







如果你是搞人工智能(AI)、机器学习(ML)或者深度学习(DL)的AI创业公司、开发者、研究人员或者爱好者,你肯定知道拥有一个强大可靠的 GPU 来处理这些应用所需的复杂计算有多重要。不过由于英伟达(NVIDIA)在国内很难购买,并且会有较高的价格,所以租用 GPU 云服务成为大多数公司和个人开发者获得GPU算力的最便利方式(比如DigitalOcean的H100 GPU Droplet云服务器)。
我们曾经写过一篇博客讲“什么GPU适合做模型训练,什么GPU适合做推理”,也讲过“怎么去最大限度利用GPU的算力资源”。在本文中,我们将比较 NVIDIA 四款最先进、性能最高的GPU:A100、L40s、H100和H200。我们会看看每款GPU的关键规格、特点和性能,比较它们在各种基准测试和指标上的表现,并提供一些建议,告诉你根据你的需求,哪款GPU最适合机器学习,应该选择哪一款。
几款 NIVIDIA GPU 的规格
英伟达生产多款适用于多种工作负载的顶级GPU,比如游戏和高级AI/ML工作负载。这一部分简要比较了他们的四款型号:A100、L40s、H100和H200。
英伟达A100 Tensor Core GPU:随着Ampere架构的推出,A100是一款多功能GPU,专为广泛的数据中心应用设计,平衡了性能和灵活性。

