







笔者去年做了一个铸造行业客户的APS(高级计划排产)项目。此项目主要是用遗传算法作为主要思路进行自动排产优化。前段时间看到了几篇关于用强化学习排产的论文,深受启发,于是想用前面客户的实际场景来验证一下强化学习是否可行。
限于篇幅,本文不做强化学习的科普介绍,有兴趣的朋友请自行查阅资料。接下来直接介绍业务场景:
1、客户有7台熔炼炉,作为7台设备进行排产
2、每台熔炼炉每一次都是熔炼10吨铁水
3、每台熔炼炉完成一炉的时间不一样
4、熔炼任务单事先已经按照顺序排好,假设每次排产有20张任务单
5、每个任务单工序数量都是1
以上就是本次案例最基本的场景,实际场景远比这复杂的多,比如工作日历、设备状态、前后工序顺序、熔炼炉互斥规则、熔炼合金顺序规则等;因为强化学习工程化的难点是环境的搭建,所以我只考虑了基本要素,不做过多复杂的处理,也只是检验强化学习算法的效果如何。
状态空间S:{设备平均利用率、任务完成率、设备使用时间离散度}
大部分论文中的状态空间也比上面复杂的多,为了简化模型,我只采取以上三个
动作空间A:{0,1,2,3,4,5,6}
7个数,代表7台设备
奖励R:{每个状态下,取用时最大的那台设备的生产时间,再取相反数}
本次实验的算法是DQN
pytorch环境
下面贴出代码:
import random
import numpy as np
import collections
from tqdm import tqdm
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
class State:
def __init__(self,):
self.n=20 #任务单数量
self.m=7 #熔炼炉数量
self.N=[1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1] #每个任务单工序数量
self.M=[[1,2,3],[4,5,6,7],[1,2,3],[1,2,3],[1,2,3],[1,2,3],[1,2,3],[4,5,6,7],[4,5,6,7],[4,5,6,7],[4,5,6,7],[4,5,6,7],
[1,2,3],[1,2,3],[4,5,6,7],[4,5,6,7],[1,2,3],[1,2,3],[1,2,3],[4,5,6,7]] #每个任务可用设备
self.M_procesingtime=[60,65,70,70,50,60,65] #每台熔炼炉的处理时间,单位是分钟
self.machine_order=[] #机器顺序
self.order_list=[i for i in range(0,self.n) ] #随机生成n以内的数 任务单序号
random.shuffle(self.order_list) #随机打乱任务单顺序
self.machine_matrix=np.matrix(np.zeros((7,20))) #设备加工矩阵
self.procesing_time=np.zeros((1,7)) #每台设备的生产时间
def step_add(self,action):
self.machine_order.append(action)
def matrix(self,):
count_m=np.zeros((1,7)) #计数矩阵,每台设备每指定一次,就加1
#self.step_add(action)
machine_len=len(self.machine_order) #当前机器顺序中有几台设备
for i in range(0,machine_len): #
machine_in_order=self.order_list[i] #对应任务顺序中的第几个任务
m_index=self.machine_order[i]
self.machine_matrix[m_index,int(count_m[0][m_index])]=machine_in_order #设备矩阵的第一行代表第一台设备,每个元素代表任务
count_m[0][m_index]+=1 #计数+1
do=False
if len(self.machine_order)==self.n-1:
do=True
return machine_len
def encoding(self,):
#machine_job_count=[]
for i in range (self.m):
k=0
for j in range(20):
if self.machine_matrix[i,j]>0:
k+=1
time=float((self.M_procesingtime[i])*k) #按照每个设备的额定时间*任务数=处理时间
self.procesing_time[0][i]=time
def feature(self,):
self.encoding()
UKT=np.zeros((1,7))
for i in range(self.m):
if self.procesing_time[0][i] != 0:
UKT[0][i]=1
Uave=sum(UKT[0])/self.m #机器平均利用率
JCRave=len(self.machine_order)/self.n #任务完成率
discrete=(np.max(self.procesing_time[0])-np.min(self.procesing_time[0]))/np.max(self.procesing_time[0]) #整体离散度
sta=[0,0,0]
sta[0]=Uave
sta[1]=JCRave
sta[2]=discrete
return sta
def reward(self,):
re=np.max(self.procesing_time[0])
return -re
def reset(self,):
self.__init__()
st=[0,0,0]
st=np.array(st,dtype=np.float16)
return st
#return st
class ReplayBuffer:
''' 经验回放池 '''
def __init__(self, capacity):
self.buffer = collections.deque(maxlen=capacity) # 队列,先进先出
def add(self, state, action, reward, next_state, done): # 将数据加入buffer
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size): # 从buffer中采样数据,数量为batch_size
transitions = random.sample(self.buffer, batch_size)
state, action, reward, next_state, done = zip(*transitions)
return np.array(state), action, reward, np.array(next_state), done
def size(self): # 目前buffer中数据的数量
return len(self.buffer)
class Qnet(torch.nn.Module):
''' 只有一层隐藏层的Q网络 '''
def __init__(self, state_dim, hidden_dim, action_dim):
super(Qnet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x=x.to(torch.float)
x = F.relu(self.fc1(x)) # 隐藏层使用ReLU激活函数
return F.softmax (self.fc2(x))
class DQN:
''' DQN算法 '''
