







数据建模是一个越来越受到关注的话题,尤其是在数据分析领域。数据建模和流行的数据转换工具 dbt 齐头并进。虽然数据建模是一个已经存在了很长时间的概念,但dbt给了它一个新的开始,并真正重新定义了数据模型是什么。
我喜欢将数据模型视为一组转换,这些转换将数据从原始形式中获取,并将其转换为业务团队可以使用的东西。编写数据模型已成为分析工程师的主要职责,因为他们能够理解技术概念以及业务流程。DBT只是让分析工程师的生活更轻松,允许他们编写模块化的数据模型,其代码可以在不同的功能中重用。
在本文中,我们将讨论 dbt 数据模型的不同层、编写数据模型的最佳实践以及如何使用 dbt 正确测试它们。
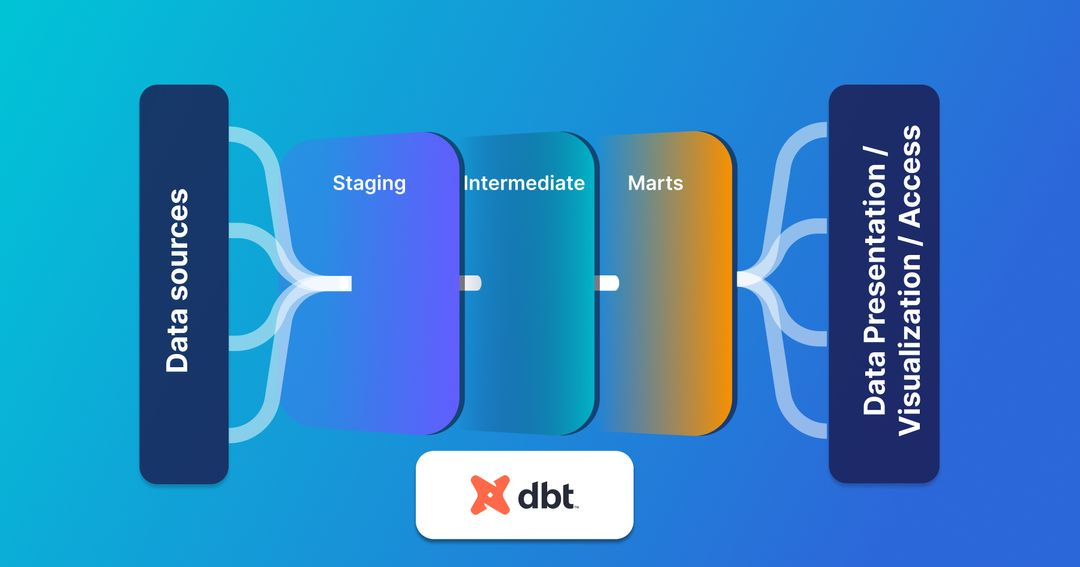
如何组织源数据
每个数据模型都从源数据或直接从外部源引入到数据仓库的数据开始。dbt 不是直接在模型中使用这些原始数据源,而是帮助您在源和模型之间创建额外的层。这样,原始数据的副本始终原封不动地存在于数据仓库中。但是,在模型中使用源之前,需要正确定义它。 定义源 dbt 中的源是在位于源目录根目录的 YAML 文件中定义的。最佳做法是在位于“模型”目录中的“暂存”目录中为每个源创建一个目录。这样,文档就位于该源的相应暂存模型旁边。 在 YAML 文件中,您可以使用源的数据库名称和架构名称定义源,然后为其分配一个要在下游使用的名称。这是源在 source.yml 文件中的样子:
version: 2
sources:
- name: google_sheets
database: raw
schema*: madison_google_sheets
tables:
- name: customer_orders
- name: marketing_campaigns要在 dbt 模型中使用的每个原始数据源都需要在 YAML 文件中引用,如下所示。如果未定义,dbt 将不知道在下游引用该数据库和架构时查找的位置。 引用源 在 dbt 中编写暂存模型时,每个暂存模型都将引用一个源,类似于我们上面定义的源。请记住,只能在暂存模型中引用源。 为了从一个中进行选择,您可以这样称呼它:
{
{ source(‘google_sheets’, ‘customer_orders’) }}源引用需要两条信息 - 源名称和表名称。如果您查看我们定义的 YAML 文件,您可以看到“google_sheets”是指源名称,“customer_orders”是指表名称。
记录源
最后,记录在 dbt 模型中使用的所有源非常重要。这也在定义源的 YAML 文件中完成,就像我们上面写的一样。您不仅可以向源名称添加描述,还可以为每个表名称和列名称添加描述。我建议从一开始就这样做,这样你就不必担心以后会回到它,甚至更糟的是,完全忘记它。 全面的文档将帮助团队中的其他人理解您正在编写的代码。这将使他们能够为项目做出贡献,同时将问题和知识转移保持在最低限度。根据我的经验,文档总是值得预先花费额外的时间,因为它稍后会提供清晰度。 您可以像这样将文档添加到源中:
version: 2
sources:
- name: google_sheets
database: raw
schema*: madis 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2510
2510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









