









目录
简介
Scrapy 是一个基于 Python 的开源网络爬虫框架,它可以帮助开发者快速、高效地构建和管理爬虫。下面我将为你讲解一下 Scrapy 的基本知识。
- 架构:Scrapy 是基于事件驱动的异步框架,它的核心组件有 Engine(引擎)、Scheduler(调度器)、Downloader(下载器)、Spiders(爬虫)和Item Pipelines(管道)等。
- Engine:事件触发和处理的核心,它负责控制整个爬虫的流程。
- Scheduler:负责接收引擎发出的请求,并将请求入队列,以供下载器下载。
- Downloader:负责下载请求的网页内容,并将网页内容返回给引擎。
- Spiders:定义了爬取网页的规则和解析方法,Scrapy中的Spider类需要开发者继承来编写自己的爬虫逻辑。
- Item Pipelines:用于处理从Spider中获取到的数据,如数据清洗、去重、存储等操作。
- 特点:
- 高效快速:Scrapy 使用异步非阻塞式的网络请求,能够并发处理多个请求,提高爬取速度。
- 可扩展性强:Scrapy 提供了很多中间件和扩展点,方便开发者进行功能扩展和定制。
- 支持多种数据存储:Scrapy 可以将爬取到的数据存储到文件、数据库或其他第三方存储中。
- 自动化处理:Scrapy 提供了各种处理请求和响应的方法,可以自动化处理异常、重试、重定向等情况。
- 简单使用步骤:
- 创建一个新的 Scrapy 项目:使用命令
scrapy startproject project_name创建一个新的 Scrapy 项目。 - 编写爬虫:在项目中创建爬虫文件,继承
scrapy.Spider类,编写爬取规则和解析逻辑。 - 运行爬虫:使用命令
scrapy crawl spider_name运行爬虫来启动爬取过程。 - 处理爬取结果:在爬虫中定义 Item 类型并进行处理,并使用 Item Pipeline 进行数据的清洗、存储等操作。
总结,scrapy是一个为了爬取网站数据,提取结构性数据(具有相同标签结构的数据)而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
安装
听说安装scrapy是一件非常非常复杂的事情,不知道是不是前几天我跟Python斗智斗勇一直该版本让他现在非常的老实还是怎么回事,我直接拿下了哈哈哈哈哈哈哈哈哈哈哈哈^_^
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple/
可能的报错:
(1)building ' twisted.test.raiser ' extension
可以到
https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
cp是Python版本,
这个链接下载,然后应该就可以解决85%的错误了。
下载完成之后,使用pip install twised的路径名安装,切记安装完成之后再次安装scrapy
(2)报错2 提示升级pip
运行下面的pip升级指令
Python -m pip install --upgrade pip
(3)报错3 Win32错误
pip install pypiwin32
(4)使用 anaconda
然后在pycharm中引用anaconda的Python.exe
基本使用
1. 创建爬虫的项目
到cmd命令行中创建
scrapy startproject 项目名字
注意:项目名字:不可以使用数字开头,也不能包含中文
创建成果的效果如下

2. 创建爬虫文件
要在spiders文件夹中创建爬虫该文件
cd 项目名\项目名\spiders
例:cd scrapy_baidu_035\scrapy_baidu_035\spdiers
创建爬虫文件
scrapy genspider 爬虫文件名 要爬取的网页URL
一般情况不需要添加http,因为老版本会自动拼接,现在的新版本的话写不写都无所谓
例:lscrapy genspider baidu http://www.baidu.com
3. 运行爬虫代码
使用下面的命令运行
scrapy crawl 爬虫的名字
例如:scrapy crawl baidu
会得到如下的结果:
D:\IDE\PyCharmIDE\PaChong\scrapy_baidu_035\scrapy_baidu_035\spiders>scrapy crawl baidu
2024-03-06 19:34:07 [scrapy.utils.log] INFO: Scrapy 2.9.0 started (bot: scrapy_baidu_035)
2024-03-06 19:34:07 [scrapy.utils.log] INFO: Versions: lxml 5.1.0.0, libxml2 2.10.3, cssselect 1.2.0, parsel 1.8.1, w3lib 2.1.2, Twisted 23.8.0, Python 3.7.5 (tags/v3.7.5:5c02a39a0b, Oct 15 2019, 00:11:34) [MSC v.1916 64 bit (AMD64)], pyOpenSSL 24.0.0 (OpenSSL 3.2.1 30 Jan 2024), cryptography 42.0.5, Platform Windows-10-10.0.22621-SP0
2024-03-06 19:34:07 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'scrapy_baidu_035',