英伟达L40S GPU:L40s是Ada Lovelace架构的一部分,提供了开创性的特性和性能能力,将AI和ML场景的性能和表现提升到一个新的水平。

英伟达H100 Tensor Core GPU:H100采用了Hopper架构,推动了GPU性能的极限,针对最苛刻的AI和ML应用而设计。

英伟达GH200 Grace Hopper Superchip:GH200有望成为英伟达最先进的GPU,核心数量、内存和带宽都有显著提升。

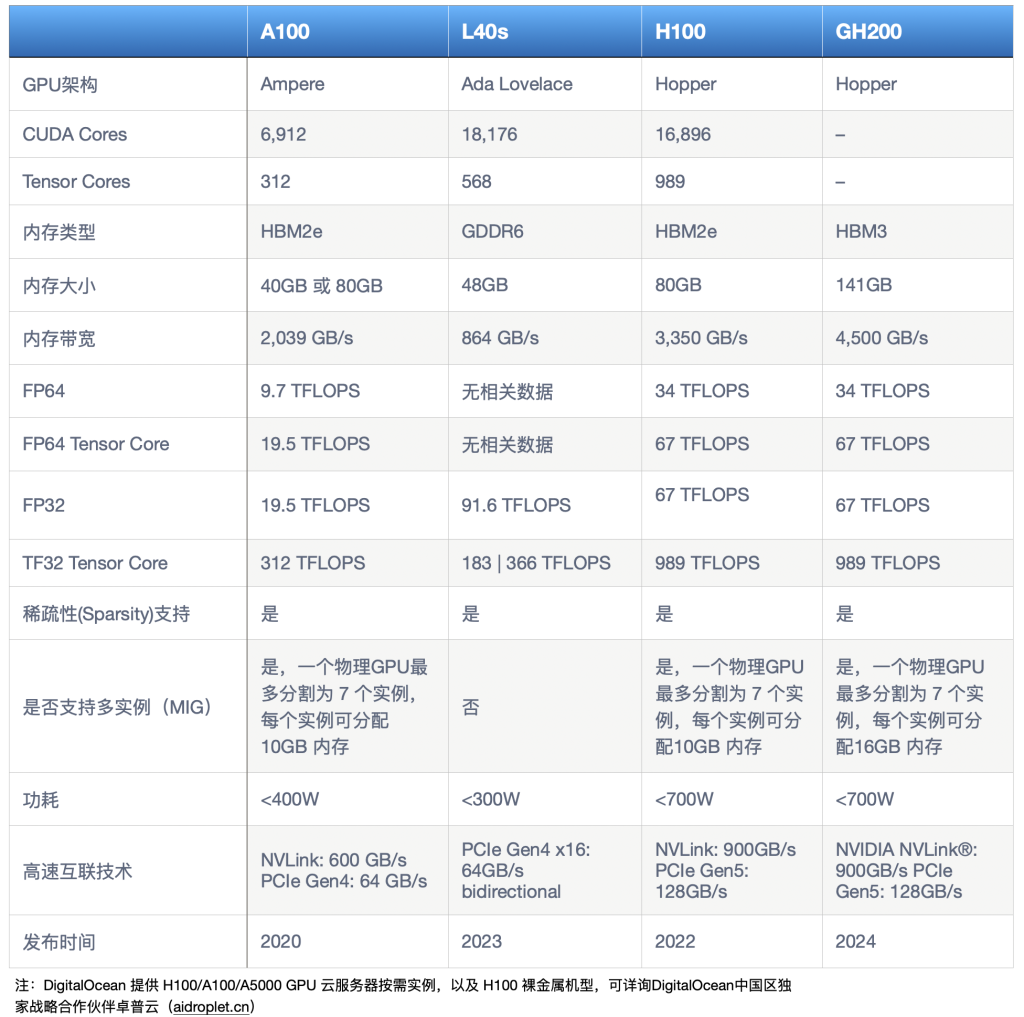
下面是每款 GPU 主要规格特点的数据表:
虽然我们本文是对比主要对比这四款 GPU,但大家也需要关注英伟达最近在其产品线中发布的更新型号,比如GeForce RTX 4070 Ti SUPER、NVIDIA Blackwell,以及即将推出的 RTX 50 系列 GPU。根据 12 月 14 号的媒体消息称,英伟达 GeForce RTX 50 系列显卡性能最高增幅超过 70%。
那么表格中这些数字背后,对用户来说意味着什么差异?我们来看一看:
CUDA核心和Tensor核心
这些英伟达 GPU 的核心数量在并行处理能力方面非常重要。CUDA 核心是通用处理器,负责处理标准的计算任务,而 Tensor 核心专门用于加速机器学习和 AI 工作负载。GPU 拥有这些核心越多,它就能同时执行越多的并行计算——这能更好地满足要求较高的 AI 和机器学习应用。英伟达 H100、H200 以及 L40 GPU 拥有更高的CUDA和 Tensor 核心数量,与A100相比,能够实现更快的并行处理,性能提升与工作负载的并行性成比例。这意味着这些后续型号在能够利用增加的并行性的应用中实现了更优越的性能,比如训练大型语言模型、运行复杂模拟和处理大规模数据集。
内存类型和大小
GPU 的内存类型、大小和速度决定了它能够最优支持哪些应用。像 HBM (High Bandwidth Memory)这样的更大、更快的选项允许更大的数据集,并最小化瓶颈。
- A100 拥有40 GB 至 80 GB 的 HBM2e 内存,对许多应用来说已经足够,但 H200 的 141 GB HBM3 内存提供了最大和最快的内存,对于数据密集型应用如大规模模拟或使用大规模数据集的深度学习至关重要。
- L40s 配备了带有 ECC(Error-Correcting Code,即错误校正码,是一种用于检测和修正数据传输或者存储过程中发生的错误的编码技术)的GDDR6内存,可能不如 HBM 内存快,但仍然为数据提供了显著的存储空间。
- H100 的内存大小与 A100 相近,也使用 HBM2e,提供了对数据密集型任务有益的高速数据访问。关于H100的内存结构,我们还有过一篇博客文章专门做过介绍。
虽然 A100 的内存适合许多任务,但 H100 特别是 H200 增加的内存容量更适合那些推动当前 GPU 处理极限的数据密集型工作负载。
内存带宽
在内存和处理器核心之间高效传输数据至关重要。更高的带宽意味着潜在的减速减少,特别是对于数据密集型建模,以及数据量巨大的模型训练任务。
- A100的内存带宽为 2,039 GB/s,支持各种应用的高效数据传输,但 H200 的最高内存带宽约为 4,500 GB/s,表明它可以轻松处理最数据密集型的任务,减少潜在的瓶颈并提高整体性能。
- L40s 的带宽最低,约为 846 GB/s,表明它可能比其他 GPU 更少地减少数据传输瓶颈。
H200 和 H100 的高内存带宽使它们在需要快速传输大量数据时优于其他 GPU,尤其是在可能出现数据传输瓶颈的工作负载中,比如与庞大的 AI 模型一起。
稀疏性支持
稀疏性支持跳过稀疏 AI 模型中的零值,使某些工作负载的性能翻倍。(注:在某些AI模型中,尤其是在深度学习模型里,存在大量的参数,其中很多参数的值是零或者接近零。这种模型被称为稀疏模型。所谓的“稀疏性支持”是指在模型的推理或者训练过程中,系统能够识别出这些零值参数,并在计算时跳过它们,从而减少不必要的计算量,提高计算效率。)
