) # 按照特征值进行从大到小排序
# 计算保留的特征占比
# eigVals_ = eigVals[index] # 得到重新排序后的特征值
# eigVals_ = np.asarray(eigVals_).astype(float)
# featSum = np.sum(eigVals_)
# featSum_ = 0.0
# for i in range(self.n_dim):
# featSum_ = featSum_ + eigVals_[i]
# proportion = featSum_ / featSum * 100
# print('the proportion of remained feature is:', proportion)
w = np.mat(eigVects[:, index[:self.n_dim]]) # 选出前n_dim个特征向量,保存为矩阵
data_ndim = np.asarray(self.X * w).astype(float)
self.lda_data = data_ndim
return data_ndim
def plot_2D_feat(self):
"""
绘制前两个维度的图像,并和sklearn中的pca方法进行对比
"""
assert self.lda_data is not None, "please start pca before plot" # 抛出异常
plt.figure(figsize=(8, 4))
plt.subplot(121)
plt.title("my LDA")
plt.scatter(self.lda_data[:, 0], self.lda_data[:, 1], c=self.y)
plt.xlabel('x1')
plt.ylabel('x2')
# 绘制sklearn的lda图像
skl_lda = LinearDiscriminantAnalysis(n_components=self.n_dim).fit_transform(self.X, self.y)
plt.subplot(122)
plt.title("sklearn_LDA")
plt.scatter(skl_lda[:, 0], skl_lda[:, 1], c=self.y)
plt.savefig("LDA.png", dpi=600)
plt.xlabel('x1')
plt.ylabel('x2')
plt.show()
return 0
# # 用鸢尾花数据集测试lda降维效果
# iris = load_iris()
# X = iris.data
# Y = iris.target
# lda_ = lda(X, Y, 2)
# data_1 = lda_.start_lda()
# print(data_1.shape)
# lda_.plot_2D_feat()
# # data_1 = lda(X, Y, n_dim=2)3.knn.py
import numpy as np
from math import sqrt
from collections import Counter
from sklearn import datasets
from sklearn.model_selection import train_test_split
class KNNClassifier:
def __init__(self, k):
"""
初始化knn分类器,k=近邻个数
"""
assert k >= 1, "k must be valid" # 抛出异常
self.k = k
self.X_train = None # 训练数据集在类中,用户不能随意操作,故设置为私有
self.y_train = None
self.result = None
def fit(self, X_train, y_train):
"""根据训练数据集X_train和y_train训练kNN分类器"""
assert X_train.shape[0] == y_train.shape[0], "the size of X_train must equal to the size of y_train"
assert self.k <= X_train.shape[0], "the size of X_train must be at least k."
self.X_train = X_train
self.y_train = y_train
return self # 模仿sklearn,调用fit函数会返回自身
def predict(self, X_test):
"""给定待预测数据集X_predict, 返回结果向量"""
assert self.X_train is not None and self.y_train is not None, "must fit before predict!"
assert X_test.shape[1] == self.X_train.shape[1], "the feature number of X_predict must be equal to X_train"
# 预测X_predict矩阵每一行所属的类别
pred_result = [self._predict(x) for x in X_test]
self.result = np.array(pred_result)
return self.result # 返回的结果也遵循sklearn
def _predict(self, x):
"""给定单个待预测的数据x,返回x_predict的预测结果值"""
# 先判断x是合法的
assert x.shape[0] == self.X_train.shape[1], "the feature number of x must be equal to X_train"
# 计算新来的数据与整个训练数据的距离
distances = [sqrt(np.sum((x_train - x) ** 2)) for x_train in self.X_train]
nearest = np.argsort(distances) # 对距离排序并返回对应的索引
topK_y = [self.y_train[i] for i in nearest[:self.k]] # 返回最近的k个距离对应的分类
votes = Counter(topK_y)
return votes.most_common(1)[0][0]
# 计算准确率
def get_accuracy(self, y_test):
assert self.result is not None, "must predict before calculate accuracy!"
assert y_test.shape[0] == self.result.shape[0], "the label number of test data must be equal to train data!"
