






1、自然语言处理发展历史
图1 自然语言处理发展历史
1.1兴起时期
大多数人认为,自然语言处理的研究兴起于1950年前后。在二战中,破解纳粹德国的恩尼格玛密码成为盟军对抗纳粹的重要战场。经过二战的洗礼,曾经参与过密码破译的香农和图灵等科学家开始思考自然语言处理和计算之间的关系。

图2:恩尼格玛密码机
1948年香农把马尔可夫过程模型(Markov Progress)应用于建模自然语言,并提出把热力学中“熵”(Entropy)的概念扩展到自然语言建模领域。香农相信,自然语言跟其他物理世界的信号一样,是具有统计学规律的,通过统计分析可以帮助我们更好地理解自然语言。
1950年,艾伦图灵提出著名的图灵测试,标志着人工智能领域的开端。二战后,受到美苏冷战的影响,美国政府开始重视机器自动翻译的研究工作,以便于随时监视苏联最新的科技进展。1954年美国乔治城大学在一项实验中,成功将约60句的俄文自动翻译成英文,被视为机器翻译可行的开端。自此开始的十年间,政府与企业相继投入大量的资金,用于机器翻译的研究。
1956年,乔姆斯基(Chomsky)提出了“生成式文法”这一大胆猜想,他假设在客观世界存在一套完备的自然语言生成规律,每一句话都遵守这套规律而生成。总结出这个客观规律,人们就掌握了自然语言的奥秘。从此,自然语言的研究就被分为了以语言学为基础的符号主义学派,以及以概率统计为基础的连接主义学派。
1.2符号主义时期
在自然语言处理发展的兴起阶段,大量的研究工作都聚焦从语言学角度,分析自然语言的词法、句法等结构信息,并通过总结这些结构之间的规则,达到处理和使用自然语言的目的。这一时期的代表人物就是乔姆斯基和他提出的“生成式文法”。1966年,完全基于规则的对话机器人ELIZA在MIT人工智能实验室诞生了,如 图3 所示。

