






数据说明
COVID-19阳性病例的胸部X射线图像以及正常和病毒性肺炎图像的数据库。数据库包含有1200个COVID-19阳性图像,1341正常图像和1345病毒性肺炎图像。来自卡塔尔多哈卡塔尔大学和孟加拉国达卡大学的一组研究人员,以及来自巴基斯坦和马来西亚的合作者与医生合作,建立了一个针对COVID-19阳性病例的胸部X射线图像数据库,以及正常和病毒性肺炎图像
数据来源
https://www.heywhale.com/mw/dataset/6027caee891f960015c863d7
导入包
import os
import math
import zipfile
import random
import json
import cv2
import numpy as np
from PIL import Image
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph import Linear,Conv2D,Pool2D
import matplotlib.pyplot as plt
paddle.enable_static() #转换为静态图save_path='save_model'
#从模型中得到预测程序,输入数据名称列表和分类器
[infer_program,feeded_var_names,target_var]=fluid.io.load_inference_model(dirname=save_path,executor=exe)
#一些参数的设置
configs = {
"input_size": [3, 1024,1024], #输入图片的shape
"class_dim":3, #分类数
'src_path':'data/data82373/input_data.rar', #数据的路径
'train_path':'input_data', #解压路径
'model_save_dir':'save_model', # 模型保存路径
'learning_rate':0.001, #学习率
'batch_size':32, #批次大小
'epoch':10 #学习次数
}加载保存在"save_model"文件夹中的预测程序(infer_program)、输入数据名称列表(feeded_var_names)和分类器(target_var),这些是使用PaddlePaddle训练的模型所需的基本参数
下面的就是一些配置信息,包括输入图片的尺寸(input_size)、分类数(class_dim)、数据文件的路径(src_path)、数据解压路径(train_path)、模型保存路径(model_save_dir)、学习率(learning_rate)、批次大小(batch_size)和训练次数(epoch)。
预处理
#预处理图片,获取训练和测试的数据集
COVID =[] #新冠肺炎患者的胸透图片
COVID_label = []
NORMAL = [] #正常人的胸透图片
NORMAL_label = []
Viral_Pneumonia = [] #病毒性肺炎患者的胸透图片
Viral_Pneumonia_label = []
# 获取所以图片的路径名
# 对应的列表中,同时贴上标签,存放到label列表中
def get_files(file_path, ratio):
for file in os.listdir(file_path + '/COVID'):
COVID.append(file_path + '/COVID' + '/' + file)
COVID_label.append(0) # 0为新冠肺炎患者
for file in os.listdir(file_path + '/NORMAL'):
NORMAL.append(file_path + '/NORMAL' + '/' + file)
NORMAL_label.append(1) # 1为正常人
for file in os.listdir(file_path + '/Viral_Pneumonia'):
Viral_Pneumonia.append(file_path + '/Viral_Pneumonia' + '/' + file)
Viral_Pneumonia_label.append(2) # 2为病毒性肺炎患者
#检测是否读取成功
for i in range(1):
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
img = plt.imread(NORMAL[i+5])
plt.title('图片的类型是:'+str(NORMAL_label[i+5]))
plt.imshow(img)
plt.show()
#将新路径的图片进行打乱处理
image_list = np.hstack((COVID, NORMAL, Viral_Pneumonia))
label_list = np.hstack((COVID_label, NORMAL_label, Viral_Pneumonia_label))
# 利用shuffle打乱顺序
temp = np.array([image_list, label_list])
temp = temp.transpose()
np.random.shuffle(temp)
# 将所有的img和lab转换成list
all_image_list = list(temp[:, 0])
all_label_list = list(temp[:, 1])
# 将所得List分为两部分,一部分用来训练tra,一部分用来测试val
# ratio是测试集的比例,看情况填入0-1的一个小数
n_sample = len(all_label_list)
n_val = int(math.ceil(n_sample * ratio)) # 测试样本数
n_train = n_sample - n_val # 训练样本数
tra_images = all_image_list[0:n_train]
tra_labels = all_label_list[0:n_train]
tra_labels = [int(float(i)) for i in tra_labels]