correct = 0
for i in range(len(self.result)):
if y_test[i] == self.result[i]:
correct += 1
return (correct / float(len(self.result))) * 100.0
# 用鸢尾花数据集测试knn
# iris_data = datasets.load_iris()
# all_data = iris_data['data']
# all_label = iris_data['target']
# flower_name = iris_data['target_names']
# train_data, val_data, train_label, val_label = train_test_split(all_data, all_label, test_size=0.2,
# random_state=1, stratify=all_label)
# knn_clf = KNNClassifier(k=1)
# knn_clf.fit(train_data, train_label)
# result = knn_clf.predict(val_data)
# acc = knn_clf.get_accuracy(val_label)
# print(result)
# print(val_label)
# print(acc)
4.loadData.py
from scipy.io import loadmat
import numpy as np
from PIL import Image
# from sklearn.model_selection import train_test_split
"""
读取数据 可视化其中任意一张图片
80%训练集,20%测试集
"""
class loadData(object):
def __init__(self, orl_file='../ORLData_25.mat', vehicle_file='../vehicle.mat'):
# 读取数据集
self.orl_data = loadmat(orl_file)
self.vehicle_data = loadmat(vehicle_file)
def get_orl_data(self):
"""
orl_data是一个人脸数据集,特征维数为644维(23*28大小图像),样本数量10*40