图3:基于规则的聊天机器人ELIZA
然而同年,ALPAC(Automatic Language Processing Advisory Committee,自动语言处理顾问委员会)提出的一项报告中提出,十年来的机器翻译研究进度缓慢、未达预期。该项报告发布后,机器翻译和自然语言的研究资金大为减缩,自然语言处理和人工智能的研究进入寒冰期。
1960年代发展特别成功的NLP系统包括SHRDLU——一个词汇设限、运作于受限如“积木世界”的一种自然语言系统,以及1964—1966年约瑟夫·维森鲍姆模拟“个人中心治疗”而设计的ELIZA——几乎未运用人类思想和感情的消息,有时候却能呈现令人讶异的类似人之间的交互。“病人”提出的问题超出ELIZA 极小的知识范围之时,可能会得到空泛的回答。例如问题是“我的头痛”,回答是“为什么说你头痛?”
1970年代,程序员开始设计“概念本体论”(conceptual ontologies)的程序,将现实世界的信息,架构成电脑能够理解的资料。实例有MARGIE、SAM、PAM、TaleSpin、QUALM、Politics以及Plot Unit。许多聊天机器人在这一时期写成,包括PARRY 、Racter 以及Jabberwacky 。
1.3连接主义时期
这一时期,统计自然语言处理,机器学习与自然语言处理的结合,推动了自然语言处理向前发展。
1980年,由于计算机技术的发展和算力的提升,个人计算机可以处理更加复杂的计算任务,自然语言处理研究得以复苏,研究人员开始使用统计机器学习方法处理自然语言任务。
起初研究人员尝试使用浅层神经网络,结合少量标注数据的方式训练模型,虽然取得了一定的效果,但是仍然无法让大部分人满意。后来研究者开始使用人工提取自然语言特征的方式,结合简单的统计机器学习算法解决自然语言问题。其实现方式是基于研究者在不同领域总结的经验,将自然语言抽象成一组特征,使用这组特征结合少量标注样本,训练各种统计机器学习模型(如支持向量机、决策树、随机森林、概率图模型等),完成不同的自然语言任务。
由于这种方式基于大量领域专家经验积累(如解决一个情感分析任务,那么一个很重要的特征就是是否有命中情感词表),以及传统计机器学习简单、鲁棒性强的特点,这个时期神经网络技术被大部分人所遗忘。
1.4深度学习时期
从2006年深度神经网络反向传播算法的提出开始,伴随着互联网的爆炸式发展和计算机(特别是GPU)算力的进一步提高,人们不再依赖语言学知识和有限的标注数据,自然语言处理领域迈入了深度学习时代。
基于互联海量数据,并结合深度神经网络的强大拟合能力,人们可以非常轻松地应对各种自然语言处理问题。越来越多的自然语言处理技术趋于成熟并显现出巨大的商业价值,自然语言处理和人工智能领域的发展进入了鼎盛时期。
自然语言处理的发展经历了多个历史阶段的演进,不同学派之间相互补充促进,共同推动了自然语言处理技术的快速发展。
2、技术发展
NLP技术发展历史
| 年份 | 代表技术 |
| 1948年 | 熵和信息论提出 |
| 1950年 | 图灵测试 |
| 1957年 | RICHARD BELLMAN提出了马尔可夫决策过程 |
| 1982年 | RNN网络 |
| 1993年 | IBM的统计机器翻译模型 |
| 1994年 | 决策树用于词性标注 |
| 1997年 | LSTM网络 |
| 2001年 | 条件随机场CRF理论出现 |
| 2012年 | 谷歌提出知识图谱 |
| 2013年 | google提出词向量模型word2vec |
| 2014年 | GRU网络 Glove词向量模型(斯坦福大学提出) seq2seq模型,为了解决机器翻译问题而设计的,后拓展到了很多任务上面 |
| 2015年 | LSTM+Attention(提出注意力机制) |
| 2016年 | self-Attention模型 |
| 2017年 | 谷歌提出Transfomer,基于Transformer的模型结构成为自然语言处理的主流 |
| 2018年 | 大模型预训练成为主流 GPT ELMO BERT GNN |
| 2019年 | 卡耐基梅隆大学的五位作者和谷歌的一位作者:XLNet Facebook和华盛顿大学:RoBERTa OpenAI:GPT-2 Google:T5 微软:DialoGPT 微软开放域聊天机器人 百度:ERNIE 目前已经迭代了三代,通过建模海量数据中的实体概念等先验语义知识,学习真实世界的语义关系 |
| 2020年 | OpenAI:GPT-3 Facebook(Meta AI):Blenderbot 1/2/3 谷歌:meena 谷歌:ALBERT 轻量级的bert模型 百度:PLATO 系列 |
| 2021年 | 谷歌:Switch Transformer DeepMind:发布预训练模型Gopher 微软、英伟达发布预训练模型Megatron-Turing :该模型是微软的T-NLG(Turing-NLG:2020年微软170亿参数)和英伟达Megatron-LM模型结合的下一代版本 阿里:PLUG/M6 华为&循环智能:盘古 智源研究院:发布超大规模智能模型悟道1.0/2.0 |
| 2022年 | OpenAI:ChatGPT Meta AI :OPT 谷歌:LaMDA 谷歌:PaLM 百度:PLATO-XL |
| 2023年 | 3月14日,Open AI官网发布GPT-4,支持图像和文本输入,效果超越ChatGPT 谷歌:Bard 谷歌:PaLM2 |
| 2024年 | 大模型应用:微软的「Copilot+PC」 |
| OpenAI | GPT系列 |
| | 谷歌:LaMDA 谷歌:PaLM 谷歌:Bard 谷歌:Gemini |
| | Llama-1 [1]是Meta在2023年2月发布的大语言模型 Meta在2023年7月发布了免费可商用版本 Llama-2 2024年4月,Meta正式发布了开源大模型 Llama 3 |
| 百度 | 2019年4月 ERNIE 1 2019年7月 ERNIE 2 2021年7月 ERNIE 3 ERNIE Bot v2.1.0 于 2023年6 月 21, 由ERNIE 3.5提供支持 2023年10月17日 ERNIE 4 |
| 智谱AI | 2021年5月 GLM 2022年8月 GLM-130 2023年3月ChatGLM ChatGLM-130B/ChatGLM-6B(开源) 2023.6.25 ChatGLM2-6B 2023.11.6 ChatGLM3-6B 2024-01-16 GLM-4 |
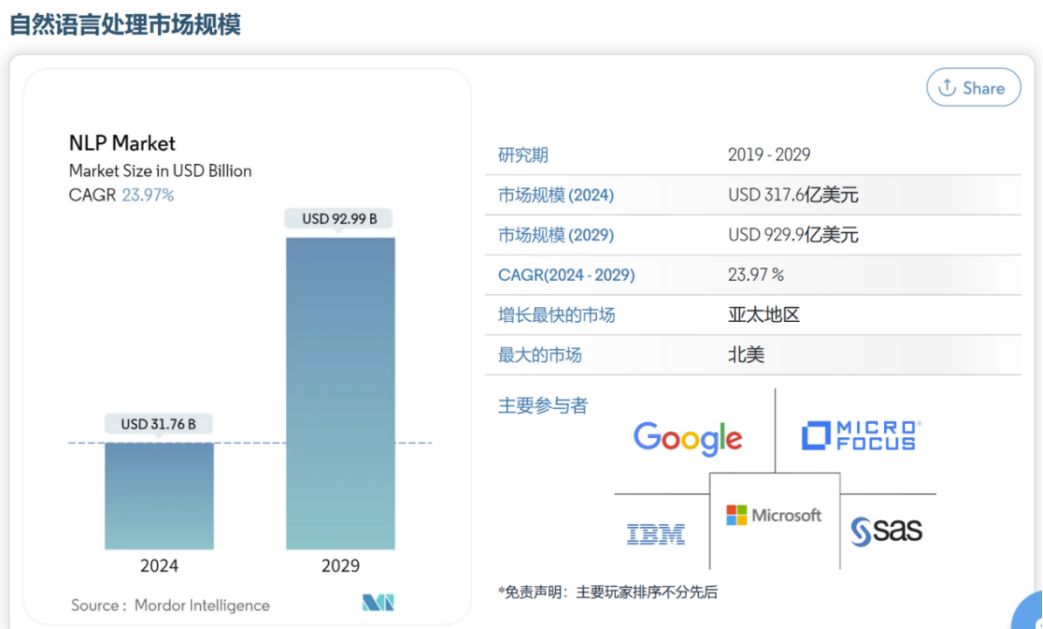
3、市场规模
根据mordor intelligence公司发布的市场研究报告显示,2024年自然语言处理就已经达到千亿人民币的市场规模。
4、典型应用
自然语言处理历史悠久,1950左右起步,到今天70多年的发展时间,其中经历了几个跌宕起伏的时间段,但发展最快的还是最近10年的时间(2013-2024),以词向量和Transfomer模型为代表的核心技术成为自然处理的主流技术,应用在非常多的nlp任务当中。2024年,我们使用一个大模型集成的工具即可实现所有的nlp下游任务。
4.1智能对话系统
4.2文本生成