'FEED_EXPORT_ENCODING': 'utf-8',
'NEWSPIDER_MODULE': 'scrapy_baidu_035.spiders',
'REQUEST_FINGERPRINTER_IMPLEMENTATION': '2.7',
'ROBOTSTXT_OBEY': True,
'SPIDER_MODULES': ['scrapy_baidu_035.spiders'],
'TWISTED_REACTOR': 'twisted.internet.asyncioreactor.AsyncioSelectorReactor'}
2024-03-06 19:34:07 [asyncio] DEBUG: Using selector: SelectSelector
2024-03-06 19:34:07 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.asyncioreactor.AsyncioSelectorReactor
2024-03-06 19:34:07 [scrapy.utils.log] DEBUG: Using asyncio event loop: asyncio.windows_events._WindowsSelectorEventLoop
2024-03-06 19:34:07 [scrapy.extensions.telnet] INFO: Telnet Password: 2cb4a6d0f36f3ad4
2024-03-06 19:34:07 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2024-03-06 19:34:07 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2024-03-06 19:34:07 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2024-03-06 19:34:07 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2024-03-06 19:34:07 [scrapy.core.engine] INFO: Spider opened
2024-03-06 19:34:07 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2024-03-06 19:34:07 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
Traceback (most recent call last):
File "d:\python\python375\lib\runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "d:\python\python375\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "D:\Python\python375\Scripts\scrapy.exe\__main__.py", line 7, in <module>
File "d:\python\python375\lib\site-packages\scrapy\cmdline.py", line 158, in execute
_run_print_help(parser, _run_command, cmd, args, opts)
File "d:\python\python375\lib\site-packages\scrapy\cmdline.py", line 111, in _run_print_help
func(*a, **kw)
File "d:\python\python375\lib\site-packages\scrapy\cmdline.py", line 166, in _run_command
cmd.run(args, opts)
File "d:\python\python375\lib\site-packages\scrapy\commands\crawl.py", line 30, in run
self.crawler_process.start()
File "d:\python\python375\lib\site-packages\scrapy\crawler.py", line 383, in start
install_shutdown_handlers(self._signal_shutdown)
File "d:\python\python375\lib\site-packages\scrapy\utils\ossignal.py", line 19, in install_shutdown_handlers
reactor._handleSignals()
AttributeError: 'AsyncioSelectorReactor' object has no attribute '_handleSignals'
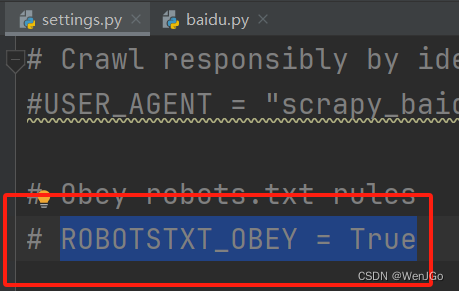
这里会有一个君子条约,也是robots.txt协议,就是各大厂商之间说好不要来爬我。
但是这既然是君子协议,只能说,防君子,不防我们
到setting.py文件夹中将 ROBOTSTXT_OBEY = True 注释掉
你以为这就结束了吗???
其实我还遇到了一个问题就是你没发现我的控制台其实是报错了吗?