:return:
训练集 数据+标签80% 每个人的图像取8张
测试机 数据+标签 20% 每个人的图像取2张
"""
orl_data = self.orl_data['ORLData'].T # 400*645大小,每一行是一个样本,每一列是一维特征
all_data = orl_data[:, 0:-1] # 提取特征
all_data = np.asarray(all_data).astype(float)
all_label = orl_data[:, -1] # 提取标签
all_label = np.asarray(all_label).astype(float)
'''不使用train_test_split'''
# train_data = []
# train_label = []
# val_data = []
# val_label = []
#
# for i in range(40):
# train_data.append(all_data[i * 10:i * 10 + 8, :])
# val_data.append(all_data[i * 10 + 8:(i + 1) * 10, :])
# train_label.append(all_label[i * 10:i * 10 + 8])
# val_label.append(all_label[i * 10 + 8:(i + 1) * 10])
#
# train_data = np.reshape(train_data, [-1, 644])
# val_data = np.reshape(val_data, [-1, 644])
# train_label = np.reshape(train_label, [-1, 1])
# val_label = np.reshape(val_label, [-1, 1])
'''使用train_test_split'''
# 可以随机划分 并且保证划分均匀
# train_data, val_data, train_label, val_label = train_test_split(all_data, all_label, test_size=0.2,
# random_state=1, stratify=all_label)
# c = collections.Counter(val_label) # 观察划分是否平均
# # 可视化图像
# temp = all_data[123, :]
# temp = temp.reshape(23, -1).T
# pil_image = Image.fromarray(temp)
# pil_image.show()
return all_data, all_label