val_images = all_image_list[n_train:-1]
val_labels = all_label_list[n_train:-1]
val_labels = [int(float(i)) for i in val_labels]
return tra_images, tra_labels, val_images, val_labels
#这段代码用于预处理图片数据,获取训练集和测试集的数据
首先定义了四个空列表`COVID`、`COVID_label`、`NORMAL`、`NORMAL_label`和`Viral_Pneumonia`、`Viral_Pneumonia_label`,分别用于存放新冠肺炎患者、正常人和病毒性肺炎患者的胸透图片路径和对应的标签。
`get_files()`函数用于获取所有图片的路径名,并将路径名和对应的标签存放到各个列表中。函数首先遍历文件夹中的所有图片文件,将文件的路径和标签存放到对应的列表中。接下来,使用Matplotlib库展示一个正常人的胸透图片,并打印出标签。
然后,将三个图片路径列表和标签列表合并成一个大数组`image_list`和`label_list`。之后,将图片路径和标签列表进行随机打乱,保证训练集和测试集的数据随机性。最后,将打乱后的列表分割成训练集和测试集,并返回训练集和测试集的图片路径和标签列表。其中,参数`file_path`是图片文件夹的路径,`ratio`是测试集所占比例。
读取数据函数
def data_reader(images,labels):
'''
自定义data_reader
'''
def reader():
for item in range(len(images)):
img_path = images[item]
lab = labels[item]
img = cv2.imread(img_path)
img = np.resize(img,(3,256,256))
img = np.array(img).reshape(3,256,256).astype('float32') #要reshape一下,因为输入数据的格式是[256,256,3],而paddle接受数据格式是[3,256,256]
img = img/255.0
yield img, int(lab)
return readerdata_reader函数是一个自定义的数据读取器,用于读取训练数据。它接收两个参数:images和labels,分别是训练集的图片路径和标签列表。在函数内部,使用一个生成器reader来逐个读取图片和对应的标签。对于每个图片,首先使用OpenCV库的cv2.imread()函数读取图片,并将图片的大小调整为(3, 256, 256)。然后将图片转换为float32类型,并进行归一化处理,将像素值缩放到0-1的范围内。最后,使用yield关键字将处理后的图片和对应的标签返回
定义训练模型
def CNN_model(tra_images):
# 第一个卷积-池化层
conv_pool_1 = fluid.nets.simple_img_conv_pool(
input=tra_images, # 输入图像
filter_size=5, # 滤波器的大小
num_filters=20, # filter 的数量。它与输出的通道相同
pool_size=2, # 池化核大小2*2
pool_stride=2, # 池化步长
act="relu") # 激活类型
conv_pool_1 = fluid.layers.batch_norm(conv_pool_1)
# 第二个卷积-池化层
conv_pool_2 = fluid.nets.simple_img_conv_pool(
input=conv_pool_1,
filter_size=5,
num_filters=50,
pool_size=2,
pool_stride=2,
act="relu")
conv_pool_2 = fluid.layers.batch_norm(conv_pool_2)
# 第三个卷积-池化层
conv_pool_3 = fluid.nets.simple_img_conv_pool(
input=conv_pool_2,
filter_size=5,
num_filters=50,
pool_size=2,
pool_stride=2,
act="relu")
# 以softmax为激活函数的全连接输出层,因为是分成三类,所以size是三
prediction = fluid.layers.fc(input=conv_pool_3, size=3, act='softmax')
return predictionCNN_model函数定义了一个简单的卷积神经网络模型。它接收一个名为tra_images的输入变量,代表训练集的图片。首先,通过fluid.nets.simple_img_conv_pool()函数定义了三个卷积-池化层的网络结构,每个卷积-池化层都使用了ReLU激活函数和批归一化操作。然后,通过fluid.layers.fc()函数定义一个以Softmax为激活函数的全连接输出层,输出的大小设置为3,因为这个模型是用来分类三类图片。这两个函数通常用于图像分类任务的训练和预测。
获取损失函数和准确率
data_shape = [3,256,256]
tra_images = fluid.layers.data(name='image', shape=data_shape, dtype='float32')
label = fluid.layers.data(name='label', shape=[1], dtype='int64')
# 获取分类器,用cnn进行分类
#model = paddle.vision.models.resnet50(pretrained=True,num_classes=3)
#predict = model(tra_images)
predict = CNN_model(tra_images)
print(np.shape(predict))
# 获取损失函数和准确率
cost = fluid.layers.cross_entropy(input=predict, label=label) # 交叉熵