这里报错了一个关键信息
'AsyncioSelectorReactor' object has no attribute '_handleSignals'
那么根据意思来说应该是twisted的问题了
然后我没在国内网站发现这种问题,但是在国外的网站发现了
他们也是twised版本和我的一样是23.8.0,好像新版本就会有这个错误,于是我就重新下载了twised22.10.0就完美解决了
pip install twisted==22.10.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
示例代码:
baidu.py
import scrapy
class BaiduSpider(scrapy.Spider):
# 爬虫的名字 用于运行爬虫的时候 使用的值
name = "baidu"
# 允许访问的域名
allowed_domains = ["www.baidu.com"]
# 起始的URL地址 指的是第一次要访问的域名
# start_urls是在allowed_domains前面加了个http://
start_urls = ["http://www.baidu.com"]
# 这个方法是执行了 start_urls 之后执行的方法
# response 就是返回的那个对象
# 相当于 response = urllib.request.urlopen()
# 相当于 response = requests.get()
def parse(self, response):
print('呀啦嗦~~~')
2024-03-06 19:55:40 [scrapy.utils.log] INFO: Scrapy 2.9.0 started (bot: scrapy_baidu_035)
2024-03-06 19:55:40 [scrapy.utils.log] INFO: Versions: lxml 5.1.0.0, libxml2 2.10.3, cssselect 1.2.0, parsel 1.8.1, w3lib 2.1.2, Twisted 22.10.0, Python 3.7.5 (tags/v3.7.5:5c02a39a0b, Oct 15 2019, 00:11:34) [MSC v.1916 64 bit (AMD64)], pyOpenSSL 24.0.0 (OpenSSL 3.2.1 30 Jan 2024), cryptography 42.0.5, Platform Windows-10-10.0.22621-SP0
2024-03-06 19:55:40 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'scrapy_baidu_035',
'FEED_EXPORT_ENCODING': 'utf-8',
'NEWSPIDER_MODULE': 'scrapy_baidu_035.spiders',
'REQUEST_FINGERPRINTER_IMPLEMENTATION': '2.7',
'SPIDER_MODULES': ['scrapy_baidu_035.spiders'],
'TWISTED_REACTOR': 'twisted.internet.asyncioreactor.AsyncioSelectorReactor'}
2024-03-06 19:55:40 [asyncio] DEBUG: Using selector: SelectSelector
2024-03-06 19:55:40 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.asyncioreactor.AsyncioSelectorReactor
2024-03-06 19:55:40 [scrapy.utils.log] DEBUG: Using asyncio event loop: asyncio.windows_events._WindowsSelectorEventLoop
2024-03-06 19:55:40 [scrapy.extensions.telnet] INFO: Telnet Password: b693b5321c5ecc67
2024-03-06 19:55:40 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2024-03-06 19:55:40 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2024-03-06 19:55:40 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2024-03-06 19:55:40 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2024-03-06 19:55:40 [scrapy.core.engine] INFO: Spider opened
2024-03-06 19:55:40 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2024-03-06 19:55:40 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2024-03-06 19:55:41 [urllib3.connectionpool] DEBUG: Starting new HTTPS connection (1): publicsuffix.org:443
2024-03-06 19:55:41 [urllib3.connectionpool] DEBUG: https://publicsuffix.org:443 "GET /list/public_suffix_list.dat HTTP/1.1" 200 85094
2024-03-06 19:55:42 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.baidu.com> (referer: None)
呀啦嗦~~~
2024-03-06 19:55:42 [scrapy.core.engine] INFO: Closing spider (finished)
2024-03-06 19:55:42 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 213,
'downloader/request_count': 1,
'downloader/request_method_count/GET': 1,
'downloader/response_bytes': 1476,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'elapsed_time_seconds': 1.397776,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2024, 3, 6, 11, 55, 42, 334492),
'httpcompression/response_bytes': 2381,
'httpcompression/response_count': 1,
'log_count/DEBUG': 6,
'log_count/INFO': 10,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2024, 3, 6, 11, 55, 40, 936716)}
2024-03-06 19:55:42 [scrapy.core.engine] INFO: Spider closed (finished)
打印出来内容了,直接拿下!!!