def get_vehicle_data(self):
"""
vehicle数据集,读取了entropy_data(咱也不知道这是个啥)
846个样本,18个特征,4个类别
:return:
训练集 数据+标签80% train_data, train_label
测试机 数据+标签 20% val_data, val_label
"""
UCI_entropy_data = self.vehicle_data['UCI_entropy_data']
data = UCI_entropy_data[0, 0]['train_data']
data = data.T # 转置一下 变成846*19
all_data = data[:, 0:-1]
all_label = data[:, -1]
all_data = np.asarray(all_data).astype(float)
all_label = np.asarray(all_label).astype(float)
# train_data, val_data, train_label, val_label = train_test_split(all_data, all_label, test_size=0.2,
# random_state=1, stratify=all_label)
# c = collections.Counter(val_label) # 观察划分是否平均
return all_data, all_label
5.main.py
from lda import lda
from knn import KNNClassifier
from loadData import loadData
from sklearn.model_selection import train_test_split
import numpy as np
from matplotlib import pyplot as plt
if __name__ == '__main__':
ld = loadData()
classify_orl_data = True
classify_vehicle_data = True
origin_orl_data, orl_label = ld.get_orl_data()
origin_vehicle_data, vehicle_label = ld.get_vehicle_data()
m = 50
orl_acc = []
vehicle_acc = []
for i in range(m):
if i == 0:
continue
if i == len(np.unique(orl_label)):
classify_orl_data = False
continue
if classify_orl_data:
lda_ = lda(origin_orl_data, orl_label, i)
orl_data = lda_.start_lda()
train_data, val_data, train_label, val_label = train_test_split(orl_data, orl_label, test_size=0.2,
random_state=1, stratify=orl_label)
knn_cf = KNNClassifier(1) # 最近邻分类
knn_cf.fit(train_data, train_label)
knn_cf.predict(val_data)
acc = knn_cf.get_accuracy(val_label)
orl_acc.append([i, acc])
# print(acc)
if i == len(np.unique(vehicle_label)):
classify_vehicle_data = False
continue
if classify_vehicle_data:
lda_ = lda(origin_vehicle_data, vehicle_label, i)
vehicle_data = lda_.start_lda()
train_data, val_data, train_label, val_label = train_test_split(vehicle_data, vehicle_label, test_size=0.2,
random_state=1, stratify=vehicle_label)
knn_cf = KNNClassifier(1) # 最近邻分类