4,3机器翻译

4.4信息提取



4.5语音识别

5大模型技术
5.1大模型训练原理

5.2典型大模型
2023年是大模型百花齐放的一年,在我国不管是公司,大学还是研究所都相继推出了自家的大模型,但基本都是基于开源大模型做了微调。2024年大模开始进入应用市场,更多的开始卷上层应用了,如果说2023年卷底层大模型,2024年卷上层应用,那么2025年我估计就只剩下那些能够长期坚持去做好大模型底层和应用的公司了。只有坚持长期探索,才能将大模型应用到各个行业,开发出满足市场需求的产品。
GPT

LLaMA

文心一言

ChatGLM

百川大模型

通义千问

星火大模型

书生大模型

5.3大模型部署资源
显卡驱动需要根据实际部署情况确定,以下是根据网络搜集资料得到的大模型部署资源参考,总结一下对GPU的显存要求比较高,其次是CPU的运行内存。
| 大模型 | CPU核心 | 内存 | 硬盘 | 显存 | 显卡数量 | 显卡驱动 |
| 通义千问-72B | 96C | 128G | 600G | 144G | 2*A100-80G | CUDA 12.0 |
| ChatGLM3-6B | 32C | 至少32G | 100G | 至少16G |
| CUDA 12.0 |
| 百川2-13B | 32C | 64G | 100G | 30G | 1*A100-40G | CUDA 12.0 |
5.4大模型应用
- 金融大模型:以自然语言为入口,搭建一个投资分析顾问型的金融大模型。
- 智慧教育:大模型问答老师
- 机器人+大模型
6、自然语言处理公司
市场概况
IT桔子2024年5月22日数据显示:自然语言处理领域共有 578家公司,共 986起投资事件,总投资额为 7136亿人民币。