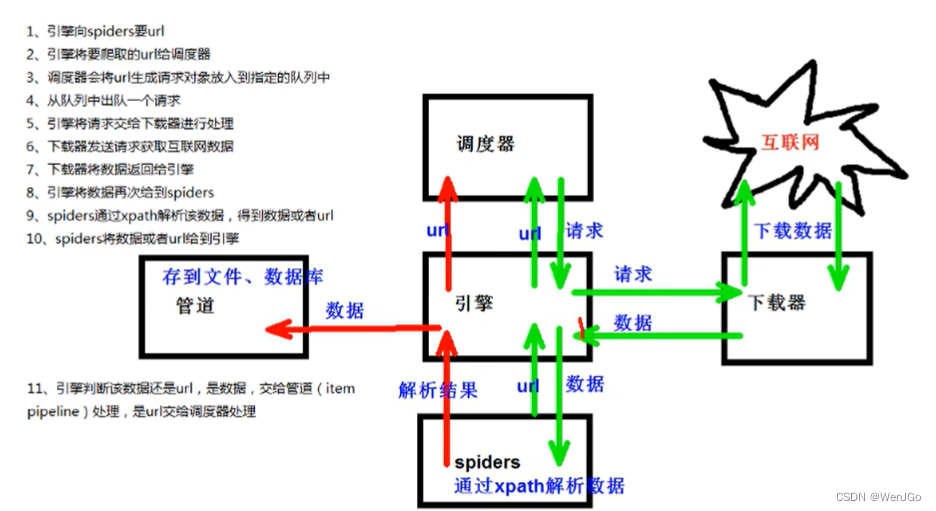
scrapy项目组成
以下两幅图片来自尚硅谷老师的视频截图


scrapy工作原理
下图来自尚硅谷课程笔记
58同城
scrapy genspider tc58 https://hrb.58.com/quanzhizhaopin/?key=%E5%89%8D%E6%AE%B5%E5%BC%80%E5%8F%91&cmcskey=%E5%89%8D%E6%AE%B5%E5%BC%80%E5%8F%91&final=1&jump=1&specialtype=gls&classpolicy=LBGguide_A%2Cmain_B%2Cjob_B%2Chitword_false%2Cuuid_KJEE4RCEzrJtecR7yhjmfd2jZkSzNA2Q%2Cdisplocalid_202%2Cfrom_main%2Cto_jump%2Ctradeline_job%2Cclassify_C&search_uuid=KJEE4RCEzrJtecR7yhjmfd2jZkSzNA2Q&search_type=input
这里运行之后会报错

这个是所无谓的,这是因为URL里面的接口的问题
tc58.py
import scrapy
class Tc58Spider(scrapy.Spider):
name = "tc58"
allowed_domains = ["hrb.58.com"]
start_urls = ["https://hrb.58.com/quanzhizhaopin/?key=%E5%89%8D%E6%AE%B5%E5%BC%80%E5%8F%91"]
def parse(self, response):
print('黑龙江哈尔滨......')然后试着运行一下
报错,发现是robots没修改

咱们去setting.py注释一下
然后再运行,拿下了!!!
tc58.py
import scrapy
class Tc58Spider(scrapy.Spider):
name = "tc58"
allowed_domains = ["hrb.58.com"]
start_urls = ["https://hrb.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&classpolicy=classify_C%2Cuuid_t8S4CnFXp6yxGb78bTEwtZRX7ktr2nRS&search_uuid=t8S4CnFXp6yxGb78bTEwtZRX7ktr2nRS&search_type=history"]
def parse(self, response):
print('=================执行到这里喽================')
# 字符串
# content = response.text
# 二进制
# content = response.body
# print(content)
all_work = response.xpath('//div[@id="selectbar"]//dd//a[@class="select"]')[0]
print(all_work)
print('------')
print(all_work.extract())
scrapy架构组成

汽车之家
当你的请求接口的后缀是html,那么最后不要加 " / "
import scrapy
class CarSpider(scrapy.Spider):
name = 'car'
allowed_domains = ['https://car.autohome.com.cn/price/brand-33.html']
start_urls = ['https://car.autohome.com.cn/price/brand-33.html']
def parse(self, response):
print("=================在这里!==================")
name_list = response.xpath('//div[@class="main-title"]/a/text()')
price_list = response.xpath('//span[@class="lever-price red"]/span[@class="font-arial"]/text()')
for i in range(len(name_list)):
name = name_list[i].extract()
price = price_list[i].extract()
print(name + " " + price)
总结
累了,这个安装安的我头皮发麻!!!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