def __init__(self, state_dim, hidden_dim, action_dim, learning_rate, gamma,
epsilon, target_update, device):
self.action_dim = action_dim
self.q_net = Qnet(state_dim, hidden_dim,
self.action_dim).to(device) # Q网络
# 目标网络
self.target_q_net = Qnet(state_dim, hidden_dim,
self.action_dim).to(device)
# 使用Adam优化器
self.optimizer = torch.optim.Adam(self.q_net.parameters(),
lr=learning_rate)
self.gamma = gamma # 折扣因子
self.epsilon = epsilon # epsilon-贪婪策略
self.target_update = target_update # 目标网络更新频率
self.count = 0 # 计数器,记录更新次数
self.device = device
def take_action(self, state): # epsilon-贪婪策略采取动作
if np.random.random() < self.epsilon:
action = np.random.randint(self.action_dim)
else:
#state = torch.as_tensor(state)
state=torch.from_numpy(state)
#state = torch.tensor([state], dtype=torch.float)
action = self.q_net(state).argmax().item()
return action
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'],
dtype=torch.float)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(
self.device)
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
q_values = self.q_net(states).gather(1, actions) # Q值
# 下个状态的最大Q值
max_next_q_values = self.target_q_net(next_states).max(1)[0].view(
-1, 1)
q_targets = rewards + self.gamma * max_next_q_values * (1 - dones
) # TD误差目标
dqn_loss = torch.mean(F.mse_loss(q_values, q_targets)) # 均方误差损失函数
self.optimizer.zero_grad() # PyTorch中默认梯度会累积,这里需要显式将梯度置为0
dqn_loss.backward() # 反向传播更新参数
self.optimizer.step()
if self.count % self.target_update == 0:
self.target_q_net.load_state_dict(
self.q_net.state_dict()) # 更新目标网络
self.count += 1
lr = 2e-3
num_episodes = 3
hidden_dim = 16
gamma = 0.98
epsilon = 0.4
target_update = 10
buffer_size =5000
minimal_size = 2000
batch_size = 300
device = torch.device("cuda") if torch.cuda.is_available() else torch.device(
"cpu")
env_name = "sheduling"
env=State()
replay_buffer = ReplayBuffer(buffer_size)
state_dim=3
action_dim=7
agent = DQN(state_dim, hidden_dim, action_dim, lr, gamma, epsilon,
target_update, device)
return_list = []
for i in range(50):
with tqdm(total=int(num_episodes ), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes)):
episode_return = 0
state = env.reset()
state_reset=env.reset()
done = False
while (not done):
action = agent.take_action(state_reset)
env.step_add(action)
next_state=env.feature()
reward=env.reward()
ct=env.matrix()
if ct>19:
break
replay_buffer.add(state, action, reward, next_state, done)
#print(replay_buffer.size())
state = next_state
episode_return += reward
if replay_buffer.size() > minimal_size:
b_s, b_a, b_r, b_ns, b_d = replay_buffer.sample(batch_size)
transition_dict = {
'states': b_s,
'actions': b_a,
'next_states': b_ns,
'rewards': b_r,
'dones': b_d
}
agent.update(transition_dict)
return_list.append(episode_return)
if (i_episode + 1) % 1 == 0:
pbar.set_postfix({
'episode':
'%d' % (num_episodes * i + i_episode + 1),
'return':
'%.3f' % np.mean(return_list[-10:])
})
pbar.update(1)
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('DQN on {}'.format(env_name))
plt.show() 在实验之前,我设想的结果是:算法会学习出一个策略,根据状态去选择当前速度最快的那台设备。
实验结果如下图:
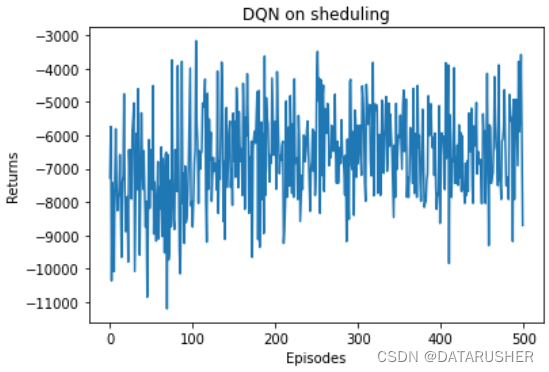
可以看出,returns越来越小,说明整体用时变少,agent慢慢学会了去优先选择速度最快的那台设备;但是缺点也很明显:收敛效果比较差。
改进措施:
1、本次用的是DQN框架,这个框架问题还是比较多,下一次试着用‘演员-评论家’或‘PPO’来实验一下。
2、状态空间、奖励函数的设置过于简单粗暴(也是因为简单粗暴能看出DQN确实能学到更好的策略),应该设计出更更复杂的函数
总结:本次实验基本上是成功了,agent能从最简单的环境中学到如何安排设备去生产使总时间最小;但是实验的设计过于粗糙,算法框架本身也有一些问题。

















 1071
1071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