avg_cost = fluid.layers.mean(cost) # 计算cost中所有元素的平均值
acc = fluid.layers.accuracy(input=predict, label=label) #使用输入和标签计算准确率
# 定义优化方法
optimizer =fluid.optimizer.Adam(learning_rate=configs['learning_rate'])
optimizer.minimize(avg_cost)
print("完成")构建一个使用CNN进行分类的模型,并定义损失函数和优化方法。
首先,定义了输入`tra_images`为一个三通道、256x256大小的图像数据,类型为float32。标签`label`为一个大小为1的整数。
在深度学习模型中,使用了`CNN_model`作为分类器,将输入`tra_images`作为模型输入,得到输出`predict`。
接下来,计算损失函数和准确率。使用交叉熵作为损失函数,将模型的输出`predict`和真实标签`label`作为输入。`avg_cost`是计算损失函数`cost`中所有元素的平均值。`acc`利用模型输出和真实标签计算分类准确率。
定义数据读取
feeder = fluid.DataFeeder(feed_list=[tra_images, label],place=place)
all_train_iter=0
all_train_iters=[]
all_train_costs=[]
all_train_accs=[]
#定义数据读取
data_shape = configs['input_size']
train_image, train_label, val_image, val_label =get_files(configs['train_path'], 0.8)
print(type(train_image[0]))
train_reader = paddle.batch(data_reader(train_image,train_label),
batch_size=configs['batch_size'],
drop_last=True)
eval_reader = paddle.batch(data_reader(val_image,val_label),
batch_size=configs['batch_size'],
drop_last=True)
test_reader = paddle.batch(data_reader(val_image,val_label),
batch_size=1,
drop_last=True)创建了一个`DataFeeder`对象`feeder`,用于将数据输入模型中进行训练或预测。`feed_list`参数指定了要将数据输入到哪些变量中,这里包括`tra_images`和`label`两个变量。`place`参数指定了数据的存放位置。接下来,定义了一些用于记录训练过程中的指标的变量,包括`all_train_iter`、`all_train_iters`、`all_train_costs`和`all_train_accs`。然后,根据配置文件中指定的输入尺寸`data_shape`,调用`get_files()`函数获取训练集和验证集的图片路径和标签。接下来,使用`paddle.batch()`函数将训练集和验证集的图片和标签进行批量读取。
label_list = ['新冠肺炎患者','正常人','病毒性肺炎患者']
for j in range(len(val_image)):
for batch_id, data in enumerate(eval_reader()):
results = exe.run(program=test_program, #运行预测程序
feed=feeder.feed(data), #喂入要预测的img
fetch_list=predict) #得到推测结果
#print(results)
results_list = results[0].tolist()
#print(results_list)
for i in range(len(results_list)):
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文
plt.rcParams['axes.unicode_minus'] = False
img = plt.imread(val_image[i])
plt.title('图片的类型是:'+str(val_label[i]))
plt.imshow(img)
plt.show()
predict_result=label_list[np.argmax(results_list[i])]
print("预测结果为: \n", predict_result)
print('------------------------------------')
if i ==5: #根据自己想查看多少张,可以修改这个i的值
break
break
break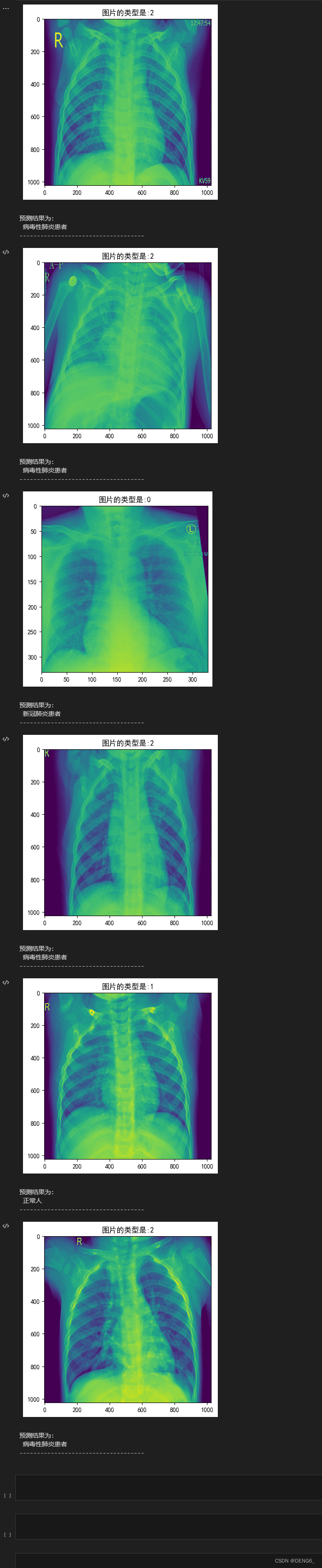
通过一个双重循环,外层循环遍历`val_image`列表(即验证集的图片路径),内层循环通过`enumerate(eval_reader())`逐批次提取验证集数据。在每个批次中,使用`exe.run()`函数运行预测程序,其中`feed`参数传入`feeder.feed(data)`,将验证集数据喂入模型进行预测。`fetch_list`参数指定了需要获取的结果,这里是`predict`,即推测结果。接下来,将预测结果转换成列表形式,并将每个结果的最大值索引转换为对应的标签。然后,通过`plt`模块展示该图片的类型和预测结果。最后,判断如果`i`等于5(这里限制展示5张图片),则跳出内层循环,继续外层循环,展示下一张图片。最外层的两个`break`语句用于在展示了5张图片后直接结束整个预测过程。
QQ录屏20231108141851















 3778
3778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