knn_cf.fit(train_data, train_label)
knn_cf.predict(val_data)
acc = knn_cf.get_accuracy(val_label)
vehicle_acc.append([i, acc])
# print(acc)
orl_acc = np.asarray(orl_acc)
vehicle_acc = np.asarray(vehicle_acc)
print(orl_acc)
print(vehicle_acc)
plt.figure(figsize=(8, 4))
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.subplot(121)
plt.title("orl_acc")
plt.plot(orl_acc[:, 0], orl_acc[:, 1], label="正确率")
plt.xlabel('保留特征维度')
plt.legend()
plt.grid()
plt.subplot(122)
plt.title("vehicle_acc")
plt.plot(vehicle_acc[:, 0], vehicle_acc[:, 1], label="正确率")
plt.xlabel('保留特征维度')
plt.legend()
plt.grid()
plt.show()
6.可视化结果
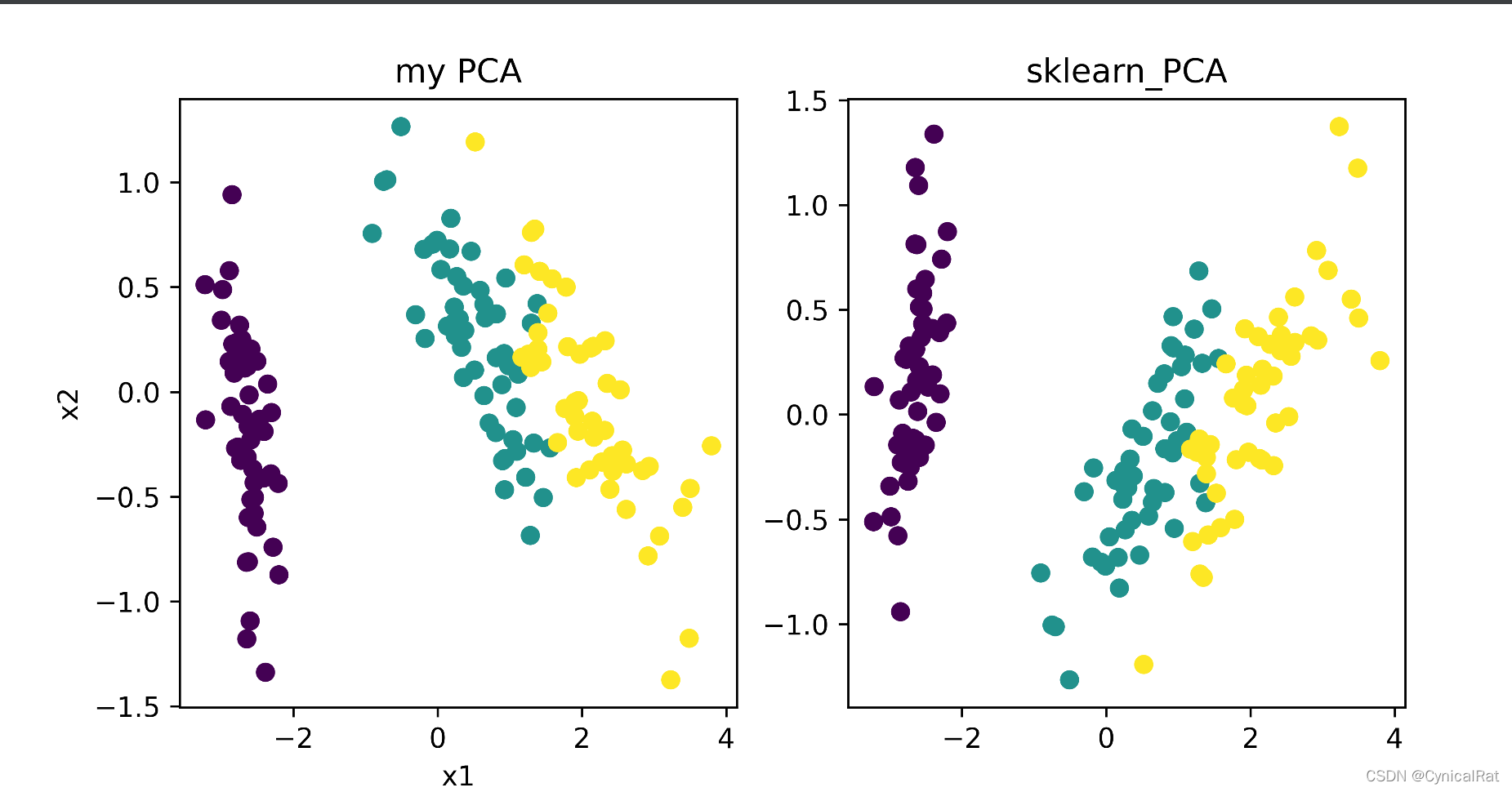
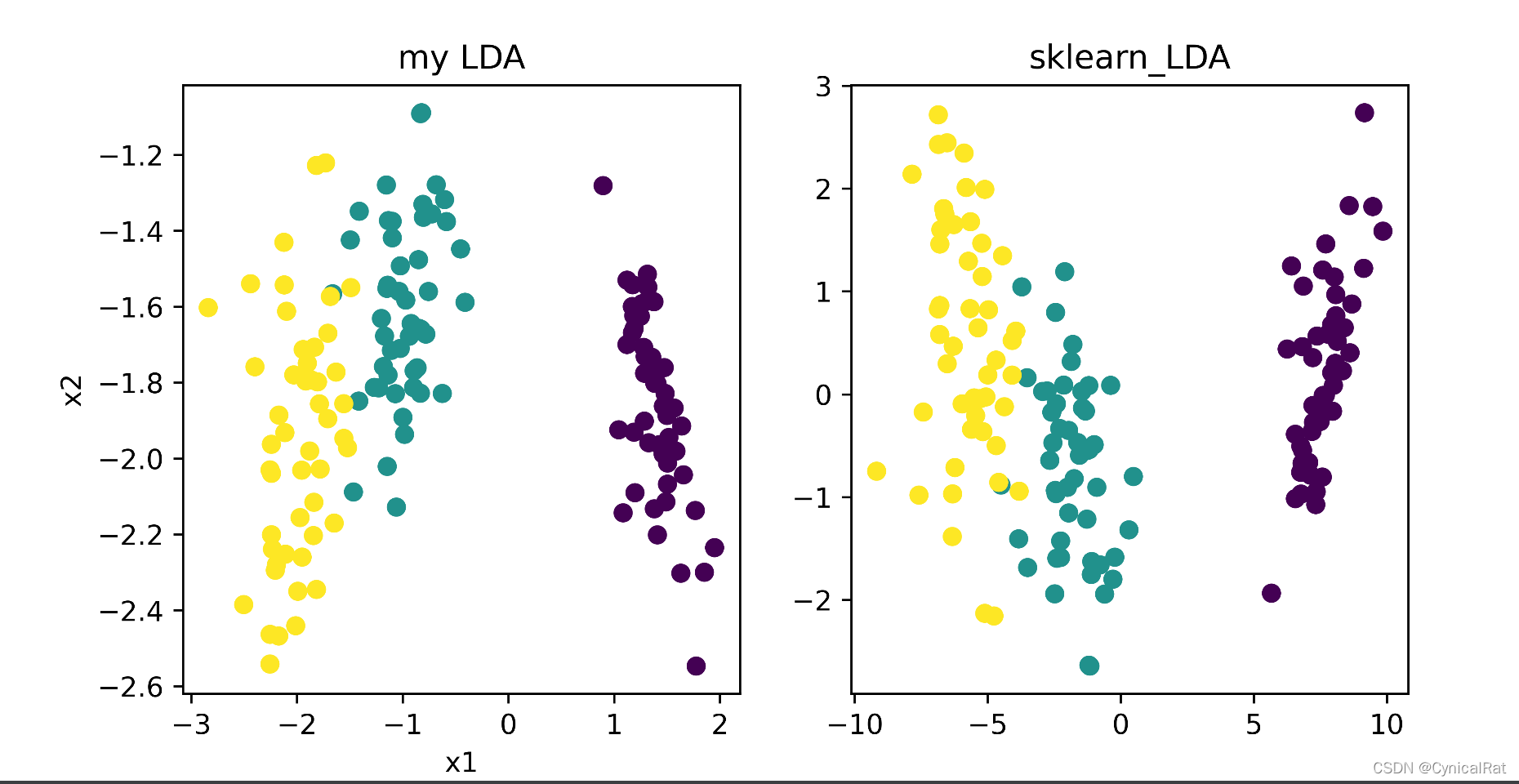
lda降维后最近邻分类效果
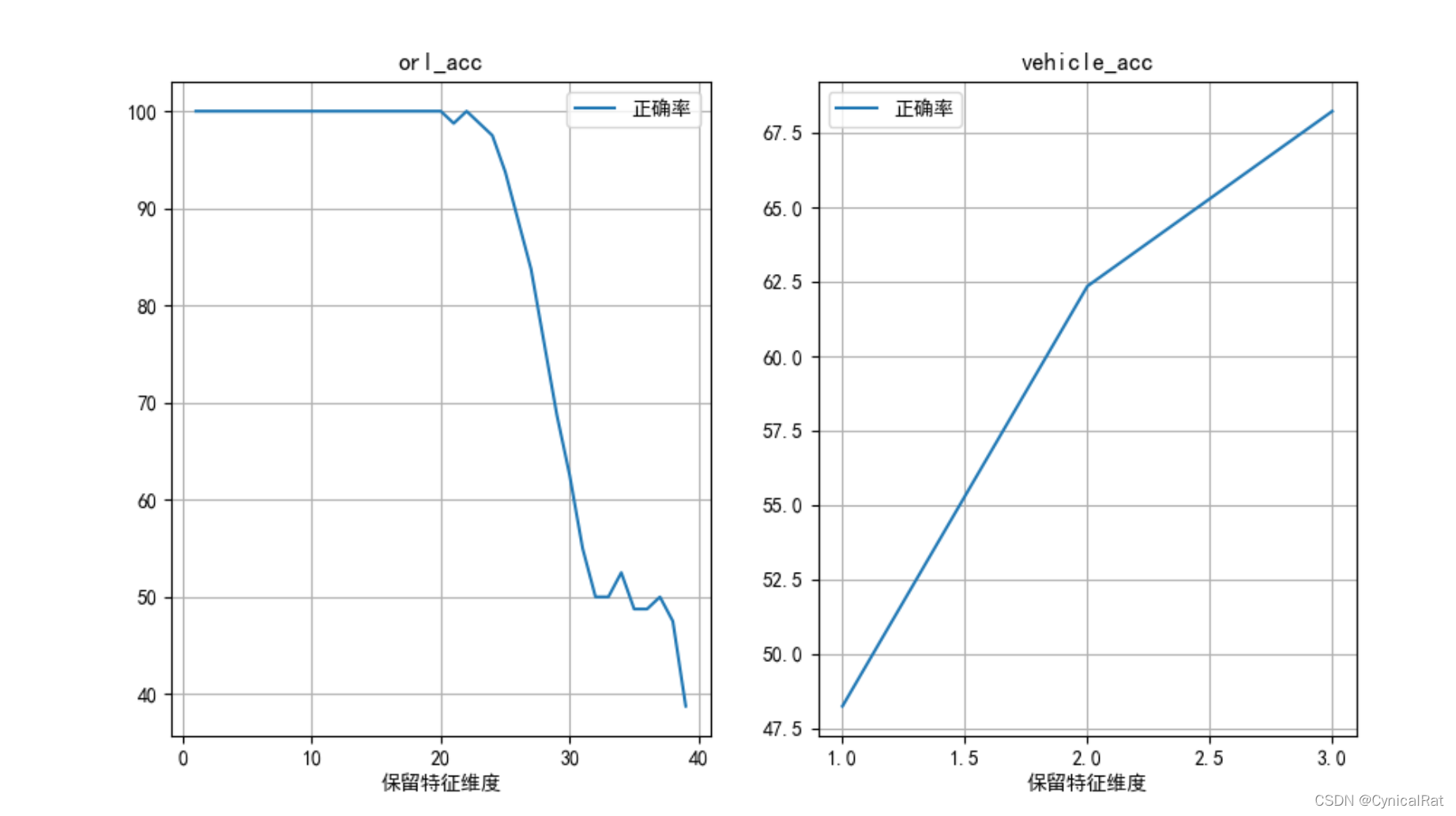
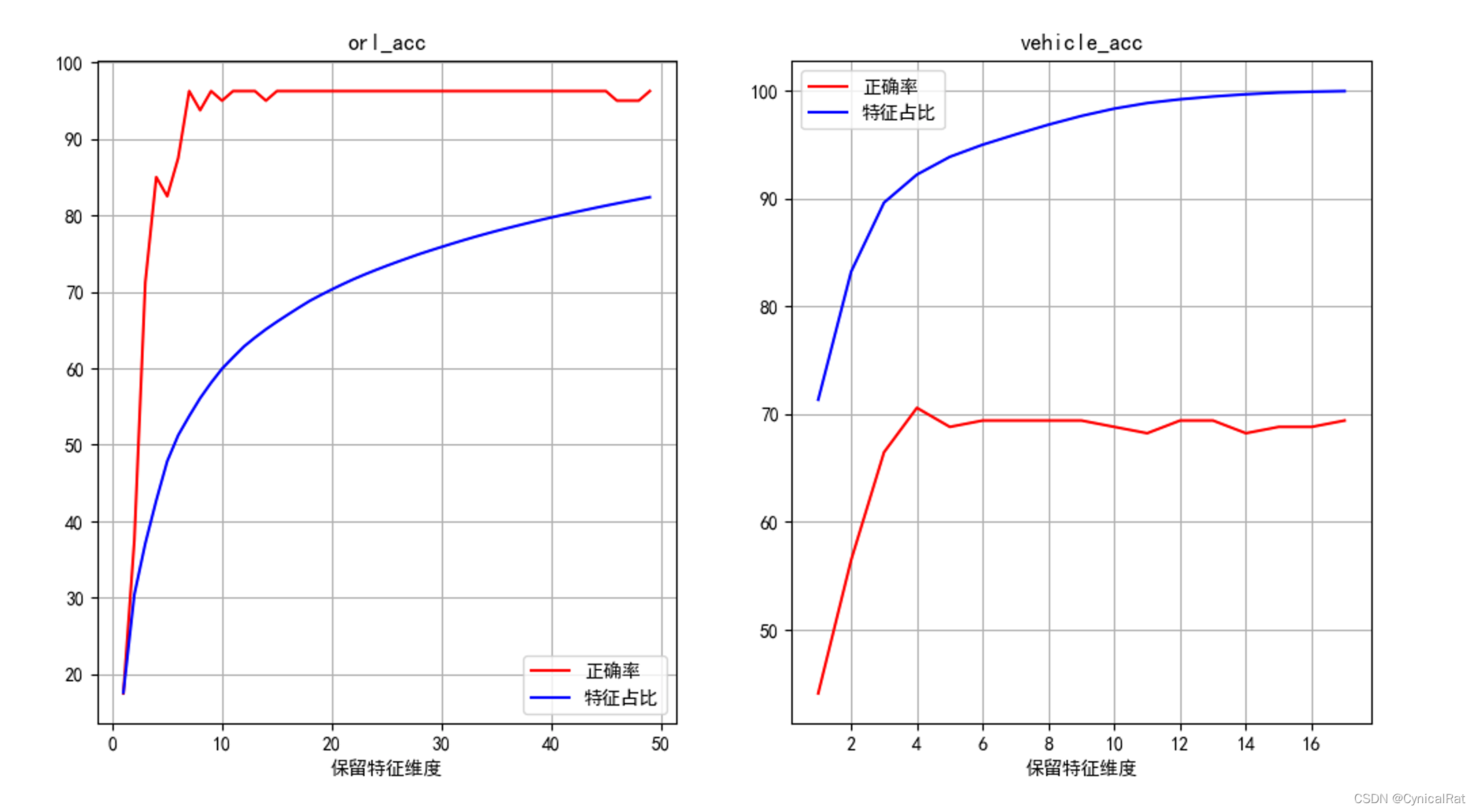
pca降维后最近邻分类效果
使用的数据集:
ORL_Data_25.mat+vehicle.mat
 https://download.csdn.net/download/CynicalRat/53342132
https://download.csdn.net/download/CynicalRat/53342132
















 4673
4673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