- A100 和 L40s 支持稀疏性,但它们在处理涉及稀疏数据的 AI 任务时不如新的 Grace Hopper 架构(如H100和H200)高效。
- H100 和 H200 在运行涉及稀疏数据的 AI 模型时最为高效,有效地使某些 AI 和机器学习任务的性能翻倍。
H100 和 H200 背后的 Hopper 架构提供了最有效的稀疏性处理,使这些更新一代的 GPU 在处理涉及许多零值连接的AI模型的工作负载中表现出色,比如在计算机视觉任务。
MIG 功能
MIG(多实例)功能在处理多个同时任务时提供工作负载灵活性。一般来讲,数据较大的大语言模型的训练,最高效的方式就是采用 MIG。
- A100 的 MIG 功能允许灵活的工作负载管理,但 H100 和 H200 的 MIG 功能在多租户环境(在使用GPU云的时候,比如DigitalOcean GPU Droplet,多个用户共享同一物理资源,同时每个用户的数据和应用都是隔离的),或同时运行多个不同工作负载时提供更好的资源分配和多样性。
- L40s 没有 MIG功能。
性能基准测试
接下来,让我们深入了解英伟达GPU的性能基准测试,以更清晰地了解它们在实际应用场景中的表现。
英伟达A100:A100 经过广泛测试,以其在 AI 和深度学习任务中的显著性能提升而闻名。例如,在语言模型训练中,使用 FP16 Tensor 核心时,A100 的速度大约是 V100 的 1.95 倍到 2.5 倍。它还在OctaneBench(一个用于测试GPU 渲染性能的基准测试工具)上得分446分,声称是当时最快的GPU。
英伟达L40s:据报道,L40s 在 MLPerf 基准测试中发现的各种训练和推理工作负载中提供 A100 级别的 AI 性能。然而,由于总共只有 48GB 的 VRAM,在运行具有显著高参数的大型语言模型时,其性能不如拥有 80GB VRAM 的 A100。它在 Geekbench - OpenCL( Geekbench 软件中的一个测试项目,它专门用来评估 GPU 在 OpenCL 环境中的性能)中的性能比前身提高了 26%。
英伟达H100:H100 系列,特别是 H100 NVL,在计算能力上有着飞跃式的提升,特别是在 FP64 和 FP32 指标上。这款 GPU 针对大语言模型(LLMs)进行了优化,在特定领域超过了 A100,提供了高达 30 倍的更好的推理性能。它还在 MLPerf 3.0 基准测试中通过软件优化展现出了高达 54% 的性能提升。
英伟达H200:初步数据表明,H200 将以其更大、更快的内存能力为生成式 AI 和高性能计算(HPC)工作负载提供超级加速。预计它将为 Llama2 70B 提供比 H100 快 1.9 倍的推理能力,为 GPT-3 175B 提供比 H100 快 1.6倍的推理能力。此外,根据英伟达官方数据,预计它在某些 HPC 应用中的性能将提高 110 倍。
哪款GPU适合你?
最适合你的GPU将取决于你的特定用例、偏好和预算。以下是一些可能帮助你做出决定的参考建议:

写在最后
在本文中,我们详细比较了四款英伟达 GPU——A100、L40s、H100和H200——这四款GPU算是目前关注度最高的四款,它们专为专业、企业级和数据中心应用而设计。我们探讨了这些GPU的架构和技术应用,它们针对计算任务、AI和数据处理进行了优化。也分析了它们的关键指标、特点和性能指标,帮助你了解它们在各种基准测试中的比较情况。
目前,H200 GPU目前还处于量产中,所以预计在明年大家会看到H200的GPU云服务器。大多数的云平台都可提供A100/L40s/H100,例如DigitalOcean的GPU Droplet就提供H100/A100等GPU服务器,其中H100 GPU还提供单一用户专享的裸金属实例,而且价格优惠。如果你希望了解关于H100 GPU Droplet的详细价格折扣与配置,可联系DigitalOcean中国区独家战略合作伙伴卓普云。


















 2288
2288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