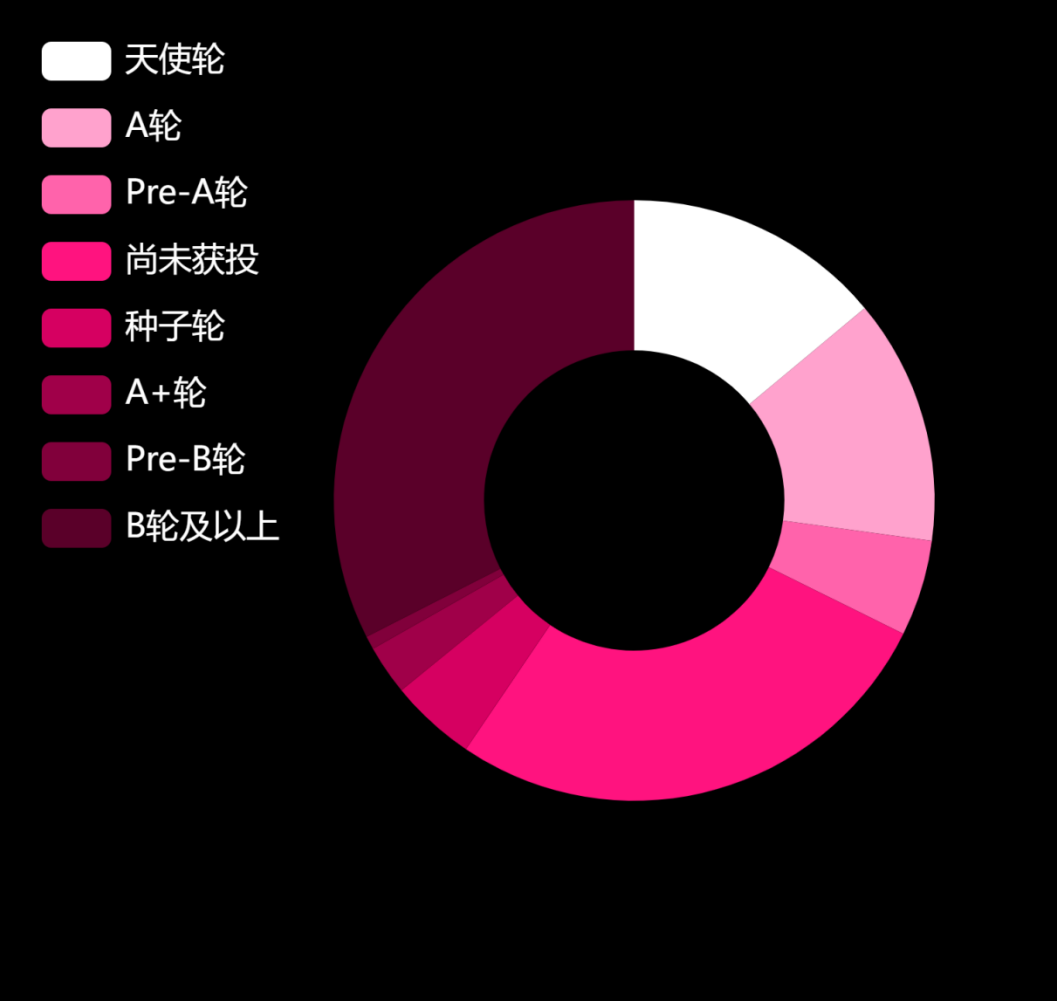
公司领域细分
典型公司代表
百度
科大讯飞
出门问问
达观数据
新AI四小龙
以大模型为核心的自然语言处理公司
智谱AI

MiniMax

月之暗面

百川智能

7、产品发展

8、创业方向

9、ACL会议
1963开始,每年一届,属于自然语言领域技术最前沿的顶级盛会,包括了研究的最新方向。

9、NLP开源项目
NLP开源项目
①百度
paddlenlp
https://www.paddlepaddle.org.cn/paddle/paddlenlp
百度开源的框架目前是处理中文自然语言最全的参考资料了,涵盖了自然语言处理的各个领域
EasyNLP
②阿里巴巴
GitHub - alibaba/EasyNLP: EasyNLP: A Comprehensive and Easy-to-use NLP Toolkit
fastnlp
③复旦大学
④结巴分词
https://github.com/fxsjy/jieba
10、智能合同审阅系统
















 2959
2959











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









