







索引是关系型数据库应用系统优化的关键,在早期的应用开发上,我们对索引的认知不足,因此应用系统在索引设计上总是存在很多问题。在2000年以前我给用户做的优化项目中,一般来说通过优化索引就可以解决几乎所有的问题。随着这些年我们在Oracle数据库上应用经验越来越丰富,Oracle数据库的索引优化也越来越纯熟了。不过如果我们把应用系统从Oracle迁移到PostgreSQL上的时候,我们很可能会沿着Oracle数据库索引使用的惯性,那样我们就可能会遇到一些问题了。因为PostgreSQL的索引体系与Oracle有了很大的不同,如果我们还是按照Oracle数据库索引的应用习惯去优化应用,可能使用的不是最佳的方案。
实际上索引优化是应用驱动的,索引的优化一定要根据应用的特点来做专业的设计,否则索引有可能会成为应用系统出现问题的隐患。数据库表上的索引也不是多多益善,特别是对于经常变更的表。对于PostgreSQL数据库来说,因为MVCC带来的死元组问题,如果某张大表上的UPDATE十分频繁,那么这张表上的索引数量越大,存在性能隐患的机会也越大。因此针对这些核心数据表的索引设计尤为关键。如何使用尽可能少的索引来完成对绝大多数SQL的优化是一个十分重要的课题。
PostgreSQL的索引比Oracle更为复杂,因此对于从Oracle数据库迁移到PostgreSQL的应用来说,重新优化索引是保障系统高效运行的十分重要的步骤。为了做好PostgreSQL索引优化,我们首先来看看PostgreSQL的索引有什么不同。
PostgreSQL的索引种类很多,我们今天找一些比较常见的索引来进行讨论。
-
- B-TREE索引
- Hash索引(仅用于等于操作,不支持复合索引,PG 10之前不建议使用)
- BRIN索引(9.5以上,对时序数据有效)
- Partial索引(带where条件的索引)
- 函数索引
- GIN/GIST索引(全文/空间索引)
- 自定义索引
GIN/GIST索引比较特殊,今天我们暂时不讨论,今天重点讨论普通的关系型数据上的索引。B-TREE是我们使用的最多的传统索引,这里就不需要再浪费笔墨来讨论了。Hash索引是PostgreSQL上的一种特殊的索引,针对键值使用一个HASH函数,因此HASH索引只支持等于操作,不支持范围扫描,而且目前HASH索引也不支持复合索引。在Hash索引中,将键值转换为一个HASH值,然后再进行定位,HASH索引不需要枝节点,因此索引的大小会比普通的B-TREE索引要小。其逻辑结构图如下。

BRIN是另外一种体积十分小的索引,这种索引可以用于海量的时序数据,针对物联网应用将会十分有效。BRIN的含义是Block Range Index,顾名思义,是针对块中的值范围进行索引。如下图
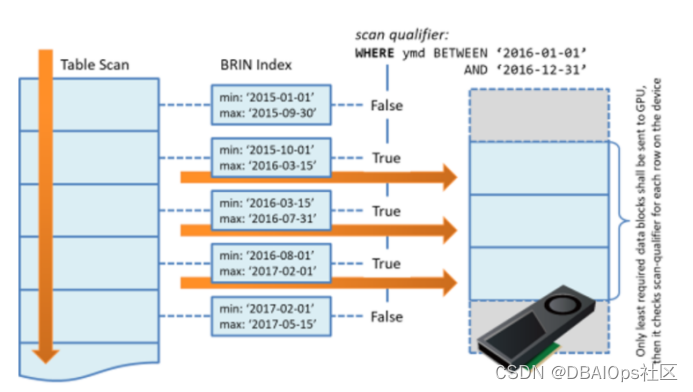
如果某个键值是按照规律增长的,比如时序数据,那么使用BRIN将会十分有效。BRIN中存储了某个PAGE中的键值的最小值与最大值。如果键值存在某种单边增长的趋势,那么创建BRIN索引后,根据这个键值做范围扫描的时候,可以根据BRIN索引找到所需要扫描的数据块,跳过其他的所有数据块,快速的将所需的数据扫描出来。BRIN 在索引数据自然倾向于在表的页中分组或排序的情况,并且数据量十分巨大的情况下很有用。
PostgreSQL的函数索引与Oracle的函数索引十分类似,我们这里就不做过多的讨论了。
部分索引(Partial Index)我们可以看作是一种特殊的函数索引,其存储结构也是B-TREE的。部分索引也称为过滤索引,它只覆盖表数据的一个子集。 它是一个带有 WHERE 子句的索引。部分索引有助于加快查询速度,同时减少索引的大小,这些索引需要更少的存储空间,它们更易于维护,扫描速度更快。如果您通常使用具有常量值的 WHERE 条件,则部分索引很有用。在使用Oracle数据库的时候,我们也经常会遇到在某张表中,我们经常要根据一个独立值很少的STATUS字段来扫描数据的情况。比如在一张表上,STATUS=001的数据是我们要SELECT出来进行处理的,处理后STATUS就变成了002,因此这张表上的STATUS字段值域是倾斜的,001的记录可能只有几百条,而002的记录有上千万条。早期我们认为这种情况使用位图索引比较好,后来发现如果这张表的变化十分大,位图索引会引起十分严重的TX锁冲突。于是我们只能对此字段使用普通的B-TREE索引。而Oracle的优化器会根据bind peeking时不同的值生成不同的执行计划。在Oracle中,优化器虽然比较好的解决了这个问题,不过如果表很大,实际上这个索引中大量的数据(STATUS=002)是没用的。在PostgreSQL中,我们可以通过Partial索引获得更好的效果。
create index idx_partial_status on t_order (status) where status=’001’;
这个索引中只有status=’001’的数据,因此索引十分小。访问的效率也十分高。再复杂一些,我们可以创建类似这样的Partial Index。
create index idx_partial_status on t_order (status) where status in (’001’,’002’);
如果我们的where 条件是status in (’001’,’002’),那么这个索引就能够发挥作用了。
今天我们先讨论这么多。对于自定义索引,是PostgreSQL的一个更为强大的功能,我们可以通过编写插件的方式来实现自己的索引,根据自己的业务逻辑去对数据创建个性化的索引,从而提升应用访问的效率。这个话题比较复杂,我们下一次找一个专题来讨论。正是因为PG的索引十分复杂,因此十分容易出现索引滥用的情况。比如某个字段上原本就有B-TREE索引,为了某个SQL,我们可能又去创建了其他的索引。如果这样,应用系统经过一段时间的运维后,索引会成为一个大问题。索引导致的行锁问题,写应用变慢问题,会让我们更难去解决。因此在做PostgreSQL数据库索引优化的时候,一定要统筹考虑,密切结合应用的特点去做索引设计与优化。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









