






 本文探讨了在COVID-19大流行期间,如何利用深度学习技术改进医学影像分析,尤其是通过ResNet50模型对胸部X光和CT图像进行自动诊断。文章介绍了数据预处理方法、模型训练流程和评估指标,展示了人工智能在快速、准确诊断及疫情管理中的潜力。
本文探讨了在COVID-19大流行期间,如何利用深度学习技术改进医学影像分析,尤其是通过ResNet50模型对胸部X光和CT图像进行自动诊断。文章介绍了数据预处理方法、模型训练流程和评估指标,展示了人工智能在快速、准确诊断及疫情管理中的潜力。
一、绪论
新冠肺炎(COVID-19),由严重急性呼吸综合征冠状病毒2型(SARS-CoV-2)引起,自2019年底首次在中国武汉爆发以来,迅速蔓延至全球,成为一场影响深远的全球性大流行病。
在这场疫情中,快速、准确地诊断新冠肺炎患者,对于控制疫情的蔓延、减轻医疗系统的压力、及时治疗患者至关重要。传统的诊断方法主要依赖于病毒核酸检测,如逆转录聚合酶链反应(RT-PCR)测试,但这些方法存在检测周期长、资源有限和假阴性率较高等问题。因此,医学影像,特别是胸部X光和计算机断层扫描(CT)成像,成为了辅助诊断新冠肺炎的重要手段。通过影像学检查,医生可以观察到肺部的典型病变,如地图样改变、毛玻璃影和肺实质的炎症渗透,这些特征有助于快速筛查和诊断新冠肺炎患者。
随着人工智能技术的快速发展,基于深度学习的图像分类任务在医学影像分析领域显示出了巨大的潜力。利用深度学习模型,可以自动学习和提取影像数据中的复杂特征,实现对新冠肺炎等疾病的高效、准确诊断。在新冠肺炎疫情期间,研究人员和医生尝试使用深度学习模型对胸部X光和CT影像进行分析,以自动检测和分类新冠肺炎病例,这不仅可以加快诊断速度,还可以减轻医务人员的工作负担,提高诊断的准确性和效率。
新冠肺炎图像分类任务的目标是开发出能够自动识别和分类医学影像中新冠肺炎特征的深度学习模型。这项任务通常涉及收集和预处理大量的胸部X光或CT影像数据,设计和训练深度神经网络模型,以及评估模型的性能。成功的模型可以帮助医生快速筛选出疑似新冠肺炎患者,为进一步的诊断和治疗提供重要信息。此外,这些模型还可以应用于疫情监测和管理,为公共卫生决策提供数据支持,对抗击新冠肺炎疫情具有重要意义。
二、项目完整地址
三、实验数据
数据集来自kaggle:Covid-19 Image Dataset (kaggle.com)
四、部分参考代码
from torchvision import transforms
import os
from torchvision import datasets
import numpy as np
from torch.utils.data import DataLoader
from torchvision import models
import torch.optim as optim
import torch.nn as nn
import torch
import tqdm
from torch.optim import lr_scheduler
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import accuracy_score
from sklearn.metrics import f1_score
from sklearn.metrics import roc_auc_score
import pandas as pd
import time
# 训练集图像预处理:缩放裁剪、图像增强、转 Tensor、归一化
train_transform = transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 测试集图像预处理-RCTN:缩放、裁剪、转 Tensor、归一化
test_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
def train_one_batch(images, labels):
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
# 优化更新权重
optimizer.zero_grad()
loss.backward()
optimizer.step()
_, preds = torch.max(outputs, 1)
preds = preds.cpu().numpy()
loss = loss.detach().cpu().numpy()
outputs = outputs.detach().cpu().numpy()
labels = labels.detach().cpu().numpy()
# 计算分类评估指标
train_loss = loss
train_accuracy = accuracy_score(labels, preds)
train_precision = precision_score(labels, preds, average='macro')
# train_recall = recall_score(labels, preds, average='macro')
# train_f1 = f1_score(labels, preds, average='macro')
print(f"train_loss:{train_loss}", f"train_acc:{train_accuracy}", f"train_pre:{train_precision}")
# return log_train
def evaluate_testset():
loss_list = []
labels_list = []
preds_list = []
with torch.no_grad():
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, preds = torch.max(outputs, 1)
preds = preds.cpu().numpy()
loss = criterion(outputs, labels)
loss = loss.detach().cpu().numpy()
outputs = outputs.detach().cpu().numpy()
labels = labels.detach().cpu().numpy()
loss_list.append(loss)
labels_list.extend(labels)
preds_list.extend(preds)
# 计算分类评估指标
test_loss = np.mean(loss_list)
test_accuracy = accuracy_score(labels_list, preds_list)
test_precision = precision_score(labels_list, preds_list, average='macro')
test_recall = recall_score(labels_list, preds_list, average='macro')
# test_f1 = f1_score(labels_list, preds_list, average='macro')
print(f"test_loss:{test_loss}", f"test_acc:{test_accuracy}",
f"test_pre:{test_precision}",f"test_recall:{test_recall}")
if __name__ == "__main__":
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 数据集文件夹路径
dataset_dir = r""
train_path = os.path.join(dataset_dir, 'train')
test_path = os.path.join(dataset_dir, 'test')
# 载入训练集
train_dataset = datasets.ImageFolder(train_path, train_transform)
# 载入测试集
test_dataset = datasets.ImageFolder(test_path, test_transform)
BATCH_SIZE = 32
# 训练集的数据加载器
train_loader = DataLoader(train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4
)
# 测试集的数据加载器
test_loader = DataLoader(test_dataset,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=4
)
model = models.resnet50(pretrained=True) # 载入预训练模型
model.fc = nn.Linear(model.fc.in_features, 3)
optimizer = optim.Adam(model.fc.parameters())
model = model.to(device)
# 交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 学习率降低策略
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5)
# 训练轮次 Epoch
EPOCHS = 1000
best_test_accuracy = 0
for epoch in range(1, EPOCHS + 1):
print(f'Epoch {epoch}/{EPOCHS}')
## 训练阶段
model.train()
for images, labels in train_loader:
train_one_batch(images, labels)
lr_scheduler.step()
## 测试阶段
model.eval()
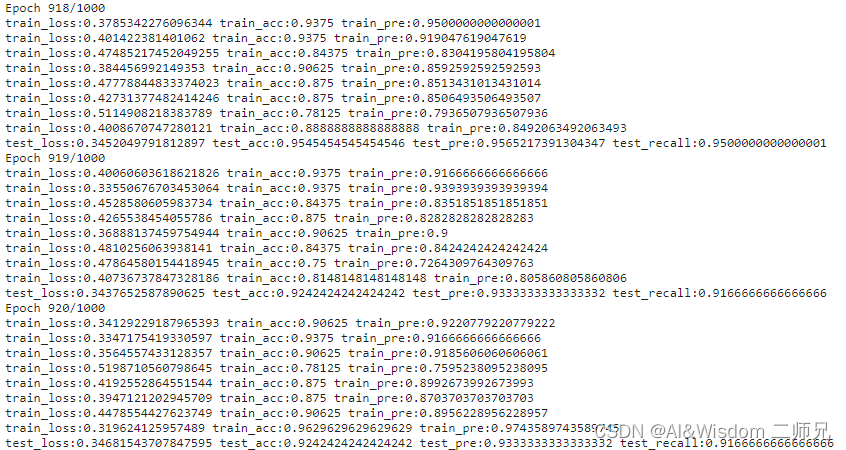
evaluate_testset()五、实验结果

















 1132
1132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









